SQL Filter Expression Notation
A SQL filter expression is similar to the WHERE clause in SQL. The SQL expression format provided by Connext DDS also supports the MATCH operator as an extended operator (see SQL Extension: Regular Expression Matching).
The following sections provide more information:
- Example SQL Filter Expressions
- SQL Grammar
- Token Expressions
- Type Compatibility in the Predicate
- SQL Extension: Regular Expression Matching
- Composite Members
- Strings
- Enumerations
- Pointers
- Arrays
- Sequences
Example SQL Filter Expressions
Assume that you have a Topic with two floats, X and Y, which are the coordinates of an object moving inside a rectangle measuring 200 x 200 units. This object moves quite a bit, generating lots of DDS samples that you are not interested in. Instead you only want to receive DDS samples outside the middle of the rectangle, as seen in Filtering Example . That is, you want to filter out data points in the gray box.
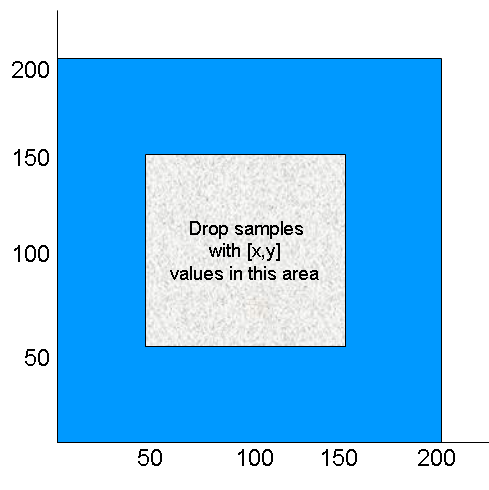
The filter expression would look like this (remember the expression is written so that DDS samples that we do want will pass):
"(X < 50 or X > 150) and (Y < 50 or Y > 150)"
While this filter works, it cannot be changed after the ContentFilteredTopic has been created. Suppose you would like the ability to adjust the coordinates that are considered outside the acceptable range (changing the size of the gray box). You can achieve this by using filter parameters. An more flexible way to write the expression is this:
"(X < %0 or X > %1) and (Y < %2 or Y > %3)"
Recall that when you create a ContentFilteredTopic (see Creating ContentFilteredTopics), you pass a expression_parameters string sequence as one of the parameters. Each element in the string sequence corresponds to one argument.
See the String and Sequence Support sections of the API Reference HTML documentation (from the Modules page, select RTI Connext DDS API Reference, Infrastructure Module).
In C++, the filter parameters could be assigned like this:
FilterParameter[0] = "50"; FilterParameter[1] = "150"; FilterParameter[2] = "50"; FilterParameter[3] = "150";
With these parameters, the filter expression is identical to the first approach. However, it is now possible to change the parameters by calling set_expression_parameters(). For example, perhaps you decide that you only want to see data points where X < 10 or X > 190. To make this change:
FilterParameter[0] = 10 FilterParameter[1] = 190 set_expression_parameters(....)
The new filter parameters will affect all DataReaders that have been created with this ContentFilteredTopic.
SQL Grammar
This section describes the subset of SQL syntax, in Backus–Naur Form (BNF), that you can use to form filter expressions.
The following notational conventions are used:
NonTerminals are typeset in italics.
'Terminals' are quoted and typeset in a fixed-width font. They are written in upper case in most cases in the BNF-grammar below, but should be case insensitive.
TOKENS are typeset in bold.
The notation (element // ',') represents a non-empty, comma-separated list of elements.
Expression ::= FilterExpression
| TopicExpression
| QueryExpression
.
FilterExpression ::= Condition
TopicExpression ::= SelectFrom { Where } ';'
QueryExpression ::= { Condition }{ 'ORDER BY' (FIELDNAME // ',') }
.
SelectFrom ::= 'SELECT' Aggregation 'FROM' Selection
.
Aggregation ::= '*'
| (SubjectFieldSpec // ',')
.
SubjectFieldSpec ::= FIELDNAME
| FIELDNAME 'AS' IDENTIFIER
| FIELDNAME IDENTIFIER
.
Selection ::= TOPICNAME
| TOPICNAME NaturalJoin JoinItem
.
JoinItem ::= TOPICNAME
| TOPICNAME NaturalJoin JoinItem
| '(' TOPICNAME NaturalJoin JoinItem ')'
.
NaturalJoin ::= 'INNER JOIN'
| 'INNER NATURAL JOIN'
| 'NATURAL JOIN'
| 'NATURAL INNER JOIN'
.
Where ::= 'WHERE' Condition
.
Condition ::= Predicate
| Condition 'AND' Condition
| Condition 'OR' Condition
| 'NOT' Condition
| '(' Condition ')'
.
Predicate ::= ComparisonPredicate
| BetweenPredicate
.
ComparisonPredicate ::= ComparisonTerm RelOp ComparisonTerm
.
ComparisonTerm ::= FieldIdentifier
| Parameter
.
BetweenPredicate ::= FieldIdentifier 'BETWEEN' Range
| FieldIdentifier 'NOT BETWEEN' Range
.
FieldIdentifier ::= FIELDNAME
| IDENTIFIER
.
RelOp ::= '=' | '>' | '>=' | '<' | '<=' | '<>' | 'LIKE' | 'MATCH'
.
Range ::= Parameter 'AND' Parameter
.
Parameter ::= INTEGERVALUE
| CHARVALUE
| FLOATVALUE
| STRING
| ENUMERATEDVALUE
| BOOLEANVALUE
| PARAMETER
INNER JOIN, INNER NATURAL JOIN, NATURAL JOIN, and NATURAL INNER JOIN are all aliases, in the sense that they have the same semantics. They are all supported because they all are part of the SQL standard.
Token Expressions
The syntax and meaning of the tokens used in SQL grammar is described as follows:
IDENTIFIER—An identifier for a FIELDNAME, defined as any series of characters 'a', ..., 'z', 'A', ..., 'Z', '0', ..., '9', '_' but may not start with a digit.
IDENTIFIER: LETTER (PART_LETTER)*
where LETTER: [ "A"-"Z","_","a"-"z" ] PART_LETTER: [ "A"-"Z","_","a"-"z","0"-"9" ]
FIELDNAME—A reference to a field in the data structure. A dot '.' is used to navigate through nested structures. The number of dots that may be used in a FIELDNAME is unlimited. The FIELDNAME can refer to fields at any depth in the data structure. The names of the field are those specified in the IDL definition of the corresponding structure, which may or may not match the fieldnames that appear on the language-specific (e.g., C/C++, Java) mapping of the structure. To reference the n+1 element in an array or sequence, use the notation '[n]', where n is a natural number (zero included). FIELDNAME must resolve to a primitive IDL type; that is either boolean, octet, (unsigned) short, (unsigned) long, (unsigned) long long, float double, char, wchar, string, wstring, or enum.
FIELDNAME: FieldNamePart ( "." FieldNamePart )*
where FieldNamePart : IDENTIFIER ( "[" Index "]" )* Index> : (["0"-"9"])+ | ["0x","0X"](["0"-"9", "A"-"F", "a"-"f"])+
Primitive IDL types referenced by FIELDNAME are treated as different types in Predicate according to the following table:
|
Predicate Data Type |
IDL Type |
|
BOOLEANVALUE |
boolean |
|
INTEGERVALUE |
octet, (unsigned) short, (unsigned) long, (unsigned) long long |
|
FLOATVALUE |
float, double |
|
CHARVALUE |
char, wchar |
|
STRING |
string, wstring |
|
ENUMERATEDVALUE |
enum |
TOPICNAME—An identifier for a topic, and is defined as any series of characters 'a', ..., 'z', 'A', ..., 'Z', '0', ..., '9', '_' but may not start with a digit.
TOPICNAME : IDENTIFIER
INTEGERVALUE—Any series of digits, optionally preceded by a plus or minus sign, representing a decimal integer value within the range of the system. 'L' or 'l' must be used for long long, otherwise long is assumed. A hexadecimal number is preceded by 0x and must be a valid hexadecimal expression.
INTEGERVALUE : (["+","-"])? (["0"-"9"])+ [("L","l")]?
| (["+","-"])? ["0x","0X"](["0"-"9",
"A"-"F", "a"-"f"])+ [("L","l")]?
CHARVALUE—A single character enclosed between single quotes.
CHARVALUE : "'" (~["'"])? "'"
FLOATVALUE—Any series of digits, optionally preceded by a plus or minus sign and optionally including a floating point ('.'). 'F' or 'f' must be used for float, otherwise double is assumed. A power-of-ten expression may be postfixed, which has the syntax en or En, where n is a number, optionally preceded by a plus or minus sign.
FLOATVALUE : (["+","-"])? (["0"-"9"])* (".")? (["0"-"9"])+
(EXPONENT)?[("F",’f’)]?
where EXPONENT: ["e","E"] (["+","-"])? (["0"-"9"])+
STRING—Any series of characters encapsulated in single quotes, except the single quote itself.
STRING : "'" (~["'"])* "'"
ENUMERATEDVALUE—A reference to a value declared within an enumeration. Enumerated values consist of the name of the enumeration label enclosed in single quotes. The name used for the enumeration label must correspond to the label names specified in the IDL definition of the enumeration.
ENUMERATEDVALUE : "'" ["A" - "Z", "a" - "z"]
["A" - "Z", "a" - "z", "_", "0" - "9"]* "'"
BOOLEANVALUE—Can either be TRUE or FALSE, and is case insensitive.
BOOLEANVALUE : ["TRUE","FALSE"]
PARAMETER—Takes the form %n, where n represents a natural number (zero included) smaller than 100. It refers to the (n + 1)th argument in the given context. This argument can only be in primitive type value format. It cannot be a FIELDNAME.
PARAMETER : "%" (["0"-"9"])+
Type Compatibility in the Predicate
As seen in , only certain combinations of type comparisons are valid in the Predicate.
|
|
BOOLEAN |
INTEGER |
FLOAT |
CHAR |
STRING |
ENUMERATED |
|
BOOLEAN |
YES |
|
|
|
|
|
|
INTEGERVALUE |
|
YES |
YES |
|
|
|
|
FLOATVALUE |
|
YES |
YES |
|
|
|
|
CHARVALUE |
|
|
|
YES |
YES |
YES |
|
STRING |
|
|
|
YES |
YES 1See SQL Extension: Regular Expression Matching on page 1. |
YES |
|
ENUMERATED |
|
YES |
|
SQL Extension: Regular Expression Matching
The relational operator MATCH may only be used with string fields. The right-hand operator is a string pattern. A string pattern specifies a template that the left-hand field must match.
MATCH is case-sensitive. These characters have special meaning: ,/?*[]-^!\%
The pattern allows limited "wild card" matching under the rules in .
The syntax is similar to the POSIX® fnmatch syntax5See http://www.opengroup.org/onlinepubs/000095399/functions/fnmatch.html.. The MATCH syntax is also similar to the 'subject' strings of TIBCO Rendezvous®. Some example expressions include:
"symbol MATCH 'NASDAQ/[A-G]*'" "symbol MATCH 'NASDAQ/GOOG,NASDAQ/MSFT'"
|
Character |
Meaning |
|
, |
A , separates a list of alternate patterns. The field string is matched if it matches one or more of the patterns. |
|
/ |
A / in the pattern string matches a / in the field string. It separates a sequence of mandatory substrings. |
|
? |
A ? in the pattern string matches any single non-special characters in the field string. |
|
* |
A * in the pattern string matches 0 or more non-special characters in field string. |
|
% |
This special character is used to designate filter expression parameters. |
|
\ |
(Not supported) Escape character for special characters. |
|
[charlist] |
Matches any one of the characters in charlist. |
|
[!charlist] or [^charlist] |
(Not supported) Matches any one of the characters not in charlist. |
|
[s-e] |
Matches any character from s to e, inclusive. |
|
[!s-e] or [^s-e] |
(Not supported) Matches any character not in the interval s to e. |
Composite Members
Any member can be used in the filter expression, with the following exceptions:
- 128-bit floating point numbers (long doubles) are not supported
- bitfields are not supported
- LIKE is not supported
Composite members are accessed using the familiar dot notation, such as "x.y.z > 5". For unions, the notation is special due to the nature of the IDL union type.
On the publishing side, you can access the union discriminator with myunion._d and the actual member with myunion._u.mymember. If you want to use a ContentFilteredTopic on the subscriber side and filter a DDS sample with a top-level union, you can access the union discriminator directly with _d and the actual member with mymember in the filter expression.
Strings
The filter expression and parameters can use IDL strings. String constants must appear between single quotation marks (').
For example:
" fish = 'salmon' "
Strings used as parameter values must contain the enclosing quotation marks (') within the parameter value; do not place the quotation marks within the expression statement. For example, the expression " symbol MATCH %0 " with parameter 0 set to " 'IBM' " is legal, whereas the expression " symbol MATCH '%0' " with parameter 0 set to " IBM " will not compile.
Enumerations
A filter expression can use enumeration values, such as GREEN, instead of the numerical value. For example, if x is an enumeration of GREEN, YELLOW and RED, the following expressions are valid:
"x = 'GREEN'" "X < 'RED'"
Pointers
Pointers can be used in filter expressions and are automatically dereferenced to the correct value.
For example:
struct Point {
long x;
long y;
};
struct Rectangle {
Point *u_l;
Point *l_r;
};
The following expression is valid on a Topic of type Rectangle:
"u_l.x > l_r.x"
Arrays
Arrays are accessed with the familiar [] notation.
For example:
struct ArrayType {long value[255][5];
};
The following expression is valid on a Topic of type ArrayType:
"value[244][2] = 5"
In order to compare an array of bytes(octets in idl), instead of comparing each individual element of the array using [] notation, Connext DDS provides a helper function, hex(). The hex() function can be used to represent an array of bytes (octets in IDL). To use the hex() function, use the notation &hex() and pass the byte array as a sequence of hexadecimal values.
For example:
&hex (07 08 09 0A 0B 0c 0D 0E 0F 10 11 12 13 14 15 16)
Here the leftmost-pair represents the byte and index 0.
Note: If the length of the octet array represented by the hex() function does not match the length of the field being compared, it will result in a compilation error.
For example:
struct ArrayType {
octet value[2];
};
The following expression is valid:
"value = &hex(12 0A)"
Sequences
Sequence elements can be accessed using the () or [] notation.
For example:
struct SequenceType {
sequence<long> s;
};
The following expressions are valid on a Topic of type SequenceType:
"s(1) = 5" "s[1] = 5"
© 2016 RTI