RTI Connext
Core Libraries and Utilities
Getting Started Guide
Version 5.0
This Guide describes how to download and install RTI Connext. It also lays out the core value and concepts behind the product and takes you
RTI Connext
Core Libraries and Utilities
Getting Started Guide
Version 5.0
This Guide describes how to download and install RTI Connext. It also lays out the core value and concepts behind the product and takes you

© 2012
All rights reserved.
Printed in U.S.A. First printing.
August 2012.
Trademarks
Copy and Use Restrictions
No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form (including electronic, mechanical, photocopy, and facsimile) without the prior written permission of Real- Time Innovations, Inc. The software described in this document is furnished under and subject to the RTI software license agreement. The software may be used or copied only under the terms of the license agreement.
Technical Support
232 E. Java Drive
Sunnyvale, CA 94089
Phone: |
(408) |
Email: |
support@rti.com |
Website: |
ii
Contents
1 Welcome to RTI Connext!................................................................. |
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
3 Getting Started with Connext .......................................................... |
||
3.2 Building and Running a |
||
iii
6 Design Patterns for High Performance ............................................ |
|||
|
|||
|
|||
|
|||
|
|||
iv

Chapter 1 Welcome to RTI Connext!
RTI® Connext™ solutions provide a flexible data distribution infrastructure for integrating data sources of all types. At its core is the world's leading
❏
❏
❏Connectivity for heterogeneous systems spanning thousands of applications
Connext is flexible; extensive
This chapter introduces basic concepts and summarizes how Connext addresses your high- performance needs. After this introduction, we'll jump right into building distributed systems. The rest of this guide covers:
❏First steps: Installing Connext and creating your first simple application.
❏Learning more: An overview of the APIs and programming model with a special focus on the communication model, data types and qualities of service.
❏Towards
Next Chapter
1.1A Guide to the Provided Documentation
This document will introduce you to the power and flexibility of Connext. We invite you to explore further by referring to the wealth of available information, examples, and resources:
The Connext documentation includes:
❏Core Libraries and Utilities Getting Started Guide
If you want to use the Connext Extensible Types feature, please read:
•Addendum for Extensible Types (RTI_CoreLibrariesAndUtilities_GettingStarted_ExtensibleTypesAddendum.pdf) Extensible Types allow you to define data types in a more flexible way. Your data types can evolve over
If you are using Connext on an embedded platform or with a database, you will find additional documents that specifically address these configurations:
•Addendum for Embedded Systems (RTI_CoreLibrariesAndUtilities_GettingStarted_EmbeddedSystemsAddendum.pd f)
•Addendum for Database Setup (RTI_CoreLibrariesAndUtilities_GettingStarted_DatabaseAddendum.pdf).
❏What’s New
❏Release Notes and Platform Notes (RTI_CoreLibrariesAndUtilities_ReleaseNotes.pdf,
❏User’s Manual
❏API Reference Documentation
(ReadMe.html,
The Programming How To's provide a good place to begin learning the APIs. These are hyperlinked code snippets to the full API documentation. From the ReadMe.html file, select one of the supported programming languages, then scroll down to the Programming How To’s. Start by reviewing the Publication Example and Subscription Example, which provide
Connext.
Many readers will also want to look at the additional documentation that is available online. In particular, RTI recommends the following:
❏The RTI Customer Portal, https://support.rti.com, provides access to RTI software, documentation, and support. It also allows you to log support cases. Furthermore, the portal provides detailed solutions and a free public knowledge base. To access the software, documentation, or log support cases, the RTI Customer Portal requires a

username and password. You will receive this in the email confirming your purchase. If you do not have this email, please contact license@rti.com. Resetting your login password can be done directly at the RTI Customer Portal.
❏
•Example Performance Test (available for C++, Java,
You can also review the data from several performance benchmarks here:
❏Whitepapers and other
Of course, RTI also offers excellent technical support and professional services. To contact RTI Support, simply log into the portal, send email to support@rti.com, or contact the telephone number provided for your region. We thank you for your consideration and wish you success in meeting your distributed challenge.
1.2Why Choose Connext?
Connext implements publish/subscribe networking for
1.2.1Reduce Risk Through Performance and Availability
Connext provides top performance, whether measured in terms of latency, throughput, or real- time determinism2. One reason is its elegant
Traditional messaging middleware requires dedicated servers to broker
RTI doesn’t use brokers. Messages flow directly from publishers to subscribers with minimal overhead. All the functions of the broker, including discovery (finding data sources and sinks), routing (directing data flow), and naming (identifying data types and topics) are handled in a
The design also delivers high reliability and availability, with automatic failover, configurable retries, and support redundant publishers, subscribers, networks, and more. Publishers and subscribers can start in any order, and enter and leave the network at any time; the middleware will connect and disconnect them automatically. Connext provides
1.RTI Connext .NET language binding is currently supported for C# and C++/CLI.
2.For

Traditional
RTI's unique
failure behavior and recovery, as well as detailed status notifications to allow applications to react to situations such as missed delivery deadlines, dropped connections, and slow or unresponsive nodes.
The User's Manual has details on these and all other capabilities. This guide only provides an overview.
1.2.2Reduce Cost through Ease of Use and Simplified Deployment
Connext helps keep development and deployment costs low by:
❏Increasing developer
❏Simplifying
❏Reducing hardware
1.2.3Ensure Success with Unmatched Flexibility
Out of the box, RTI is configured to achieve simple data communications. However, when you need it, RTI provides a high degree of
❏The volume of
❏The frequencies and
❏The amount of memory consumed, including the policies under which additional memory may be allocated by the middleware.
RTI’s unique and powerful
The result is

1.2.4Connect Heterogeneous Systems
Connext provides complete functionality and
❏C, C++, .Net1, Java, and Ada2 development platforms
❏Windows, Linux, Solaris, AIX, and other
❏VxWorks, INTEGRITY, LynxOS, and other
Applications written in different programming languages, running on different hardware under different operating systems, can interoperate seamlessly over Connext, allowing disparate applications to work together in even very complex systems.
1.2.5Interoperate with Databases, Event Engines, and JMS Systems
RTI provides connections between its middleware core and many types of enterprise software.
RTI also provides a Java Message Service (JMS) application programming interface. Connext
directly interoperates at the
For more information about interoperability with other middleware implementations, including IBM MQ Series, please consult your RTI account representative.
1.3What Can Connext Do?
Under the hood, Connext goes beyond basic
❏
•Simplified distributed application programming
•
•Clear semantics for managing multiple sources of the same data.
•Customizable Quality of Service and error notification.
•Guaranteed periodic messages, with minimum and maximum rates set by subscriptions
•Notifications when applications fail to meet their deadlines.
•Synchronous or asynchronous message delivery to give applications control over the degree of concurrency.
•Ability to send the same message to multiple subscribers efficiently, including support for reliable multicast with customizable levels of positive and negative message acknowledgement.
1.RTI Connext .NET language binding is currently supported for C# and C++/CLI.
2.Ada support requires a separate
3.For more information about RTI Message Service, see http://www.rti.com/products/jms/index.html. For perfor- mance benchmark results, see
❏
❏Reliable
❏Multiple communication
❏Symmetric
❏
❏Multiple network
❏
❏Vendor neutrality and standards
Am I Better Off Building My Own Middleware?
Sometimes application projects start with minimal networking needs. So it’s natural to consider whether building a simplified middleware
RTI has decades of experience with hundreds of applications. This effort created an integrated and
For example, some of the middleware functionality that your application can get by just enabling configuration parameters include:
❏Tuning reliable behavior for multicast, lossy and
❏Supporting high
❏Optimizing network and system resources for transmission of periodic data by supporting
Writing network code to connect a few nodes is deceptively easy. Making that code scale, handle all the error scenarios you will eventually face, work across platforms, keep current with technology, and adapt to unexpected future requirements is another matter entirely. The initial cost of a custom design may seem tempting, but beware; robust architectures take years to evolve. Going with a
1.4What are the Connext Products?
This Getting Started Guide describes RTI Connext DDS and Connext Messaging.
RTI Connext Professional Edition includes RTI Connext Messaging, RTI Connext Integrator, and RTI Connext Tools, plus an installer. See the RTI Connext Professional Edition Getting Started Guide for more information.
1.4.1RTI Connext DDS and Connext Messaging
Connext DDS addresses the sophisticated data bus requirements in complex systems including an API compliant with the Object Management Group (OMG) Data Distribution Service (DDS) specification. DDS is the leading
❏
❏Advanced features to address complex systems
❏Advanced Quality of Service (QoS) support
❏Comprehensive platform and network transport support
❏Seamless interoperability with Connext Micro and Connext Messaging
Connext Messaging provides a versatile and highly scalable messaging middleware for developing applications leveraging a variety of embedded and enterprise design patterns. Connext Messaging flexibility reduces development, integration and testing costs and enables rapid implementation of new system requirements. Benefits include:
❏Communication patterns for publish/subscribe,
❏Support for RTI Persistence Service for late joiners and RTI Recording Service for logging data for deep analysis and archiving
❏APIs for JMS and Connext DDS
❏Tools to monitor, analyze and debug your complete system
❏Seamless interoperability with Connext Micro and Connext DDS
This table lists the features provided with each product. The additional components provided with Connext Messaging are highlighted in blue.
Table 1.1 Comparing Connext DDS and Connext Messaging
√ = included; o = optional, † = legacy |
Connext DDS |
Connext Messaging |
|
||
|
|
|
Core Libraries & Utilities |
|
|
|
|
|
DDS - C, C++, C#, Java |
√ |
√ |
DDS - Ada |
o |
|
|
|
|
Message Service (JMS API) |
|
√ |
RTSJ Extension Kit |
o |
o |
|
|
|
Transports |
|
|
|
|
|
Shared memory, UDPv4/6, TCP |
√ |
√ |
|
|
|
TLS |
|
√ |
Secure WAN (DTLS) |
|
√ |
o |
o |
|
|
|
|
Core Capabilities |
|
|
|
|
|
√ |
√ |
|
|
|
|
|
√ |
|
Persistence Service |
|
√ |
Enterprise Discovery |
† |
|
|
|
|
Tools |
|
|
|
|
|
Interface compiler (rtiddsgen) |
√ |
√ |
|
|
|
CORBA Compatibility Kit |
o |
o |
|
|
|
Utilities (spy, ping) |
√ |
√ |
|
|
|
Spreadsheet |
√ |
√ |
|
|
|
Wireshark |
√ |
√ |
|
|
|
Launcher |
√ |
√ |
|
|
|
Scope |
† |
† |
1.4.2RTI Connext Integrator
RTI Connext Integrator is a flexible integration infrastructure for OT systems, legacy systems and bridging to IT applications while requiring little or no modification. Connext Integrator is based on a proven foundation of technology and tools used in highly diverse systems, often with extreme
❏Support of a rich set of integration capabilities including Message Translator, Content Enricher, Content Remover, Splitter and Aggregator
❏Integration support for standards including JMS, SQL databases, file, socket, Excel, OPC, STANAG, LabVIEW, Web Services and more
❏Ability for users to create custom integration adapters
❏Database Service integration for Oracle, MySQL and other relational databases
❏Tools for visualizing, debugging and managing all systems in
Connext Integrator includes these components:
❏RTI Routing Service
❏RTI Routing Service Adapter SDK
❏RTI
1.4.3RTI Connext Micro
RTI Connext Micro provides a
❏Accommodations for
❏Modular and user extensible architecture
❏Designed to be a certifiable component for
❏Seamless interoperability with Connext DDS and Connext Messaging
1.4.4RTI Connext Tools
RTI Connext Tools includes a rich set of components to accelerate debugging and testing while easing management of deployed systems. These components include:
❏Administration Console
❏Analyzer
❏Distributed Logger
❏Monitor
❏Monitoring Library
❏Recording Service

Chapter 2 Installing Connext
Connext is delivered as static and dynamic libraries with development tools, examples, and documentation that will help you use the libraries.
This chapter includes:
❏Selecting a Development Environment
Next Chapter
2.1Installing Connext
Connext is available for installation in the following forms, depending on your needs and your license terms:
❏In a single package as part of RTI Connext Professional Edition, which includes both host
(development) and target (deployment) files. If you downloaded an evaluation of Connext from the RTI website at no cost, this is the distribution you have. For installation instructions, please see the RTI Connext Professional Edition Getting Started Guide
(RTI_Connext_Professional_Edition_GettingStarted.pdf).
•For Windows users: Your installation package is an executable installer application that installs a specific Windows architecture.
•For Linux users: Your installation package is a .sh file that installs files for a specific Linux architecture.
❏In separate host and target packages. This distribution is useful for those customers who develop and deploy on different platforms, or who deploy on multiple platforms. RTI also delivers support for embedded platforms this way. To request access to additional RTI host or target platforms, please contact your RTI account representative.
•For Windows users: You have at least two .zip archives: one for your host platform and at least one target platform.
•For users of other operating systems: You have at least two .tar.gz archives: one for your host platform and at least one target platform.
2.1.1Installing on a
If you are using the RTI Connext Professional Edition installer, please see the RTI Connext Professional Edition Getting Started Guide for details.
If you are installing the RTI Core Libraries and Utilities independently (that is, you are not using the RTI Connext Professional Edition installer), the distribution is packaged in two or more .tar.gz files: a host archive that contains documentation, header files, and other files you need for development; and one or more target archives containing the libraries and other files you need for deployment. Unpack them as described below. You do not need to be logged in as root during installation.
In the following instructions, we assume your host distribution file is named
1.Make sure you have GNU’s version of the tar utility (which handles long file names). On Linux systems, this is the default tar executable. On Solaris systems, use gtar.
2.Create a directory for Connext. We will assume that you want to install under /opt/rti/ (you may replace references to /opt/rti/ with the directory of your choice).
3.Move the downloaded host and target files into your newly created directory.
4.Extract the host distribution first. For example:
gunzip
gtar xvf
5. Extract the target distribution(s)). For example:
gunzip
gtar xvf
Using our example path, you will end up with /opt/rti/ndds.5.0.x. (Note: If you have a
6.
7.Read License Management (Section 2.2).
2.1.2Installing on a Windows System
If you are using the RTI Connext Professional Edition installer, please see the RTI Connext Professional Edition Getting Started Guide for details.
If you are installing the RTI Core Libraries and Utilities independently (that is, you are not using the RTI Connext Professional Edition installer), unpack the .zip files as described below.
Depending on your needs, you will have two or more .zip archives (a host archive containing documentation, header files, and other files you need for development, and one or more target archives containing the libraries and other files you need for deployment). For example, you may have a host distribution file named
Depending on your version of Windows and where you want to expand these files, your user account may or may not require administrator privileges.

1.Create a directory for Connext. We will assume that you want to install under
C:\Program Files\RTI (you may replace references to C:\Program Files\RTI with the directory of your choice).
2.Move the downloaded host and target files into your newly created directory.
3.Extract the distribution from the .zip files. You will need a zip file utility such as WinZip® to help you. Extract the host distribution first.
Using our example path, you will end up with C:\Program Files\RTI\ndds.5.0.x. (Note: If you have a
4.
5.Read License Management (Section 2.2).
2.2License Management
Some distributions of Connext require a license file in order to run (for example, those provided for evaluation purposes or on a subscription basis).
If your Connext distribution requires a license file, you will receive one from RTI via email.
If you have licenses files for both the RTI Core Libraries and Utilities and RTI Message Service, you can concatenate both into one file.
A single license file can be used to run on any architecture and is not
2.2.1Installing the License File
Save the license file in any location of your choice; the locations checked by the middleware are listed below.
Each time your Connext application starts, it will look for the license file in the following locations until it finds a valid license:
1.In your application’s current working directory, in a file called rti_license.dat.
2.In the location specified in the environment variable RTI_LICENSE_FILE, which you may set to point to the full path of the license file, including the filename (for example,
C:\RTI\my_license_file.dat).
3.In the Connext installation, in the file $NDDSHOME/rti_license.dat. (See Section 3.1.1.1 for details on NDDSHOME.)
As Connext attempts to locate and read your license file, you may (depending on the terms of the license) see a printed message with details about your license.
If the license file cannot be found or the license has expired, your application may be unable to initialize Connext, depending on the terms of the license. If that is the case, your application’s call to DomainParticipantFactory.create_participant() will return null, preventing communication.
If you have any problems with your license file, please email support@rti.com.

2.2.2Adding or Removing License Management
If you are using an RTI software distribution that requires a license file and your license file
However, if you switch from a
2.3Navigating the Directories
Once you have installed Connext, you can access the example code used in this document under $(NDDSHOME}/example1. RTI supports the C, C++, C++/CLI, C#, Java, and Ada2 programming languages. While we will examine the C++, Java, and Ada examples in the following chapters, you can access similar code in the language of your choice.
The Connext directory tree is as follows:
$NDDSHOME |
Root directory where Connext is installed |
/class |
Java library files |
/doc |
Documentation in HTML and PDF format |
/example |
Example code |
/ADA2 |
|
/C |
|
/CPP |
|
/CPPCLI |
|
/CSHARP |
|
/JAVA |
|
/QoS |
Quality of Service (QoS) configuration files for the example code. These |
|
configuration files do not depend on the language bindings, and largely |
|
do not depend on the operating system either. |
/include |
Header files for C and C++ APIs, specification files for Ada |
/jre |
Java runtime environment files used by the rtiddsgen tool (you do not |
|
need to use this JRE to run your own Java applications) |
/lib |
Library files |
/gnat |
Ada project files |
/GNATgcc |
Ada libraries and library information files |
/ReadMe.html |
Start page for accessing the HTML documentation |
/resource |
Document format definitions and template files used by |
|
rtiddsgen |
/scripts |
RTI tools (this directory should be in your path) |
The two most important directories for learning Connext are example and doc. The doc directory contains the Connext library information in PDF and HTML formats. You may want to bookmark the HTML directory since you will be referring to this page a lot as you explore the RTI technology platform.
Example code is shipped in C, C++, C#, Java, and Ada2. You can access the example code in a language of your choice from the respective locations under the example directory. See the instructions in each example’s README_ME.txt file. These examples include:
1.See Section 3.1.1.1 for details on NDDSHOME.
2.Ada support requires a separate

❏Hello_simple: This example demonstrates one of the simplest applications you can write with Connext: it does nothing but publish and subscribe to short strings of text. This example is described in detail in Chapter 3: Getting Started with Connext.
❏Hello_builtin, Hello_idl, Hello_dynamic1: These examples demonstrate more some of the unique capabilities of Connext: strongly typed data,
❏helloWorldRequestReply: This example demonstrates how to use Requesters and Repliers (Section 3.3.7). The Replier is capable of computing the prime numbers below a certain positive integer; the Requester will request these numbers. The Replier provides the prime numbers as they are being calculated, sending multiple replies. See Building and Running a
❏News: This example demonstrates a subset of the rich functionality Connext offers, including flexible support for historical and durable data,
You can find more examples at http://www.rti.com/examples. This page contains example code snippets on how to use individual features, examples illustrating specific use cases, as well as performance test examples.
2.4Selecting a Development Environment
You can develop applications with Connext either by building and executing commands from a shell window, or by using a development environment like Microsoft® Visual Studio®, Eclipse™, or GPS from AdaCore2.
2.4.1Using the
For
❏
❏
•
•
(This script accepts other options, which we will discuss in later chapters.)
For C and C++ applications for
❏example/[C|CPP]/<example>/make/Makefile.<architecture>
where <architecture> reflects the compiler, OS and processor combination for your development environment. If you do not see your architecture listed, see Generating Code with rtiddsgen (Section 4.3.2.1) for instructions on how to generate an example makefile.
For Ada applications2, use the make command with this makefile:
❏example/ADA/<example>/make/Makefile.<architecture>
1.Hello_dynamic is not provided for Ada.
2.Ada support requires a separate

where <architecture> reflects the compiler, OS and processor combination for your development environment. If you do not see your architecture listed, see Generating Code with rtiddsgen (Section 4.3.2.1) for instructions on how to generate an example makefile.
2.4.2Using the
For
❏
❏
•
•
(This script accepts other options, which we will discuss in later chapters.)
For Java users: The native libraries used by the RTI Java API require the Visual Studio 2005 service pack 1 redistributable libraries on the target machine. You can obtain this package from Microsoft or RTI.
For C, C++, and C# users: Please use Microsoft Visual Studio 2005, service pack 1 or later1, or Visual Studio 2008 to build and run the examples.
2.4.3Using Microsoft Visual Studio
Connext includes solutions and project files for Microsoft Visual Studio in example\[C|CPP|CSHARP]\<example>\win32.
To use these solution files:
1.Start Visual Studio.
2.Select File, Open, Project/Solution.
3.In the File dialog, select the solution file for your architecture; the solution file for Visual Studio 2005 for
1. If you are using an earlier version of Visual Studio, you can obtain a

Chapter 3 Getting Started with Connext
This chapter gets you up and running with Connext. First, you will build and run your first
This chapter includes:
❏Building and Running “Hello, World” (Section 3.1)
❏Building and Running a
❏An Introduction to Connext (Section 3.3)
Next Chapter
3.1Building and Running “Hello, World”
Let’s start by compiling and running Hello World, a basic program that publishes information over the network.
For now, do not worry about understanding the code (we start covering it in Chapter 4: Capabilities and Performance). Use the following instructions to run your first middleware program using Connext.
3.1.1Step 1: Set Up the Environment
There are a few things to take care of before you start working with the example code.
3.1.1.1Set Up the Environment on Your Development Machine
a.Set the NDDSHOME environment variable.
Set the environment variable NDDSHOME to the Connext install directory. (Connext itself does not require that you set this environment variable. It is used in the scripts used to build and run the example code because it is a simple way to locate the install directory. You may or may not choose to use the same mechanism when you create scripts to build and/or run your own applications.)
•On
•On Windows systems: This location may be C:\Program Files\RTI\ndds.5.0.x.
If you have multiple versions of Connext installed:
As mentioned above, Connext does not require that you have the environment variable NDDSHOME set at run time. However, if it is set, the middleware will use it to load certain configuration files. Additionally, you may have previously set your path based on the value of that variable. Therefore, if you have NDDSHOME set, be sure it is pointing to the right copy of Connext.
b.Update your path.
Add Connext's scripts directory to your path. This will allow you to run some of the simple
•On
•On Windows systems: Add the directory to your Path environment variable.
c.If you will be using the separate
Add $NDDSHOME/lib/gnat to your ADA_PROJECT_PATH environment variable. This directory contains Ada project files that will be used in the generated example project file.
Make sure the Ada compiler, gprbuild, is in your path. The makefile used by the example assumes that gprbuild is in your path.
On
d.Make sure Java is available.
If you plan to develop in a language other than Java, you do not need Java installed on your system and can safely skip this step.
If you will be going through the examples in Java, ensure that appropriate java and javac executables are on your path. They can be found within the bin directory of your JDK installation. The Release Notes list the Java versions that are supported.
On Linux systems: Note that GNU java (from the GNU Classpath project) is not
e.Make sure the preprocessor is available.
Check whether the C preprocessor (e.g., cpp) is in your search path. This step is optional, but makes code generation with the rtiddsgen utility more convenient. Chapter 4: Capabilities and Performance describes how to use rtiddsgen.
On Windows systems:
•If you have Microsoft Visual Studio installed: Running the script vcvars32.bat, vsvars32.bat, or vcvarsall.bat (depending on your version of Visual Studio) will update the path for a given command prompt. If the Visual Studio installer did not add cl to your path already, you can run this script before running rtiddsgen.
•If you do not have Microsoft Visual Studio installed: This is often the case with Java users. You can either choose not to use a preprocessor or to obtain a
f.Get your project files ready.
If you installed Connext in a directory that is shared by multiple users (for example, in C:\Program Files on a Windows system, or /opt or /local on a
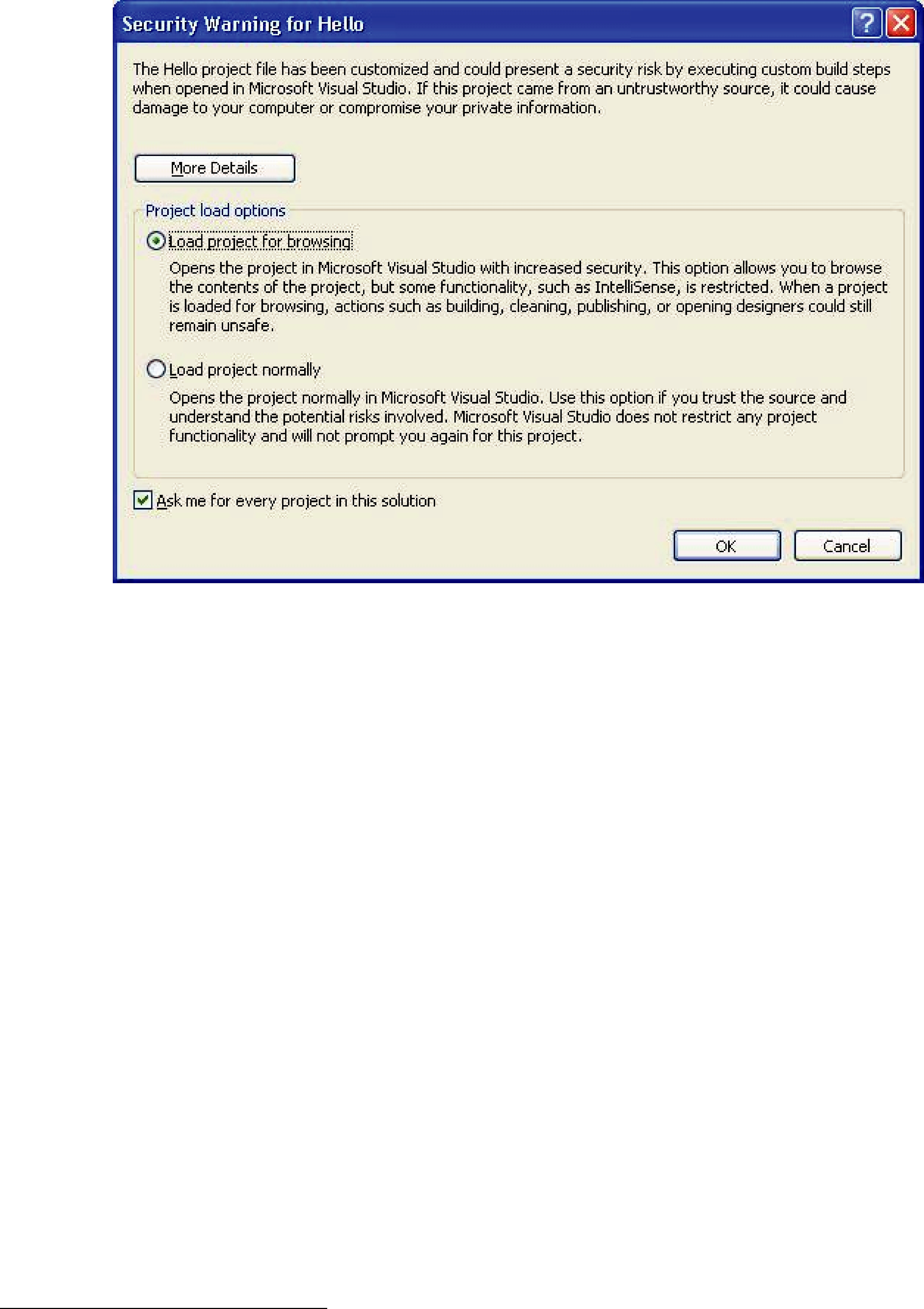
•On Windows systems: If you chose to install Connext in C:\Program Files or another system directory, Microsoft Visual Studio may present you with a warning message when you open a solution file from the installation directory. If you see this dialog, you may want to copy the example directory somewhere else, as described above.
•On
3.1.1.2Set Up the Environment on Your Deployment Machine
Some configuration has to be done for the machine(s) on which you run your application; the RTI installer can’t do that for you, because those machines may or may not be the same as where you created and built the application.
a.Make sure Java is available.
If you are a Java user, see Step d in Section 3.1.1.1 for details.
b.Make sure the dynamic libraries are available.
Make sure that your application can load the Connext dynamic libraries. If you use C, C++, or Ada1 with static libraries (the default configuration in the examples covered in
this document), you can skip this step. However, if you plan to use dynamic libraries, or Java or .NET2 (which always use dynamic libraries), you will need to modify your environment as described here.
To see if dynamic libraries are supported for your machine’s architecture, see the RTI Core Libraries and Utilities Platform Notes3.
For more information about where the Windows OS looks for dynamic libraries, see:
1.Ada support requires a separate
2.RTI Connext .NET language binding is currently supported for C# and C++/CLI.
3.In the Platform Notes, see the “Building Instructions...” table for your target architecture.

•The dynamic libraries needed by C or C++ applications are in the directory ${NDDSHOME}/lib/<architecture>. The dynamic libraries needed by Ada1 applications are in the directory ${NDDSHOME}/lib/GNATgcc/relocatable.
On
On Mac OS systems: Add this directory to your DYLD_LIBRARY_PATH environment variable.
On Windows systems: Add this directory to your Path environment variable or copy the DLLs inside into the directory containing your executable.
•The native dynamic libraries needed by Java applications are in the directory ${NDDSHOME}/lib/<architecture>. Your architecture name ends in jdk, e.g., i86Linux2.6gcc3.4.3jdk. (The gcc
identifies the corresponding native architecture that relies on the same version of the C runtime library.) The native dynamic libraries needed by Ada1 applications are in the directory $NDDSHOME/lib/<architecture>. (The gcc part of <architecture> identifies the corresponding native architecture that relies on the same version of the C
On
On Mac OS systems: Add this directory to your DYLD_LIBRARY_PATH environment variable.
On Windows systems: Add this directory to your Path environment variable.
•Java .jar files are in the directory ${NDDSHOME}/class. They will need to be on your application’s class path.
•On Windows systems: The dynamic libraries needed by .NET applications are in the directory %NDDSHOME%\lib\i86Win32dotnet2.0. You will need to either copy the
DLLs from that directory to the directory containing your executable, or add the directory containing the DLLs to your Path environment variable1. (If the .NET framework is unable to load the dynamic libraries at run time, it will throw a System.IO.FileNotFoundException and your application may fail to launch.)
3.1.2Step 2: Compile the Hello World Program
The same example code is provided in C, C++, C#, Java, and Ada2. The following instructions cover C++, Java, and Ada in detail; the procedures for C and C# are very similar. The same source code can be built and run on different architectures.
The instructions also focus on Windows and
(RTI_Connext_GettingStarted_EmbeddedSystemsAddendum.pdf) for more instructions especially for you.
C++ on Windows Systems: To build the example applications:
1.In the Windows Explorer, go to %NDDSHOME%\exam- ple\CPP\Hello_simple\win32 and open the Microsoft Visual Studio solution file for your architecture. For example, the file for Visual Studio 2005 for
1.The file nddsdotnet.dll (or nddsdotnetd.dll for debug) must be in the executable directory. Visual Studio will, by default, do this automatically.
2.Ada support requires a separate

2.The Solution Configuration combo box in the toolbar indicates whether you are building debug or release executables; select Release. Select Build Solution from the Build menu.
C++ on
From your command shell, go to ${NDDSHOME}/example/CPP/Hello_simple/. Type:
> gmake
where <architecture> is one of the supported architectures; see the contents of the make directory for a list of available architectures. (If you do not see a makefile for your architecture, please refer to Section 4.3.2.1 to learn how to generate a makefile or project files for your platform). This command will build a release executable. To build a debug version instead, type:
> gmake
Java on Windows Systems: To build the example applications:
From your command shell, go to %NDDSHOME%\example\JAVA\Hello_simple\. Type:
> build
Java on
From your command shell, go to ${NDDSHOME}/example/JAVA/Hello_simple. Type:
> ./build.sh
Ada on
From your command shell, go to ${NDDSHOME}/example/ADA/Hello_simple/. Type:
> gmake
where <architecture> is one of the supported architectures; see the contents of the make directory for a list of available architectures. (If you do not see a makefile for your architecture, please refer to Section 4.3.2.1 to learn how to generate a makefile or project files for your platform). This command will build a release executable. To build a debug version instead:
> gmake
1. Ada support requires a separate

3.1.3Step 3: Start the Subscriber
C++: To start the subscribing application:
❏On a Windows system: From your command shell, go to
%NDDSHOME%\example\CPP\Hello_simple and type:
>objs\<architecture>\HelloSubscriber.exe
where <architecture> is one of the supported architectures; see the contents of the win32 directory for a list of available architectures. For example, the Windows architecture name corresponding to
❏On a
>objs/<architecture>/HelloSubscriber
where <architecture> is one of the supported architectures; see the contents of the make directory for a list of available architectures. For example, the architecture name corresponding to Red Hat Enterprise Linux 5 is i86Linux2.6gcc4.1.1.
Java: To start the subscribing application:
(As described above, you should have already set your path appropriately so that the example application can load the native libraries on which Connext depends. If you have not, you can set the variable RTI_EXAMPLE_ARCH in your command
❏On a Windows system: From your command shell, go to
%NDDSHOME%\example\JAVA\Hello_simple and type:
>runSub
❏On a
>./runSub.sh
Ada: To start the subscribing application:
❏On a
>objs/<architecture>/hellosubscriber
Where <architecture> is one of the supported architectures; see the content of the make directory for a list of available architectures. For example, the architecture name corresponding to Red Hat Enterprise Linux 5.5 is i86Linux2.6gcc4.1.2.
3.1.4Step 4: Start the Publisher
Connext interoperates across all of the programming languages it supports, so you can choose whether to run the publisher in the same language you chose for the subscriber or a different language.
C++: To start the publishing application:
❏On a Windows system: From a different command shell, go to
%NDDSHOME%\example\CPP\Hello_simple and type:
>objs\<architecture>\HelloPublisher.exe

where <architecture> is one of the supported architectures; see the contents of the win32 directory for a list of available architectures. For example, the Windows architecture name corresponding to
❏On a
>objs/<architecture>/HelloPublisher
where <architecture> is one of the supported architectures; see the contents of the make directory for a list of available architectures. For example, the architecture name corresponding to Red Hat Enterprise Linux 5 is i86Linux2.6gcc4.1.1.
Java: To start the publishing application:
(As described above, you should have already set your path appropriately so that the example application can load the native libraries on which Connext depends. If you have not, you can set the variable RTI_EXAMPLE_ARCH in your command
❏On a Windows system: From a different command shell, go to
%NDDSHOME%\example\JAVA\Hello_simple and type:
>runPub
❏On a
>./runPub.sh
Ada1: To start the publishing application:
❏On a
>objs/<architecture>/hellopublisher
Where <architecture> is one of the supported architectures; see the contents of the make directory for a list of available architectures. For example, the architecture name corresponding to Red Hat Enterprise Linux 5.5 is i86Linux2.6gcc4.1.2.
If you typed "Hello, World" in the publishing application, you should see output similar to the following:
1. Ada support requires a separate

Congratulations! You’ve run your first Connext program!
3.2Building and Running a
Important! This section describes the
Requesters and Repliers (Section 3.3.7) contains an introduction to the Connext
RTI Connext Messaging provides the libraries that you will need (in addition to the DDS libraries) when compiling an application that uses the
❏In C, you need the additional rticonnextmsgc libraries and to use a set of macros that instantiate
❏In C++, you need the additional rticonnextmsgcpp libraries and the header file ndds/ ndds_requestreply_cpp.h.
❏In Java, you need an additional JAR file: rticonnextmsg.jar.
❏In .NET (C# and C++/CLI), you need the additional assembly rticonnextmsgdotnet.dll (for .NET 2.0) or rticonnextmsgdotnet40.dll (for .NET 4.0).
To set up your environment follow the same instructions in Section 3.1.1.
The
❏example/C/helloWorldRequestReply
❏example/CPP/ helloWorldRequestReply
❏example/CSHARP/helloWorldRequestReply
❏example/JAVA/helloWorldRequestReply
To compile the examples, follow the instructions in Section 3.1.2. Similar makefiles for UNIX- based systems and scripts for Java and Visual Studio projects are provided in these examples. Instructions for running the examples are in READ_ME.txt in the example directories. See the instructions in each example’s README_ME.txt file.
3.3An Introduction to Connext
Connext is network middleware for
Connext implements the

3.3.1An Overview of Connext Objects
The primary objects in Connext are:
Figure 3.1 Connext Components
3.3.2DomainParticipants
A domain is a concept used to bind individual applications together for communication. To communicate with each other, DataWriters and DataReaders must have the same Topic of the same data type and be members of the same domain. Each domain has a unique integer domain ID.
Applications in one domain cannot subscribe to data published in a different domain. Multiple domains allow you to have multiple virtual distributed systems on the same physical network. This can be very useful if you want to run multiple independent tests of the same applications. You can run them at the same time on the same network as long as each test runs in a different domain. Another typical configuration is to isolate your development team from your test and production teams: you can assign each team or even each developer a unique domain.
DomainParticipant objects enable an application to exchange messages within domains. An application must have a DomainParticipant for every domain in which the application will communicate. (Unless your application is a bridging application, it will typically participate in only one domain and have only one DomainParticipant.)
DomainParticipants are used to create Topics, Publishers, DataWriters, Subscribers, and DataReaders in the corresponding domain.

A DomainParticipant is analogous to a JMS Connection.
Figure 3.2 Segregating Applications with Domains
The following code shows how to instantiate a DomainParticipant. You can find more information about all of the APIs in the online documentation.
To create a DomainParticipant in C++:
participant =
create_participant(
0, /* Domain ID */ DDS_PARTICIPANT_QOS_DEFAULT, /* QoS */ NULL, /* Listener */ DDS_STATUS_MASK_NONE);
Here is the same logic in Java:
participant =
DomainParticipantFactory.get_instance().create_participant(
0, // Domain ID
DomainParticipantFactory.PARTICIPANT_QOS_DEFAULT,
null, // Listener
StatusKind.STATUS_MASK_NONE);

In Ada1, the code to create a DomainParticipant looks like this:
participant :=
DDS.DomainParticipantFactory.Get_Instance.Create_Participant(
0,
DDS.DomainParticipantFactory.PARTICIPANT_QOS_DEFAULT,
null,
DDS.STATUS_MASK_NONE);
As you can see, there are four pieces of information you supply when creating a new
DomainParticipant:
❏The ID of the domain to which it belongs.
❏Its qualities of service (QoS). The discussion on Page
❏Its listener and listener mask, which indicate the events that will generate callbacks to the DomainParticipant. You will see a brief example of a listener callback when we discuss DataReaders below. For a more comprehensive discussion of the Connext status and notification system, see Chapter 4 in the RTI Core Libraries and Utilities User’s Manual.
What is QoS?
Fine control over Quality of Service (QoS) is perhaps the most important feature of Connext. Each data
QoS policies control virtually every aspect of Connext and the underlying communications mechanisms. Many QoS policies are implemented as "contracts" between data producers (DataWriters) and consumers (DataReaders); producers offer and consumers request levels of service. The middleware is responsible for determining if the offer can satisfy the request, thereby establishing the communication or indicating an incompatibility error. Ensuring that participants meet the
❏Periodic producers can indicate the speed at which they can publish by offering guaranteed update deadlines. By setting a deadline, a producer promises to send updates at a minimum rate. Consumers may then request data at that or any slower rate. If a consumer requests a higher data rate than the producer offers, the middleware will flag that pair as incompatible and notify both the publishing and subscribing applications.
❏Producers may offer different levels of reliability, characterized in part by the number of past data samples they store for retransmission. Consumers may then request differing levels of reliable delivery, ranging from
Other QoS policies control when the middleware detects nodes that have failed, set delivery order, attach user data, prioritize messages, set resource utilization limits, partition the system into namespaces, control durability (for fault tolerance) and much more. The Connext QoS policies offer unprecedented flexible communications control. The RTI Core Libraries and Utilities User's Manual contains details about all available QoS policies.
1. Ada support requires a separate
3.3.3Publishers and DataWriters
An application uses a DataWriter to publish data into a domain. Once a DataWriter is created and configured with the correct QoS settings, an application only needs to use the DataWriter’s “write” operation to publish data.
A Publisher is used to group individual DataWriters. You can specify default QoS behavior for a Publisher and have it apply to all the DataWriters in that Publisher’s group.
A DataWriter is analogous to a JMS TopicPublisher.
A Publisher is analogous to the producing aspect of a JMS TopicSession.
Figure 3.3 Entities Associated with Publications
The following code shows how to create a DataWriter in C++:
data_writer =
DDS_DATAWRITER_QOS_DEFAULT, /* QoS */
NULL, /* Listener */
DDS_STATUS_MASK_NONE);
In Ada1 it looks like this:
data_writer := participant.Create_DataWriter (
topic,
DDS.Publisher.DATAWRITER_QOS_DEFAULT,
null,
DDS.STATUS_MASK_NONE);
As you can see, each DataWriter is tied to a single topic. All data published by that DataWriter will be directed to that Topic.
As you will learn in the next chapter, each
1. Ada support requires a separate

The code looks like this in C++:
string_writer = DDSStringDataWriter::narrow(data_writer);
In Java:
StringDataWriter dataWriter =
(StringDataWriter) participant.create_datawriter ( topic, Publisher.DATAWRITER_QOS_DEFAULT, null, // Listener StatusKind.STATUS_MASK_NONE);
In Ada1:
string_writer := DDS.Builtin_String_DataWriter.Narrow(data_writer);
Note that in this particular code example, you will not find any reference to the Publisher class. In fact, creating the Publisher object explicitly is optional, because many applications do not have the need to customize any behavior at that level. If you choose not to create a Publisher, the middleware will implicitly choose an internal Publisher object. If you do want to create a Publisher explicitly, create it with a call to participant.create_publisher() (you can find more about this method in the online documentation) and then simply replace the call to participant.create_datawriter() with a call to publisher.create_datawriter().
3.3.4Subscribers and DataReaders
A DataReader is the point through which a subscribing application accesses the data that it has received over the network.
Just as Publishers are used to group DataWriters, Subscribers are used to group DataReaders. Again, this allows you to configure a default set of QoS parameters and event handling routines that will apply to all DataReaders in the Subscriber's group.
A DataReader is analogous to a JMS TopicSubscriber.
A Subscriber is analogous to the consuming aspect of a JMS TopicSession.
Figure 3.4 Entities Associated with Subscriptions

The following code demonstrates how to create a DataReader:
data_reader =
DDS_DATAREADER_QOS_DEFAULT, /* QoS */ &listener, /* Listener */ DDS_DATA_AVAILABLE_STATUS);
Each DataReader is tied to a single topic. A DataReader will only receive data that was published on its Topic.
Here is the analogous code in Java:
StringDataReader dataReader =
(StringDataReader) participant.create_datareader ( topic,
Subscriber.DATAREADER_QOS_DEFAULT, // QoS new HelloSubscriber(), // Listener StatusKind.DATA_AVAILABLE_STATUS);
And in Ada1:
dataReader := DDS. Builtin_String_DataReader.Narrow ( participant.Create_DataReader (
topic.As_TopicDescription, DDS.Subscriber.DATAREADER_QOS_DEFAULT,
Connext provides multiple ways for you to access your data: you can receive it asynchronously in a listener, you can block your own thread waiting for it to arrive using a helper object called a WaitSet, or you can poll in a
Let’s look at the callback implementation in C++:
retcode =
if (retcode == DDS_RETCODE_NO_DATA) { /* No more samples */
break;
}else if (retcode != DDS_RETCODE_OK) { cerr << "Unable to take data from reader"
<< retcode << endl; return;
}
And in Ada2:
loop
begin
1. Ada support requires a separate

data_reader.Read_Next_Sample ( ptr_sample, sample_info'Access);
if sample_info.Valid_Data then Ada.Text_IO.Put_Line (
DDS.To_Standard_String (ptr_sample));
end if; exception
when DDS.NO_DATA =>
when others => Self.receiving := FALSE; exit;
end;
end loop;
The take_next_sample() method retrieves a single data sample (i.e., a message) from the DataReader, one at a time without blocking. If it was able to retrieve a sample, it will return DDS_RETCODE_OK. If there was no data to take, it will return DDS_RETCODE_NO_DATA. Finally, if it tried to take data but failed to do so because it encountered a problem, it will return DDS_RETCODE_ERROR or another DDS_ReturnCode_t value (see the online documentation for a full list of error codes).
Connext can publish not only actual data to a Topic, but also
This simple example is interested only in data samples, not
if (info.valid_data) {
// Valid (this isn't just a lifecycle sample): print it
cout << ptr_sample << endl;
}
Let’s see the same thing in Java:
try {
String sample = stringReader.take_next_sample(info);
if (info.valid_data) { System.out.println(sample);
}
}catch (RETCODE_NO_DATA noData) {
//No more data to read
break;
}catch (RETCODE_ERROR e) {
//An error occurred
e.printStackTrace();
}
2. Ada support requires a separate

And in Ada1:
if sample_info.Valid_Data then
Ada.Text_IO.Put_Line (DDS.To_Standard_String (ptr_sample));
end if;
Note that in this particular code example, you will not find any reference to the Subscriber class. In fact, as with Publishers, creating the Subscriber object explicitly is optional, because many applications do not have the need to customize any behavior at that level. If you, like this example, choose not to create a Subscriber, the middleware will implicitly choose an internal Subscriber object. If you do want to create a Subscriber explicitly, create it with a call to participant.create_subscriber (you can find more about this method in the online documentation) and then simply replace the call to participant.create_datareader with a call to subscriber.create_datareader.
3.3.5Topics
Topics provide the basic connection points between DataWriters and DataReaders. To communicate, the Topic of a DataWriter on one node must match the Topic of a DataReader on any other node.
A Topic is comprised of a name and a type. The name is a string that uniquely identifies the Topic within a domain. The type is the structural definition of the data contained within the Topic; this capability is described in Chapter 4: Capabilities and Performance.
You can create a Topic with the following C++ code:
topic = |
|
|
"Hello, World", |
/* Topic name*/ |
|
DDSStringTypeSupport::get_type_name(), /* Type name */ |
||
DDS_TOPIC_QOS_DEFAULT, |
/* Topic QoS */ |
|
NULL, |
/* Listener */ |
|
DDS_STATUS_MASK_NONE);
Besides the new Topic’s name and type, an application specifies three things:
❏A suggested set of QoS for DataReaders and DataWriters for this Topic.
❏A listener and listener mask that indicate which events the application wishes to be notified of, if any.
In this case, the Topic’s type is a simple string, a type that is built into the middleware.
Let’s see the same logic in Java:
Topic topic = participant.create_topic(
"Hello, World", // Topic name
StringTypeSupport.get_type_name(), // Type name
DomainParticipant.TOPIC_QOS_DEFAULT, // QoS
null, // Listener
StatusKind.STATUS_MASK_NONE);
In Ada2 it looks like this:
topic := participant.Create_Topic
1.Ada support requires a separate
2.Ada support requires a separate

(DDS.To_DDS_Builtin_String ("Hello, World"),
DDSStringTypeSupport.Get_Type_Name,
DDS.DomainParticipant.TOPIC_QOS_DEFAULT,
null,
DDS.STATUS_MASK_NONE);
3.3.6Keys and Samples
The data values associated with a Topic can change over time. The different values of the Topic passed between applications are called samples.
A sample is analogous to a message in other
An application may use a single Topic to carry data about many objects. For example, a stock- trading application may have a single topic, "Stock Price," that it uses to communicate information about Apple, Google, Microsoft, and many other companies. Similarly, a radar track management application may have a single topic, "Aircraft Position," that carries data about many different airplanes and other vehicles. These objects within a Topic are called instances. For a specific data type, you can select one or more fields within the data type to form a key. A key is used to uniquely identify one instance of a Topic from another instance of the same Topic, very much like how the primary key in a database table identifies one record or another. Samples of different instances have different values for the key. Samples of the same instance of a Topic have the same key. Note that not all Topics have keys. For Topics without keys, there is only a single instance of that Topic.
3.3.7Requesters and Repliers
Important! This section describes the
Requesters and Repliers provide a way to use the
An application uses a Requester to send requests to a Replier; another application using a Replier receives a request and can send one or more replies for that request. The Requester that sent the request (and only that one) will receive the reply (or replies).
A Requester uses an existing DomainParticipant to communicate through a domain. It owns a DataWriter for writing requests and a DataReader for receiving replies.
Similarly, a Replier uses an existing DomainParticipant to communicate through a domain and owns a DataReader for receiving requests and a DataWriter for writing replies.
The Reply Topic filters samples so replies are received by exactly one
You can specify the QoS for the DataWriters and DataReaders that Requesters and Repliers create.
The following code shows how to create a Requester in C++:
Requester<Foo, Bar> * requester =
new Requester<Foo, Bar>(participant, "MyService");
In Java it looks like this:
Requester<Foo, Bar> requester = new Requester<Foo, Bar>( participant, "MyService", FooTypeSupport.get_instance(), BarTypeSupport.get_instance());
As you can see, we are passing an existing DomainParticipant to the constructor.

Figure 3.5
Foo is the request type and Bar is the reply type. In Compact,
The constructor also receives a string "MyService." This is the service name, and is used to create the Request Topic and the Reply Topic. In this example, the Requester will create a Request Topic called "MyServiceRequest" and a Reply Topic called "MyServiceReply."
Creating a Replier is very similar. The following code shows how to create a Replier in C++:
Replier<Foo, Bar> * replier =
new Replier<Foo, Bar>(participant, "TestService");
And in Java:
Replier<Foo, Bar> replier = new Replier<Foo, Bar>( participant, "TestService", FooTypeSupport.get_instance(), BarTypeSupport.get_instance());
This Replier will communicate with the Requester we created before, because they use the same service name (hence the topics are the same) and they use compatible QoS (the default).
More example code is available for C++, C, Java and C# as part of the API Reference HTML documentation, under Modules, Programming
Chapter 4 Capabilities and Performance
In the previous chapter, you learned the basic concepts in Connext and applied them to a simple "Hello, World" application. In this chapter, you will learn more about some of the powerful and unique benefits of Connext:
❏A rich set of functionality, implemented for you by the middleware so that you don't have to build it into your application. Most of this
❏Compact,
❏
❏You can also review the data from several performance benchmarks here: http://
Next Chapter

4.1Automatic Application Discovery
As you’ve been running the code example described in this guide, you may have noticed that you have not had to start any server processes or configure any network addresses. Its
Before applications can communicate, they need to “discover” each other. By default, Connext applications discover each other using shared memory or UDP loopback if they are on the same host or using multicast1 if they are on different hosts. Therefore, to run an application on two or more computers using multicast, or on a single computer with a network connection, no changes are needed. They will discover each other automatically! The chapter on Discovery in the RTI Core Libraries and Utilities User’s Manual describes the process in more detail.
If you want to use computers that do not support multicast (or you need to use unicast for some other reason), or if you want to run on a single computer that does not have a network connection (in which case your operating system may have disabled your network stack), there is a simple way to control the discovery
4.1.1When to Set the Discovery Peers
There are only a few situations in which you must set the discovery peers:
(In the following, replace N with the number of Connext applications you want to run.)
1.If you cannot use multicast2:
Set your discovery peers to a list of all of the hosts that need to discover each other. The list can contain hostnames and/or IP addresses; each entry should be of the form
N@builtin.udpv4://<hostname|IP>.
2.If you do not have a network connection:
Some operating
•If your system supports shared memory2, set your discovery peers to N@builtin.shmem://. This will enable the shared memory transport only.
•If your system does not support shared memory (or it is disabled), set your discovery peers to the loopback address, N@builtin.udpv4://127.0.0.1.
4.1.2How to Set Your Discovery Peers
As stated above, in most cases you do not need to set your discovery peers explicitly. If setting them is required, there are two easy ways to do so:
1.With the exception of LynxOS. On LynxOS systems, multicast is not used for discovery by default unless NDDS_DISCOVERY_PEERS is set.
2.To see if your platform supports RTI’s multicast network and shared memory transports, see the RTI Core Libraries and Utilities Platform Notes (RTI_Connext_PlatformNotes.pdf).
❏Set the NDDS_DISCOVERY_PEERS environment variable to a
• On Windows systems: For example:
set NDDS_DISCOVERY_PEERS=3@builtin.udpv4://mypeerhost1,\
4@builtin.udpv4://mypeerhost2
• On
setenv NDDS_DISCOVERY_PEERS 3@builtin.udpv4://mypeerhost1,\
4@builtin.udpv4://mypeerhost2
❏ Set the discovery peer list in your XML QoS configuration file.
For example, to turn on shared memory only:
<participant_qos> <discovery>
The initial_peers list are those "addresses" to which the middleware will send discovery announcements.
<element>4@builtin.shmem://</element> </initial_peers>
The multicast_receive_addresses list identifies where the DomainParticipant listens for multicast announcements from others. Set this list to an empty value to disable listening over multicast.
</discovery> <transport_builtin>
The transport_builtin mask identifies which builtin transports the domain participant uses. The default value is UDPv4 | SHMEM, so set this mask to SHMEM to prevent other nodes from initiating communication with this node via UDPv4.
</transport_builtin>
...
</participant_qos>
For more information, please see the RTI Core Libraries and Utilities Platform Notes, User’s Manual, and the API Reference HTML documentation (from the main page, select Modules, Infrastructure Module, QoS Policies, DISCOVERY).
4.2Customizing Behavior: QoS Configuration
Almost every object in the Connext API is associated with QoS policies that govern its behavior. These policies govern everything from the amount of memory the object may use to store incoming or outgoing data, to the degree of reliability required, to the amount of
Reliability and Availability for Consistent Behavior with Critical Data:
❏Reliability: Specifies whether or not the middleware will deliver data reliably. The reliability of a connection between a DataWriter and DataReader is entirely user configurable. It can be done on a per
For some use cases, such as the periodic update of sensor values to a GUI displaying the value to a person,
However, there are data streams (topics) in which you want an absolute guarantee that all data sent by a DataWriter is received reliably by DataReaders. This means that the middleware must check whether or not data was received, and repair any data that was lost by resending a copy of the data as many times as it takes for the DataReader to receive the data.
❏History: Specifies how much data must be stored by the middleware for the DataWriter or DataReader. This QoS policy affects the Reliability and Durability QoS policies.
When a DataWriter sends data or a DataReader receives data, the data sent or received is stored in a cache whose contents are controlled by the History QosPolicy. The History QosPolicy can tell the middleware to store all of the data that was sent or received, or only store the last n values sent or received. If the History QosPolicy is set to keep the last n values only, then after n values have been sent or received, any new data will overwrite the oldest data in the queue. The queue thus acts like a circular buffer of length n.
This QoS policy interacts with the Reliability QosPolicy by controlling whether or not the middleware guarantees that (a) all of the data sent is received (using the KEEP_ALL setting of the History QosPolicy) or (b) that only the last n data values sent are received (a reduced level of reliability, using the KEEP_LAST setting of the History QosPolicy). See the Reliability QosPolicy for more information.
Also, the amount of data sent to new DataReaders whose Durability QosPolicy (see below) is set to receive previously published data is controlled by the History QosPolicy.
❏Lifespan: Specifies how long the middleware should consider data sent by a user application to be valid.
The middleware attaches timestamps to all data sent and received. When you specify a finite Lifespan for your data, the middleware will compare the current time with those timestamps and drop data when your specified Lifespan expires. You can use the Lifespan QosPolicy to ensure that applications do not receive or act on data, commands or messages that are too old and have "expired."
❏Durability: Specifies whether or not the middleware will store and deliver previously published data to new DataReaders. This policy helps ensure that DataReaders get all data that was sent by DataWriters, even if it was sent while the DataReader was disconnected from the network. It can increase a system's tolerance to failure conditions.
Fault Tolerance for increased robustness and reduced risk:
❏Liveliness: Specifies and configures the mechanism that allows DataReaders to detect when DataWriters become disconnected or "dead." It can be used during system integration to ensure that systems meet their intended responsiveness specifications. It can also be used during run time to detect possible losses of connectivity.
❏Ownership and Ownership Strength: Along with Ownership Strength, Ownership specifies if a DataReader can receive data of a given instance from multiple DataWriters at the same time. By default, DataReaders for a given topic can receive data of all instances from any DataWriter for the same topic. But you can also configure a DataReader to receive data of a given instance from only one DataWriter at a time. The DataWriter with the highest Ownership Strength value will be the owner of the instance and the one whose data is delivered to DataReaders. Data of that instance sent by all other DataWriters with lower Ownership Strength will be dropped by the middleware.
When the DataWriter with the highest Ownership strength loses its liveliness (as controlled by the Liveliness QosPolicy) or misses a deadline (as controlled by the Deadline QosPolicy) or whose application quits, dies, or otherwise disconnects, the middleware will change ownership of the topic to the DataWriter with the highest Ownership Strength from the remaining DataWriters. This QoS policy can help you build systems that have redundant elements to safeguard against component or application failures. When systems have active and hot standby components, the Ownership QosPolicy can be used to ensure that data from standby applications are only delivered in the case of the failure of the primary.
❏Deadline: For a DataReader, this QoS specifies the maximum expected elapsed time between arriving data samples. For a DataWriter, it specifies a commitment to publish samples with no greater than this elapsed time between them.
This policy can be used during system integration to ensure that applications have been coded to meet design specifications. It can be used during run time to detect when systems are performing outside of design specifications. Receiving applications can take appropriate actions to prevent total system failure when data is not received in time. For topics on which data is not expected to be periodic, the deadline period should be set to an infinite value.
You can specify an object's QoS two ways: (a) programmatically, in your application's source code or (b) in an XML configuration file. The same parameters are available, regardless of which way you choose. For complete information about all of the policies available, see Chapter 4 in the RTI Core Libraries and Utilities User's Manual or see the API Reference HTML documentation.
The examples covered in this document are intended to be configured with XML files. You can find several example configurations, called profiles, in the directory $NDDSHOME/example/ QoS. The easiest way to use one of these profile files is to either set the environment variable NDDS_QOS_PROFILES to the path of the file you want, or copy that file into your current working directory with the file name USER_QOS_PROFILES.xml before running your application.
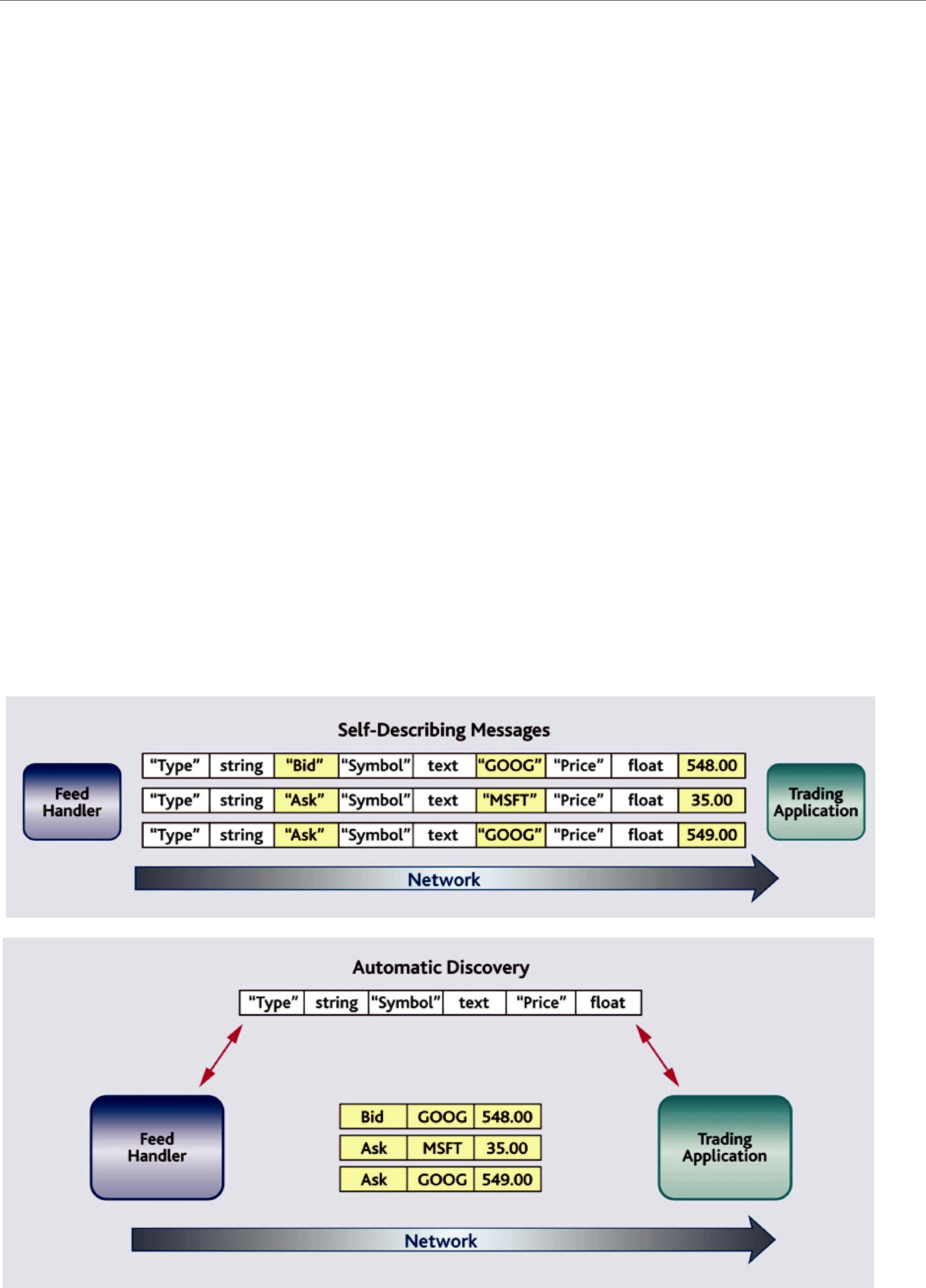
4.3Compact,
How data is stored or laid out in memory can vary from language to language, compiler to compiler, operating system to operating system, and processor to processor. This combination of language/compiler/operating system/processor is called a platform. Any modern middleware must be able to take data from one specific platform (say C/gcc 3.2.2/Solaris/Sparc) and transparently deliver it to another (for example, Java/JDK 1.6/Windows XP/Pentium). This process is commonly called serialization/deserialization or marshalling/demarshalling. Messaging products have typically taken one of two approaches to this problem:
❏Do nothing. With this approach, the middleware does not provide any help and user code must take into account
❏Send everything, every time.
The “do nothing” approach is lightweight on its surface but forces you, the user of the middleware API, to consider all data encoding, alignment, and padding issues. The “send everything” alternative results in large amounts of redundant information being sent with every packet, impacting performance.
Figure 4.1
Connext exchanges data type definitions, such as field names and types, once at application
Connext takes an intermediate approach. Just as objects in your application program belong to some data type, data samples sent on the same Topic share a data type. This type defines the fields that exist in the data samples and what their constituent types are; users in the aerospace and defense industries will recognize such type definitions as a form of Interface Definition Document (IDD). Connext stores and propagates this
Table 4.1 |
Example IDD |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
16 |
|
|
|
|
|
|
|
24 |
|
|
|
|
|
|
31 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Message ID: unsigned short |
|
|
|
|
|
|
|
Track ID: unsigned short |
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
Position X: short |
|
|
|
|
|
|
|
Position Y: short |
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Identity: |
|||
|
Position Z: short |
|
|
|
|
|
|
|
Track Type: unsigned short :12 |
|
|
|
unsigned |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
short :4 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
Speed: float |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
This example IDD shows one legacy approach to type definition. RTI supports multiple standard type definition formats that are machine readable as well as human readable.
With RTI, you have a number of choices when it comes to defining and using data types. You can choose one of these options, or you can mix and match
❏Use the
❏Define a type at
Whereas
•OMG IDL. This format is a standard component of both the DDS and CORBA specifications. It describes data types with a
•XML schema (XSD), whether independent or embedded in a WSDL file. XSD may be the format of choice for those using Connext alongside or connected to a web services infrastructure. This format is described in Chapter 3 of the RTI Core Libraries and Utilities User’s Manual.
•XML in a

❏Define a dynamic type programmatically at run time.1 This method may be appropriate for applications with dynamic data description needs: applications for which types change frequently or cannot be known ahead of time. It allows you to use an API similar to those of Tibco Rendezvous or JMS MapMessage to manipulate messages without sacrificing efficiency. It is described in Running with Dynamic Types (Section 4.3.3).
The following sections of this document describe each of these models.
4.3.1Using
Connext provides a set of standard types that are built into the middleware. These types can be used immediately. The supported
These
4.3.2Using Types Defined at Compile Time
In this section, we define a type at compile time using a
The code generator accepts
As described in the Release Notes, some platforms are supported as both a host and a target, while others are only supported as a target. The rtiddsgen tool must be run on a computer that is supported as a host. For
The following sections will take your through the process of generating example code from your own data type.
4.3.2.1Generating Code with rtiddsgen
Don't worry about how types are defined in detail for now (we cover it in Chapter 3 of the RTI Core Libraries and Utilities User's Manual). For this example, just copy and paste the following into a new file, HelloWorld.idl.
const long HELLO_MAX_STRING_SIZE = 256;
struct HelloWorld {
string<HELLO_MAX_STRING_SIZE> message;
};
Next, we will invoke the rtiddsgen
1. Dynamic types are not supported when using the separate

For a complete list of the arguments rtiddsgen understands, and a brief description of each of them, run it with the
4.3.2.1.2Instructions for C++
Generate C++ code from your IDL file with the following command (replace the architecture name i86Linux2.6gcc3.4.3 with the name of your own architecture):
> rtiddsgen |
\ |
\ |
|
\ |
|
HelloWorld.idl |
|
The generated code publishes identical data samples and subscribes to them, printing the received data to the terminal. Edit the code to modify each data sample before it's published: Open HelloWorld_publisher.cxx. In the code for publisher_main(), locate the "for" loop and add the bold line seen below, which puts "Hello World!" and a consecutive number in each sample that is sent.1
for (count=0;
(sample_count == 0) || (count < sample_count); ++count) {
printf ( "Writing HelloWorld, count %d\n", count);
/* Modify data to send here */
sprintf (
retcode =
if (retcode != DDS_RETCODE_OK) { printf("write error %d\n", retcode);
}
NDDSUtility::sleep(send_period);
}
4.3.2.1.3Instructions for Java
Generate Java code from your IDL file with the following command2 (replace the architecture name i86Linux2.6gcc3.4.3jdk with the name of your own architecture):
> rtiddsgen |
\ |
\ |
|
\ |
|
HelloWorld.idl |
|
1.If you are using Visual Studio 2005 or Visual Studio 2008, consider using sprintf_s instead of sprintf:
2.The argument

The generated code publishes identical data samples and subscribes to them, printing the received data to the terminal. Edit the code to modify each data sample before it's published: Open HelloWorldPublisher.java. In the code for publisherMain(), locate the "for" loop and add the bold line seen below, which puts "Hello World!" and a consecutive number in each sample that is sent.
for (int count = 0;
sampleCount == 0) || (count < sampleCount); ++count) {
System.out.println(
"Writing HelloWorld, count " + count);
/* Modify the instance to be written here */ instance.msg = "Hello World! (" + count + ")";
/* Write data */
writer.write (instance, InstanceHandle_t.HANDLE_NIL); try { Thread.sleep ( sendPeriodMillis);
} catch (InterruptedException ix) { System.err.println ( "INTERRUPTED"); break;
}
}
4.3.2.1.1Instructions for Ada
Generate Ada code from your IDL file with the following command (replace the architecture name i86Linux2.6gcc4.1.2 with the name of your own architecture):
rtiddsgen
Notes:
❏Ada support requires a separate
❏The generated publisher and subscriber source files are under the samples directory. There are two generated project files: one at the top level and one in the samples directory. The project file in the samples directory,
❏The generated Ada project files need two directories to compile a project: .obj and bin. If your Ada IDE does not automatically create these directories, you will need to create them outside the Ada IDE, in both the
for the “Count in 0 .. Sample_Count “loop
Put_Line ("Writing HelloWorld, count " & Count'Img); declare
Msg : DDS.String := DDS.To_DDS_String
("Hello World! (" & Count'Img & ")");
begin
if Instance.message /= DDS.NULL_STRING then Finalize (Instance.message);
end if;
Instance.message.data := Msg.data; end;

HelloWorld_Writer.Write (
Instance_Data => Instance,
Handle => Instance_Handle'Unchecked_Access); delay Send_Period;
end loop;
if Instance.message /= DDS.NULL_STRING then Finalize (Instance.message);
end if;
4.3.2.2Building the Generated Code
You have now defined your data type, generated code for it, and customized that code. It's time to compile the example applications.
4.3.2.2.1Building a Generated C, C++, or .NET Example on Windows Systems
With the NDDSHOME environment variable set, start Visual Studio and open the rtiddsgen-
generated workspace (.dsw) or solution object (.sln) file. Select the Win32 Release configuration in the Build toolbar in Visual Studio, or the Standard toolbar in Visual Studio .NET1. From the
Build menu, select Build Solution. This will build two projects: <IDL name>_publisher and
<IDL name>_subscriber2.
4.3.2.2.2Building a Generated Ada Example on a Linux System
Ada support requires a separate
Note: The generated project file assumes the correct version of the compiler is already on your path, NDDSHOME is set, and $NDDSHOME/lib/gnat is in your ADA_PROJECT_PATH.
gmake
After compiling the Ada example, you will find the application executables in the directory, samples/bin. The build command in the generated makefile uses the static release versions of the Connext libraries. To select dynamic or debug versions of the libraries, change the Ada compiler variables LIBRARY_TYPE and NDDS_BUILD in the build command in the makefile to build with the desired version of the libraries. For example, if the application must be compiled with the relocatable debug version of the libraries, compile with the following command:
gprbuild
4.3.2.2.3Building a Generated Example on Other Platforms
Use the generated makefile to compile a C or C++ example on a
gmake
1.RTI Connext .NET language binding is currently supported for C# and C++/CLI.
2.There is one exception. For C# users: Select the Mixed Platforms Release configuration in the Standard toolbar in Visual Studio (.NET) 2005. Select Build Solution from the Build menu. This will build 3 projects:
<IDL name>_type, <IDL name>_publisher and <IDL name>_subscriber. Note for Visual Studio 2008 users: Although the project files generated by rtiddsgen are for Visual Studio 2005, you can open them with Visual Studio 2008. Visual 2008 will launch an upgrade wizard to convert the files to Visual Studio 2008 project files. Once the upgrade is done, the rest of the steps are the same.

After compiling the C or C++ example, you will find the application executables in a directory objs/<architecture>.
The generated makefile includes the static release versions of the Connext libraries. To select dynamic or debug versions of the libraries, edit the makefile to change the library suffixes. Generally, Connext uses the following convention for library suffixes: "z" for static release, "zd" for static debug, none for dynamic release, and "d" for dynamic debug. For a complete list of the required libraries for each configuration, see the RTI Core Libraries and Utilities Platform Notes.
For example, to change a C++ makefile from using static release to dynamic release libraries, change this directive:
LIBS =
to:
LIBS =
4.3.2.3Running the Example Applications
Run the example publishing and subscribing applications and see them communicate:
4.3.2.3.1Running the Generated C++ Example
First, start the subscriber application, HelloWorld_subscriber:
./objs/<architecture>/HelloWorld_subscriber
In this command window, you should see that the subscriber wakes up every four seconds to print a message:
HelloWorld subscriber sleeping for 4 sec...
HelloWorld subscriber sleeping for 4 sec...
HelloWorld subscriber sleeping for 4 sec...
Next, open another command prompt window and start the publisher application,
HelloWorld_publisher. For example:
./objs/<architecture>/HelloWorld_publisher
In this second (publishing) command window, you should see:
Writing HelloWorld, count 0
Writing HelloWorld, count 1
Writing HelloWorld, count 2
Look back in the first (subscribing) command window. You should see that the subscriber is now receiving messages from the publisher:
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {0}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {1}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {2}“
4.3.2.3.2Running the Generated Java Example
You can run the generated applications using the generated makefile. On most platforms, the
generated makefile assumes the correct version of java is already on your path and that the NDDSHOME environment variable is set1.

First, run the subscriber:
gmake
In this command window, you should see that the subscriber wakes up every four seconds to print a message:
HelloWorld subscriber sleeping for 4 sec...
HelloWorld subscriber sleeping for 4 sec...
HelloWorld subscriber sleeping for 4 sec...
Next, run the publisher:
gmake
In this second (publishing) command window, you should see:
Writing HelloWorld, count 0
Writing HelloWorld, count 1
Writing HelloWorld, count 2
Look back in the first (subscribing) command window. You should see that the subscriber is now receiving messages from the publisher:
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {0}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {1}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {2}“
4.3.2.3.3Running the Generated Ada Example
Ada support requires a separate
First, start the subscriber application,
In this command window, you should see that the subscriber wakes up every four seconds to print a message:
HelloWorld subscriber sleeping for 4.000000000 sec.
HelloWorld subscriber sleeping for 4.000000000 sec.
HelloWorld subscriber sleeping for 4.000000000 sec.
Next, open another command prompt window and start the publisher application,
In this second (publishing) command window, you should see:
Writing HelloWorld, count 0
Writing HelloWorld, count 1
Writing HelloWorld, count 2
1. One exception in LynxOS; see the chapter Getting Started on Embedded
Look back in the first (subscribing) command window. You should see that the subscriber is now receiving messages from the publisher:
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {0}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {1}“
HelloWorld subscriber sleeping for 4 sec...
msg: “Hello World! {2}“
4.3.3Running with Dynamic Types
Note: Dynamic types are not supported when using Ada 2005 Language Support
This method may be appropriate for applications for which the structure (type) of messages changes frequently or for deployed systems in which newer versions of applications need to interoperate with existing applications that cannot be recompiled to incorporate
As your system evolves, you may find that your data types need to change. And unless your system is relatively small, you may not be able to bring it all down at once in order to modify them. Instead, you may need to upgrade your types one component at a
While covering dynamic types is outside the scope of this chapter, you can learn more about the subject in Chapter 3 of the RTI Core Libraries and Utilities User's Manual. You can also view and run the Hello World example code located in $NDDSHOME/example/<language>/ Hello_dynamic/src.

Chapter 5 Design Patterns for Rapid Development
In this chapter, you will learn how to implement some common functional design patterns. As you have learned, one of the advantages to using Connext is that you can achieve significantly different functionality without changing your application code simply by updating the XML- based Quality of Service (QoS) parameters.
In this chapter, we will look at a simple newspaper example to illustrate these design patterns. Newspaper distribution has long been a canonical example of
A radar tracking system and a market data distribution system share many features with the news subscriptions we are all familiar with:

In a newspaper scenario (provided in an example called News example for all languages, a news publishing application distributes articles from a variety of news
This chapter describes Building and Running the Code Examples (Section 5.1) and includes the following design patterns:
❏Subscribing Only to Relevant Data (Section 5.2)
❏Accessing Historical Data when Joining the Network (Section 5.3)
❏Caching Data Within the Middleware (Section 5.4)
❏Receiving Notifications When Data Delivery Is Late (Section 5.5)
You can find more examples at http://www.rti.com/examples. This page contains example code snippets on how to use individual features, examples illustrating specific use cases, as well as performance test examples.
Next Chapter
5.1Building and Running the Code Examples
Source code for the News example is in the directory ${NDDSHOME}/example/<language>/ News.
The example performs these steps:
1.Parses the
2.Loads the
3.On the publishing side, sends news articles periodically.
4.On the subscribing side, receives these articles and print them out periodically.
The steps for compiling and running the program are similar to those described in Building and Running “Hello, World” (Section 3.1). As with the Hello World example, Java users should use the build and run command scripts in the directory ${NDDSHOME}/example/JAVA/News.
The News example combines the publisher and subscriber in a single program, which is run from the ${NDDSHOME}/example/<language>/News directory with the argument pub or sub to select the desired behavior. When running with default arguments, you should see output similar to that shown in Figure 5.1. To see additional
1. Ada support requires a separate
Both the publishing application and the subscribing application operate in a periodic fashion:
❏The publishing application writes articles from different news outlets at different rates. Each of these articles is numbered consecutively with respect to its news outlet. Every two seconds, the publisher prints a summary of what it wrote in the previous period.
❏The subscribing application polls the cache of its DataReader every two seconds and prints the data it finds there. (Many
By default, both the publishing and subscribing applications run for 20 seconds and then quit. (To run them for a different number of seconds, use the
Figure 5.1 Example Output for Both Applications
Publishing Application |
Subscribing Application |
5.2Subscribing Only to Relevant Data
From reading Chapter 3: Getting Started with Connext, you should already understand how to subscribe only to the topics in which you’re interested. However, depending on your application, you may be interested in only a fraction of the data available on those topics. Extraneous, uninteresting, or obsolete data puts a drain on your network and CPU resources and complicates your application logic.
Fortunately, Connext can perform much of your filtering and data reduction for you. Data reduction is a general term for discarding unnecessary or irrelevant data so that you can spend

you time processing the data you care about. You can define the set of data that is relevant to you based on:
❏Its content.
❏How old it is. You can indicate that data is relevant for only a certain period of time (its lifespan) and/or that you wish to retain only a certain number of data samples (a history depth). For example, if you are interested in the last ten articles from each news outlet, you can set the history depth to 10.
❏How fast it’s updated. Sometimes data streams represent the state of a moving or changing
5.2.1
A DataReader can filter incoming data by subscribing not to a given Topic itself, but to a ContentFilteredTopic that associates the Topic with an
5.2.1.1Implementation
The C++ code looks like this:
DDSContentFilteredTopic cft =
cftName.c_str(), topic, contentFilterExpression.c_str(), noFilterParams);
if (cft == NULL) {
throw std::runtime_error(
"Cannot create ContentFilteredTopic");
}
The Topic and ContentFilteredTopic classes share a base class: TopicDescription.
The variable contentFilterExpression in the above example code is a SQL expression; see immediately below.

The corresponding code in Java looks like this:
ContentFilteredTopic cft = participant.create_contentfilteredtopic(
topic.get_name() + " (filtered)", topic, contentFilterExpression, null);
if (cft == null) {
throw new IllegalStateException ( "Cannot create ContentFilteredTopic");
}
The Ada1 code to create a ContentFilteredTopic looks like this:
declare
cft : DDS.ContentFilteredTopic.Ref_Access; cftName : DDS.String :=
DDS.To_DDS_String (
DDS.To_Standard_String (
topic.Get_Name) & " (filtered)");
begin
cft := participant.Create_Contentfilteredtopic ( cftName, topic,
contentFilterExpression, null); DDS.Finalize (cftName);
if cft = null then Put_Line (
Standard_Error,
"Cannot create ContentFilteredTopic"); return;
end if; end;
In Ada, ContentFilteredTopic class inherits from TopicDescription while Topic has a function ‘As_TopicDescription’ that is useful to create a DataReader where a TopicDescription is needed.
5.2.1.2Running & Verifying
The following shows a simple filter with which the subscribing application indicates it is interested only in news articles from CNN; you can specify such a filter with the
> ./run.sh sub
This example uses the
1. Ada support requires a separate

You can find more detailed information in the online API documentation under Modules, RTI Connext API Reference, Queries and Filters Syntax. For Ada1, open doc/html/api_ada/ index.html and look under RTI Connext API Reference, DDSQueryAndFilterSyntaxModule.
Figure 5.2 Using a
Publishing Application |
Subscribing Application |
5.2.2Lifespan and History Depth
One of the most common ways to reduce data is to indicate for how long a data sample remains valid once it has been sent. You can indicate such a contract in one (or both) of two ways: in terms of a number of samples to retain (the history depth) and the elapsed time period during which a sample should be retained (the lifespan). For example, you may be interested in only the most recent data value (the
The history depth and lifespan, which can be specified declaratively with QoS policies (see below), apply both to durable historical data sent to

5.2.2.1Implementation
History depth is part of the History QoS policy. The lifespan is specified with the Lifespan QoS policy. The History QoS policy applies independently to both the DataReader and the DataWriter; the values specified on both sides of the communication need not agree. The Lifespan QoS policy is specified only on the DataWriter, but it is enforced on both sides: the DataReader will enforce the lifespan indicated by each DataWriter it discovers for each sample it receives from that DataWriter.
For more information about these QoS policies, consult the online API documentation. Open
ReadMe.html and select the API documentation for your language, then select Modules, RTI Connext API Reference, Infrastructure, QoS Policies. For Ada1: open doc/html/api_ada/ index.html and select Infrastructure Module, DDSQosTypesModule.
You can specify these QoS policies either in your application code or in one or more XML files. Both mechanisms are functionally equivalent; the News example provided for C, C++, Java, and Ada uses XML files. For more information about this mechanism, see the chapter on “Configuring QoS with XML” in the RTI Core Libraries and Utilities User’s Manual.
5.2.2.1.1History Depth
The DDS specification, which Connext implements, recognizes two “kinds” of history: KEEP_ALL and KEEP_LAST. KEEP_ALL history indicates that the application wants to see every data sample, regardless of how old it is (subject, of course, to lifespan and other QoS policies). KEEP_LAST history indicates that only a certain number of back samples are relevant; this number is indicated by a second parameter, the history depth. (The depth value, if any, is ignored if the kind is set to KEEP_ALL.)
To specify a default History policy of KEEP_LAST and a depth of 10 in a QoS profile:
<history>
<kind>KEEP_LAST_HISTORY_QOS</kind>
<depth>10</depth>
</history>
You can see this in the News example (provided for C, C++, Java, and Ada) in the file
USER_QOS_PROFILES.xml.
Lifespan Duration
The Lifespan QoS policy contains a field duration that indicates for how long each sample remains valid. The duration is measured relative to the sample’s reception time stamp, which means that it doesn’t include the latency of the underlying transport.
To specify a Lifespan duration of six seconds:
<lifespan>
<duration>
<sec>6</sec>
<nanosec>0</nanosec>
</duration>
</lifespan>
You can see this in the News example (provided for C, C++, Java, and Ada) in the file
USER_QOS_PROFILES.xml.
1. Ada support requires a separate

5.2.2.2Running & Verifying
The News example never takes samples from the middleware, it only reads samples, so data samples that have already been viewed by the subscribing application remain in the middleware’s internal cache until they are expired by their history depth or lifespan duration contract. These previously viewed samples are displayed by the subscribing application as “cached” to make them easy to spot. See how “CNN” articles are expired:
Figure 5.3 Using History and Lifespan
Article 1 initially received from Reuters and CNN
CNN articles still available
Reuters articles
due to history depth (10 samples)
CNN articles 1 & 2 expired due to lifespan (6 seconds)
It's important to understand that the data type used by this example is keyed on the name of the news outlet and that the history depth is enforced on a
Remember that there is a strong analogy between DDS and relational databases: the key of a Topic is like the primary key of a database table, and the instance corresponding to that key is like the table row corresponding to that primary key.
Next, we will change the history depth and lifespan duration in the file USER_QOS_PROFILES.xml to see how the example's output changes.
Set the history depth to one.
Run the example again with the
> ./run.sh sub
You will only see articles from CNN and Reuters, and only the last value published for each (as of the end of the
Now set the history depth to 10 and decrease the lifespan to three seconds.
With these settings and at the rates used by this example, the lifespan will always take effect before the history depth. Run the example again, this time without a content filter. Notice how the subscribing application sees all of the data that was published during the last
Reduce the lifespan again, this time to one second.
If you run the example now, you will see no cached articles at all. Do you understand why? The subscribing application’s polling period is two seconds, so by the time the next poll comes, everything seen the previous time has expired.
Try changing the history depth and lifespan duration in the file USER_QOS_PROFILES.xml to see how the example’s output changes.
5.2.3
A
Such a filter is most often used to
❏You can limit data update rates for applications in which rapid updates would be unnecessary or inappropriate. For example, a graphical user interface should typically not update itself more than a few times each second; more frequent updates can cause flickering or make it difficult for a human operator to perceive the correct values.
❏You can reduce the CPU requirements for
❏In some cases, you can reduce your network bandwidth utilization, because the writer can transparently discard unwanted data before it is even sent on the network.
5.2.3.1Implementation
DataReaders.
For more information about this QoS policy, consult the online API documentation. Open
ReadMe.html and select the API documentation for your language then select Modules, RTI Connext API Reference, Infrastructure, QoS Policies. For Ada1: open doc/html/api_ada/ index.html and select Infrastructure Module, DDSQosTypesModule.
You can specify the QoS policies either in your application code or in one or more XML files. Both mechanisms are functionally equivalent; the News example uses the XML mechanism. For more information, see the chapter on “Configuring QoS with XML” in the RTI Core Libraries and Utilities User’s Manual.
To specify a
<minimum_separation> <sec>1</sec> <nanosec>1</nanosec>
</minimum_separation> </time_based_filter> <deadline>
<period>
<sec>3</sec>
<nanosec>0</nanosec>
</period>
</deadline>
You can see this in the file USER_QOS_PROFILES.xml provided with the C, C++, Java, and Ada2 News example (uncomment it to specify a
At the same time we implement a
1.Ada support requires a separate
2.Ada support requires a separate
5.2.3.2Running & Verifying
Figure 5.4 shows some of the output after activating the filter:
Figure 5.4 Using a
 Article 1 sent at :31
Article 1 sent at :31
 Article 1 sent at :31
Article 1 sent at :31
Article 6 sent at :32.
Articles
Article 3 sent at :32.
 Article 2 filtered.
Article 2 filtered.
Because you set the
5.3Accessing Historical Data when Joining the Network
In Section 5.2, you learned how to specify which data on the network is of interest to your application. The same QoS parameters can also apply to
❏Volatile. Data is relevant to current subscribers only. Once it has been acknowledged (if reliable communication has been turned on), it can be removed from the service. This level of durability is the default; if you specify nothing, you will get this behavior.
❏Transient local. Data that has been sent may be relevant to
❏Transient. Data that has been sent may be relevant to
❏Persistent. Data that has been sent may be relevant to

network. It provides the greatest degree of assurance for your most critical data streams, because even if all data writers and all persistence server instances fail, your data can nevertheless be restored and made available to subscribers when you restart the persistence service.
As you can see, the level of durability indicates not only whether historical data will be made available to
5.3.1Implementation
To configure data durability, use the Durability QoS policy on your DataReader and/or DataWriter. The degrees of durability described in Section 5.3 are represented as an enumerated durability kind.
For more information about this QoS policy, consult the online API documentation. Open
ReadMe.html and select the API documentation for your language then select Modules, RTI Connext API Reference, Infrastructure, QoS Policies. For Ada1: open doc/html/api_ada/ index.html and select Infrastructure Module, DDSQosTypesModule.
You can specify the QoS policies either in your application code or in one or more XML files. Both mechanisms are functionally equivalent; the News example uses the XML mechanism. For more information, see the chapter on “Configuring QoS with XML” in the RTI Core Libraries and Utilities User’s Manual.
Here is an example of how to configure the Durability QoS policy in a QoS profile:
<durability>
<kind>
TRANSIENT_LOCAL_DURABILITY_QOS
</kind>
</durability>
You can see this in the News example (provided for C, C++, Java, and Ada) in the file
USER_QOS_PROFILES.xml.
The above configuration indicates that the DataWriter should maintain data it has published on behalf of
Durability, like some other QoS policies, has
5.3.2Running & Verifying
Run the NewsPublisher and wait several seconds. Then start the NewsSubscriber. Look at the time stamps printed next to the received data: you will see that the subscribing application receives data that was published before it started up.
Now do the same thing again, but first modify the configuration file by commenting the durability configuration. You will see that the subscribing application does not receive any data that was sent prior to when it joined the network.
1.Ada support requires a separate

5.4Caching Data Within the Middleware
When you receive data from the middleware in your subscribing application, you may be able to process all of the data immediately and then discard it. Frequently, however, you will need to store it somewhere in order to process it later. Since you’ve already expressed to the middleware how long your data remains relevant (see Subscribing Only to Relevant Data (Section 5.2)), wouldn’t it be nice if you could take advantage of the middleware’s own data cache rather than implementing your own? You can.
When a DataReader reads data from the network, it places the samples, in order, into its internal cache. When you’re ready to view that data (either because you received a notification that it was available or because you decided to poll), you use one of two families of methods:
❏take: Read the data from the cache and simultaneously remove it from that cache. Future access to that DataReader’s cache will not see any data that was previously taken from the cache. This behavior is similar to the behavior of “receive” methods provided by traditional messaging middleware implementations. The generated Ada example uses this method.
❏read: Read the data from the cache but leave it in the cache so that it can potentially be read again (subject to any lifespan or history depth you may have specified). The News example for C, C++ and Java uses this method.
When you read or take data from a DataReader, you can indicate that you wish to access all of the data in the cache, all up to a certain maximum number of samples, all of the new samples that you have never read before, and/or various other qualifiers. If your topic is keyed, you can choose to access the samples of all instances at once, or you can read/take one instance at a time. For more information about keys and instances, see Section 2.2.2, “Samples, Instances, and Keys” in the RTI Core Libraries and Utilities User’s Manual.

5.4.1Implementation
The call to read looks like this in C++:
DDS_ReturnCode_t result =
articles, |
// fill in data here |
articleInfos, |
// fill in parallel metadata here |
DDS_LENGTH_UNLIMITED, // any # articles
DDS_ANY_SAMPLE_STATE,
DDS_ANY_VIEW_STATE,
DDS_ANY_INSTANCE_STATE);
if (result == DDS_RETCODE_NO_DATA) { // nothing to read; go back to sleep
}
if (result != DDS_RETCODE_OK) { // an error occurred: stop reading throw std::runtime_error(
"A read error occurred: " + result);
}
// Process data...
It looks like this in Java:
try { _reader.read (
articles, // fill in data here
articleInfos, // fill in parallel metadata here ResourceLimitsQosPolicy.LENGTH_UNLIMITED, // any # articles SampleStateKind.ANY_SAMPLE_STATE, ViewStateKind.ANY_VIEW_STATE, InstanceStateKind.ANY_INSTANCE_STATE);
//Process data...
}catch (RETCODE_NO_DATA noData) {
//nothing to read; go back to sleep
}catch (RETCODE_ERROR ex) {
throw ex; // error: stop reading
} finally {
_reader.return_loan (articles, articleInfos);
}

And in Ada1:
declare
received_data : aliased DDS.KeyedString_Seq.Sequence; sample_info : aliased DDS.SampleInfo_Seq.Sequence;
begin reader.Read (
articles'Access,
reader.Return_Loan (articles, articleInfos);
for i in 1 .. DDS.KeyedString_Seq.Get_Length ( received_data'Access)
loop printArticle (
DDS.KeyedString_Seq.Get (received_data'Access, i),
DDS.SampleInfo_Seq.Get (sample_info'Access, i));
end loop;
reader.Return_Loan (
received_data'Access, sample_info'Access);
exception
when DDS.NO_DATA => null;
when DDS.ERROR =>
raise;
end;
The read method takes several arguments:
❏Data and SampleInfo sequences: The first two arguments to read or take are lists: for the samples themselves and, in parallel, for
If you would rather read the samples into your own memory instead of taking a loan from the middleware, simple pass in sequences in which the contents have already been deeply allocated. The DataReader will copy over the state of the objects you provide to it instead of loaning you its own objects. In this case, you do not need to call return_loan.
1.Ada support requires a separate

❏Number of samples to read: If you are only prepared to read a certain number of samples at a time, you can indicate that to the DataReader. In most cases, you will probably just use the constant LENGTH_UNLIMITED, which indicates that you are prepared to handle as many samples as the DataReader has available.
❏Sample state: The sample state indicates whether or not an individual sample has been observed by a previous call to read. (The News example uses this state to decide whether or not to append “(cached)” to the data it prints out.) By passing a sample state mask to the DataReader, you indicate whether you are interested in all samples, only those samples you’ve never seen before, or only those samples you have seen before. The most common value passed here is ANY_SAMPLE_STATE.
❏View state: The view state indicates whether the instance to which a sample belongs has been observed by a previous call to read or take. By passing a view state mask to the DataReader, you can indicate whether you’re interested in all instances, only those instances that you have never seen before (NEW instances), or only those instances that you have seen before (NOT_NEW instances). The most common value passed here is
ANY_VIEW_STATE.
❏Instance state: The instance state indicates whether the instance to which a sample belongs is still alive (ALIVE), whether it has been disposed (NOT_ALIVE_DISPOSED), or whether the DataWriter has simply gone away or stopped writing it without disposing it (NOT_ALIVE_NO_WRITERS). The most common value passed here is ANY_INSTANCE_STATE. For more information about the data lifecycle, consult the
RTI Core Libraries and Utilities User’s Manual and the online API documentation.
Unlike reading from a socket directly, or calling receive in JMS, a read or take is
Connext also offers additional variations on the read() and take() methods to allow you to view different “slices” of your data at a time:
❏You can view one instance at a time with read_instance(), take_instance(), read_next_instance(), and take_next_instance().
❏You can view a single sample at a time with read_next_sample() and take_next_sample().
For more information about these and other variations, see the online API documentation: open
ReadMe.html, select a language, and look under Modules, Subscription Module, DataReader Support, FooDataReader. For Ada, open doc/html/api_ada/index.html and look under Subscription Module, DDSReaderModule, DDS.Typed_DataReader_Generic.
5.4.2Running & Verifying
To see the difference between read() and take() semantics, replace “read” with “take” (the arguments are the same), rebuild the example, and run again. You will see that “(cached)” is never printed, because every sample will be removed from the cache as soon as it is viewed for the first time.
5.5Receiving Notifications When Data Delivery Is Late
Many applications expect data to be sent and received periodically (or
1.RTI Connext .NET language binding is currently supported for C# and C++/CLI.
2.Ada support requires a separate

may or may not indicate a serious problem, but is probably something about which the application would like to receive notifications. For example:
❏A vehicle may report its current position to its home base every second.
❏Each sensor in a sensor network reports a new reading every 0.5 seconds.
❏A radar reports the position of each object that it’s tracking every 0.2 seconds.
If any vehicle, any sensor, or any radar track fails to yield an update within its promised period, another part of the system, or perhaps its human operator, may need to take a corrective action.
(In addition to
5.5.1Implementation
Deadline enforcement is comprised of two parts: (1) QoS policies that specify the deadline contracts and (2) listener callbacks that are notified if those contracts are violated.
Deadlines are enforced independently for DataWriters and DataReaders. However, the Deadline QoS policy, like some other policies, has
5.5.1.1Offered Deadlines
A DataWriter promises to publish data at a certain rate by providing a finite value for the
Deadline QoS policy, either in source code or in one or more XML configuration files. (Both mechanisms are functionally equivalent; the News example in C, C++, Java, and Ada1 uses XML files. For more information about this mechanism, see the chapter on “Configuring QoS with XML” in the RTI Core Libraries and Utilities User’s Manual.)
The file USER_QOS_PROFILES.xml in the News example for C, C++, Java, and Ada contains the following Deadline QoS policy configuration, which applies to both DataWriters and
DataReaders:
<deadline>
<period>
<sec>2</sec>
<nanosec>0</nanosec>
</period>
</deadline>
The DataWriter thus promises to publish at least one data
If a period of two seconds elapses from the time the DataWriter last sent a sample of a particular instance, the writer’s
1. Ada support requires a separate

5.5.1.2Requested Deadlines
The DataReader declares that it expects to receive at least one data sample of each instance within a given period using the Deadline QoS policy. See the example XML configuration above.
If the declared deadline period elapses since the DataReader received the last sample of some instance, that reader’s
To install a DataReaderListener in C++:
DDSDataReader* reader =
topic,
DDS_DATAREADER_QOS_DEFAULT,
&_listener, |
// listener |
DDS_STATUS_MASK_ALL); // all callbacks
if (reader == NULL) {
throw std::runtime_error("Unable to create DataReader");
}
In Java, it looks like this:
DataReader reader = participant.create_datareader(
topic,
Subscriber.DATAREADER_QOS_DEFAULT,
new ArticleDeliveryStatusListener(), // listener
StatusKind.STATUS_MASK_ALL); // all callbacks
if (reader == null) {
throw new IllegalStateException("Unable to create DataReader");
}
And in Ada1:
declare
readerListener : ArticleDeliveryStatusListener.Ref_Access;
begin
reader := participant.Create_DataReader (topic.As_TopicDescription, DDS.Subscriber.DATAREADER_QOS_DEFAULT, readerListener'Unchecked_Access,
DDS.STATUS_MASK_ALL);
if reader = null then
Put_Line (Standard_Error,
"Unable to create DataReader");
return;
end if;
end;
1. Ada support requires a separate

There are two
❏Listener: The listener object itself, which must implement some subset of the callbacks defined by the DataReaderListener supertype.
❏Listener mask: Which of the callbacks you’d like to receive. In most cases, you will use one of the constants STATUS_MASK_ALL (if you are providing a
Let’s look at a very simple implementation of the on_requested_deadline_missed callback that prints the value of the key (i.e., the news outlet name) for the instance whose deadline was missed. You can see this in the News example provided with C, C++ and Java, and Ada.
In C++, the code looks like this:
void ArticleDeliveryStatusListener::on_requested_deadline_missed(
DDSDataReader* reader,
const DDS_RequestedDeadlineMissedStatus& status) {
DDS_KeyedString keyHolder;
DDSKeyedStringDataReader* typedReader =
DDSKeyedStringDataReader::narrow(reader);
std::cout
<<
<<keyHolder.key
<<std::endl;
}
In Java:
public void on_requested_deadline_missed( DataReader reader, RequestedDeadlineMissedStatus status) {
KeyedString keyHolder = new KeyedString();
reader.get_key_value_untyped(keyHolder, status.last_instance_handle);
System.out.println(
}
And in Ada:
procedure On_Requested_Deadline_Missed
(Self : not null access Ref;
The_Reader : in DDS.DataReader.Ref'Class;
Status : in DDS.RequestedDeadlineMissedStatus)
is
pragma Unreferenced (Self);
pragma Unreferenced (The_Reader);
pragma Unreferenced (Status);
begin
Put_Line
5.5.2Running & Verifying
Modify the file USER_QOS_PROFILES.xml to decrease the deadline to one second:
<deadline>
<period>
<sec>1</sec>
<nanosec>0</nanosec>
</period>
</deadline>
Note that, if you have a DataReader- or
You will see output similar to Figure 5.5.
Figure 5.5 Using a Shorter Deadline

Chapter 6 Design Patterns for High Performance
In this chapter, you will learn how to implement some common
We will build on the examples used in Building and Running “Hello, World” (Section 3.1) to demonstrate the different
The QoS parameters do not depend on the language used for your application, and seldom on the operating system (there are few key exceptions), so you should be able to use the XML files with the example in the language of your choice.
This chapter describes:
❏Building and Running the Code Examples
❏High Throughput for Streaming Data
❏Streaming Data over Unreliable Network Connections
1. Dynamic types are not supported when using Ada 2005 Language Support.
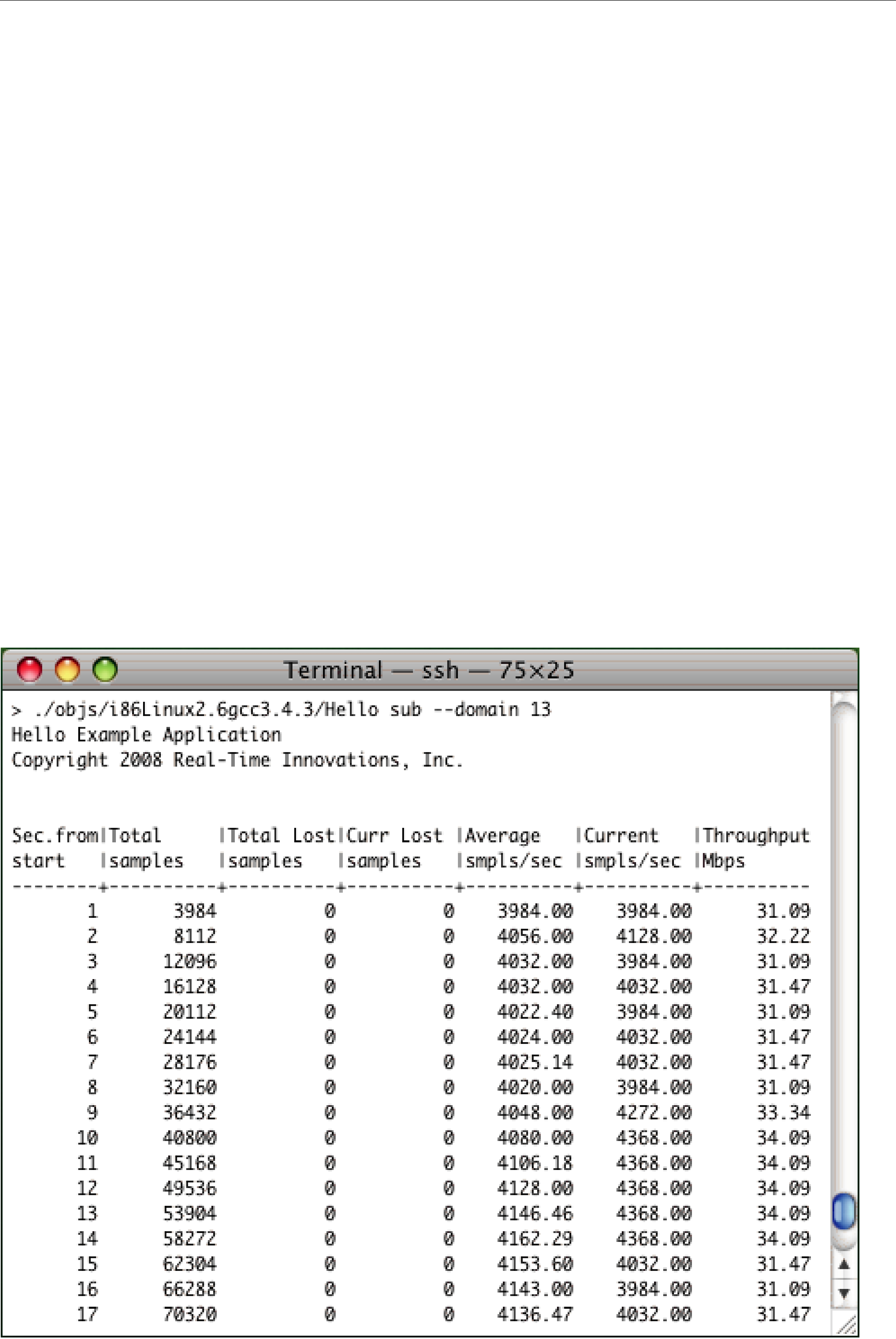
6.1Building and Running the Code Examples
You can find the source for the Hello_builtin example for Java in ${NDDSHOME}/example/ JAVA/Hello_builtin; the equivalent source code in other supported languages is in the directories ${NDDSHOME}/example/<language>. The Hello_idl and Hello_dynamic examples are in parallel directories under ${NDDSHOME}/example/<language>.
The examples perform these steps:
1.Parse their
2.Check if the Quality of Service (QoS) file can be located.
The XML file that sets the Quality of Service (QoS) parameters is either loaded from the file USER_QOS_PROFILES.xml in the current directory of the program, or from the environment variable NDDS_QOS_PROFILES. For more information on how to use QoS profiles, see the chapter on "Configuring QoS with XML" in the RTI Core Libraries and Utilities User's Manual.
3.On the publishing side, send text strings as fast as possible, prefixing each one with a serial number.
4.On the subscribing side, receive these strings, keeping track of the highest number seen, as well as other statistics. Print these out periodically.
Figure 6.1 Example Output from the Subscribing Application in C, C++, C# or Java
The steps for compiling and running the program are the same as mentioned in Building and Running “Hello, World” (Section 3.1).
Run the publisher and subscriber from the ${NDDSHOME}/example/<language>/ Hello_builtin directory using one of the QoS profile files provided in ${NDDSHOME}/ example/QoS by copying it into your current working directory with the file name USER_QOS_PROFILES.xml. You should see output like the following from the subscribing application:
Understanding the Performance Results
You will see several columns in the
❏Seconds from start: The number of seconds the subscribing application has been running. It will print out one line per second.
❏Total samples: The number of data samples that the subscribing application has received since it started running.
❏Total lost samples: The number of samples that were lost in transit and could not be re- paired, since the subscribing application started running. If you are using a QoS profile configured for strict reliability, you can expect this column to always display 0. If you are running in
❏Current lost samples: The number of samples that were lost in transit and could not be repaired, since the last status line was printed. See the description of the previous column for information about what values to expect here.
❏Average samples per second: The mean number of data samples received per second since the subscribing application started running. By default, these example applications send data samples that are 1 KB in size. (You can change this by passing a different size, in bytes, to the publishing application with
❏Current samples per second: The number of data samples received since the subscribing application printed the last status line.
❏Throughput megabits per second: The throughput from the publishing application to the subscribing application, in bits per second, since the subscribing application printed the previous status line. The value in this column is equivalent to the current samples per second multiplied by the number of bits in an individual sample.
With small sample sizes, the fixed "cost" of traversing your operating system's network stack is greater than the cost of actually transmitting the data; as you increase the sample size, you will see the throughput more closely approach the theoretical throughput of your network.
By batching multiple data samples into a single network packet, as the
Is this the best possible performance?
The performance of an application depends heavily on the operating system, the network, and how it configures and uses the middleware. This example is just a starting point; tuning is important for a production application. RTI can help you get the most out of your platform and the middleware.
To get a sense for how an application's behavior changes with different QoS contracts, try the other provided example QoS profiles and see how the printed results change.

6.2Reliable Messaging
Packets sent by a middleware may be lost by the physical network or dropped by routers, switches and even the operating system of the subscribing applications when buffers become full. In reliable messaging, the middleware keeps track of whether or not data sent has been received by subscribing applications, and will resend data that was lost on transmission.
Like most reliable protocols (including TCP), the reliability protocol used by RTI uses additional packets on the network, called metadata, to know when user data packets are lost and need to be resent. RTI offers the user a comprehensive set of tunable parameters that control how many and how often metadata packets are sent, how much memory is used for internal buffers that help overcome intermittent data losses, and how to detect and respond to a reliable subscriber that either falls behind or otherwise disconnects.
When users want applications to exchange messages reliably, there is always a need to
If the publisher writes samples faster than subscribers can acknowledge receiving, this internal buffer will eventually be completely filled, exhausting all the available
Although the size of those buffers can be controlled from the QoS, you can also use QoS to control what Connext will do when the space available in one of those buffers is exhausted. There are two possible scenarios for both the publisher and subscriber:
Publishing side: If write() is called and there is no more room in the DataWriter’s buffer, Connext can:
1.Temporarily block the write operation until there is room on this buffer (for example, when one or more samples is acknowledged to have been received from all the subscribers).
2.Drop the oldest sample from the queue to make room for the new one.
Subscribing side: If a sample is received (from a publisher) and there is no more room on the
DataReader’s buffer:
1.Drop the sample as if it was never received. The subscribing application will send a negative acknowledgement requesting that the sample be resent.
2.Drop the oldest sample from the queue to make room for the new one.
6.2.1Implementation
There are many variables to consider, and finding the optimum values to the queue size and the right policy for the buffers depends on the type of data being exchanged, the rate of which the data is written, the nature of the communication between nodes and various other factors.
The RTI Core Libraries and Utilities User’s Manual dedicates an entire chapter to the reliability protocol, providing details on choosing the correct values for the QoS based on the system configuration. For more information, refer to Chapter 10 in the User’s Manual.
The following sections highlight the key QoS settings needed to achieve strict reliability. In the reliable.xml QoS profile file, you will find many other settings besides the ones described here.
1.Connext also supports reliability based only on negative acknowledgements
A detailed description of these QoS is outside the scope of this document, and for further information, refers to the comments in the QoS profile and in the User’s Manual.
6.2.1.1Enable Reliable Communication
The QoS that control the kind of communication is the Reliability QoS of the DataWriter and
DataReader:
<datawriter_qos>
...
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind> <max_blocking_time>
<sec>5</sec>
<nanosec>0</nanosec> </max_blocking_time>
</reliability>
...
</datawriter_qos>
...
<datareader_qos> <reliability>
<kind>RELIABLE_RELIABILITY_QOS</kind> </reliability>
</datareader_qos>
This section of the QoS file enables reliability on the DataReader and DataWriter, and tells the middleware that a call to write() may block up to 5 seconds if the DataWriter’s cache is full of unacknowledged samples. If no space opens up in 5 seconds, write() will return with a timeout indicating that the write operation failed and that the data was not sent.
6.2.1.2Set History To KEEP_ALL
The History QoS determines the behavior of a DataWriter or DataReader when its internal buffer fills up. There are two kinds:
❏KEEP_ALL: The middleware will attempt to keep all the samples until they are acknowledged (when the DataWriter’s History is KEEP_ALL), or taken by the application (when the DataReader’s History is KEEP_ALL).
❏KEEP_LAST: The middleware will discard the oldest samples to make room for new samples. When the DataWriter’s History is KEEP_LAST, samples are discarded when a new call to write() is performed. When the DataReader’s History is KEEP_LAST, samples in the receive buffer are discarded when new samples are received. This kind of history is associated with a depth that indicates how many historical samples to retain.
<datawriter_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
...
</datawriter_qos>
...
<datareader_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
...
</datareader_qos>
The above section of the QoS profile tells RTI to use the policy KEEP_ALL for both DataReader and DataWriter.
6.2.1.3Controlling Middleware Resources
With the ResourceLimits QosPolicy, you have full control over the amount of memory used by the middleware. In the example below, we specify that both the reader and writer will store up to 10 samples (if you use a History kind of KEEP_LAST, the values specified here must be consistent with the value specified in the History’s depth).
<datawriter_qos> <resource_limits>
<max_samples>10</max_samples> </resource_limits>
...
</datawriter_qos>
...
<datareader_qos> <resource_limits>
<max_samples>2</max_samples> </resource_limits>
...
</datareader_qos>
The above section tells RTI to allocate a buffer of 10 samples for the DataWriter and 2 for the DataReader. If you do not specify any value for max_samples, the default behavior is for the middleware to allocate as much space as it needs.
One important function of the Resource Limits policy, when used in conjunction with the Reliability and History policies, is to govern how far "ahead" of its DataReaders a DataWriter may get before it will block, waiting for them to catch up. In many systems, consuming applications cannot acknowledge data as fast as its producing applications can put new data on the network. In such cases, the Resource Limits policy provides a throttling mechanism that governs how many
If you see that your reliable publishing application is using an unacceptable amount of memory, you can specify a finite value for max_samples. By doing this, you restrain the size of the DataWriter's cache, causing it to use less memory; however, a smaller cache will fill more quickly, potentially causing the writer to block for a time when sending, decreasing throughput. If decreased throughput proves to be an issue, you can tune the reliability protocol to process

acknowledgements and repairs more aggressively, allowing the writer to clear its cache more effectively. A full discussion of the relevant reliability protocol parameters is beyond the scope of this example. However, you can find a useful example in high_throughput.xml. Also see the documentation for the DataReaderProtocol and DataWriterProtocol QoS policies in the
6.3High Throughput for Streaming Data
This design pattern is useful for systems that produce a large number of small messages at a high rate.
In such cases, there is a small but measurable overhead in sending (and in the case of reliable communication, acknowledging) each message separately on the network. It is more efficient for the system to manage many samples together as a group (referred to in the API as a batch) and then send the entire group in a single network packet. This allows Connext to minimize the overhead of building a datagram and traversing the network stack.
Batching increases throughput when writing small samples at a high rate. As seen in Figure 6.2, throughput can be increased
Figure 6.2 Benefits of Batching
Batching delivers tremendous benefits for messages of small size.

Figure 6.3 Benefits of Batching: Sample Rates
A subset of the batched throughput data above, expressed in terms of samples per second.
Collecting samples into a batch implies that they are not sent on the network (flushed) immediately when the application writes them; this can potentially increase latency. However, if the application sends data faster than the network can support, an increased share of the network's available bandwidth will be spent on acknowledgements and resending dropped data. In this case, reducing that
Batching is particularly useful when the system has to send a large number of small messages at a fast rate. Without this feature enabled, you may observe that your maximum throughput is less than the maximum bandwidth of your network. Simultaneously, you may observe high CPU loads. In this situation, the bottleneck in your system is the ability of the CPU to send packets through the OS network stack.
For example, in some algorithmic trading applications, market data updates arrive at a rate of from tens of thousands of messages per second to over a million; each update is some hundreds of bytes in size. It is often better to send these updates in batches than to publish them individually. Batching is also useful when sending a large number of small samples over a connection where the bandwidth is severely constrained.
6.3.1Implementation
RTI can automatically flush batches based on the maximum number of samples, the total batch size, or elapsed time since the first sample was placed in the batch, whichever comes first. Your application can also flush the current batch manually. Batching is completely transparent on the subscribing side; no special configuration is necessary.
For more information on batching, see the RTI Core Libraries and Utilities User’s Manual (Section 6.5.1) or API Reference HTML documentation (the Batch QosPolicy is described in the Infrastructure Module).
Using the batching feature is

Figure 6.4 Batching Implementation
RTI collects samples in a batch until the batch is flushed.
For example, to enable batching with a batch size of 100 samples, set the following QoS in your XML configuration file:
<datawriter_qos>
...
<batch>
<enable>true</enable>
<max_samples>100</max_samples>
</batch>
...
</datawriter_qos>
To enable batching with a maximum batch size of 8K bytes:
<datawriter_qos>
...
<batch>
<enable>true</enable>
<max_data_bytes>8192</max_data_bytes>
</batch>
...
</datawriter_qos>
To force the DataWriter to send whatever data is currently stored in a batch, use the DataWriter’s flush() operation.
6.3.2Running & Verifying
1.To run and verify the new QoS parameters, first run Hello_builtin using a simple reliable
Figure 6.5 Initial Performance Results
2.Next, run the example again with a configuration that includes batching. Copy high_throughput.xml from ${NDDSHOME}/example/QoS to ${NDDSHOME}/ example/<language>/Hello_builtin and rename it to USER_QOS_PROFILES.xml.
3.Run Hello_builtin again. Verify that the throughput numbers have improved.
Figure 6.6 Improved Performance Results

6.4Streaming Data over Unreliable Network Connections
Systems face unique challenges when sending data over lossy networks that also have high- latency and
For example, the transmission delay in satellite connections can be as much as 500 milliseconds to 1 second, which makes such a connection unsuitable for applications or middleware tuned for
Connext is capable of maintaining liveliness and
6.4.1Implementation
When designing a system that demands reliability over a network that is lossy and has high latency and low throughput, it is critical to consider:
❏How much data you send at one time (e.g., your sample or batch size).
❏How often you send it.
❏The tuning of the reliability protocol for managing meta- and repair messages.
It is also important to be aware of whether your network supports multicast communication; if it does not, you may want to explicitly disable it in your middleware configuration (e.g., by using the NDDS_DISCOVERY_PEERS environment variable or setting the initial_peers and multicast_receive_address in your Discovery QoS policy; see the online API documentation).
6.4.1.1Managing Your Sample Size
Pay attention to your packet sizes to minimize or avoid
The exact size of the sample on the wire will depend not only on the size of your data fields, but also on the amount of padding introduced to ensure alignment while serializing the data.
Figure 6.7 shows how an application's effective throughput (as a percentage of the theoretical capacity of the link) increases as the amount of data in each network packet increases. To put this relationship in another way: when transmitting a packet is expensive, it's advantageous to put as much data into it as possible. However, the trend reverses itself when the packet size becomes larger than the maximum transmission unit (MTU) of the physical network.

Figure 6.7 Example Throughput Results over VSat Connection
Correlation between sample size and bandwidth usage for a satellite connection with 3% packet loss ratio.
To understand why this occurs, remember that data is sent and received at the granularity of application samples but dropped at the level of transport packets. For example, an IP datagram 10 KB in size must be fragmented into seven
On an
To solve this problem, you need to repair data at the granularity at which it was lost: you need, not
<datawriter_qos>
...
<publish_mode> <kind>ASYNCHRONOUS_PUBLISH_MODE_QOS</kind> <flow_controller_name>
DDS_DEFAULT_FLOW_CONTROLLER_NAME </flow_controller_name>
</publish_mode>
...
</datawriter_qos>
1. Suppose that a physical network delivers a 1 KB frame successfully 97% of the time. Now suppose that an appli- cation sends a 64 KB datagram. The likelihood that all fragments will arrive at their destination is 97% to the 64th power, or less than 15%.

<participant_qos>
...
<property>
<value>
<element>
<name> dds.transport.UDPv4.builtin.parent.message_size_max
</name>
<value>1500</value>
</element>
</value>
</property>
...
</participant_qos>
The DomainParticipant's dds.transport.UDPv4.builtin.parent.message_size_max property sets the maximum size of a datagram that will be sent by the UDP/IPv4 transport. (If your application interfaces to your network over a transport other than UDP/IPv4, the name of this property will be different.) In this case, it is limiting all datagrams to the MTU of the link (assumed, for the sake of this example, to be equal to the MTU of Ethernet).
At the same time, the DataWriter is configured to send its samples on the network, not synchronously when write() is called, but in a middleware thread. This thread will "flow" datagrams onto the network at a rate determined by the FlowController1 identified by the flow_controller_name. In this case, the FlowController is a
6.4.1.2Acknowledge and Repair Efficiently
Piggyback heartbeat with each sample. A DataWriter sends
<datawriter_qos>
...
<resource_limits>
20
</resource_limits>
1. FlowControllers are not supported when using Ada 2005 Language Support.
<writer_resource_limits>
20
</writer_resource_limits>
<protocol> <rtps_reliable_writer>
<heartbeats_per_max_samples>
20
<rtps_reliable_writer> </protocol>
...
</datawriter_qos>
The heartbeats_per_max_samples parameter controls how often the middleware will piggyback a heartbeat onto a data message: if the middleware is configured to cache 10 samples, for example, and heartbeats_per_max_samples is set to 5, a heartbeat will be piggybacked unto every other sample. If heartbeats_per_max_samples is set equal to max_samples, this means that a heartbeat will be sent with each sample.
6.4.1.3Make Sure Repair Packets Don’t Exceed Bandwidth Limitation
Applications can configure the maximum amount of data that a DataWriter will resend at a time using the max_bytes_per_nack_response parameter. For example, if a DataReader sends a negative acknowledgement (NACK) indicating that it missed 20 samples, each 10 KB in size, and max_bytes_per_nack_response is set to 100 KB, the DataWriter will only send the first 10 samples. The DataReader will have to NACK again to receive the remaining 10 samples.
In the following example, we limit the number of bytes so that we will never send more data than a 256 Kb/s,
<datawriter_qos>
...
<protocol>
<rtps_reliable_writer> <max_bytes_per_nack_response>
28000
</max_bytes_per_nack_response> </rtps_reliable_writer>
</protocol>
...
</datawriter_qos>
6.4.1.4Use Batching to Maximize Throughput for Small Samples
If your application is sending data continuously, consider batching small samples to decrease the
For more information on how to configure throughput for small samples, see High Throughput for Streaming Data (Section 6.3).