6.3 High Throughput for Streaming Data
This design pattern is useful for systems that produce a large number of small messages at a high rate.
In such cases, there is a small but measurable overhead in sending (and in the case of reliable communication, acknowledging) each message separately on the network. It is more efficient for the system to manage many DDS samples together as a group (referred to in the API as a batch) and then send the entire group in a single network packet. This allows Connext DDS to minimize the overhead of building a datagram and traversing the network stack.
Batching increases throughput when writing small DDS samples at a high rate. As seen in Figure 6.3: Benefits of Batching: Sample Rates, throughput can be increased several-fold, much more closely approaching the physical limitations of the underlying network transport.
Figure 6.2: Benefits of Batching
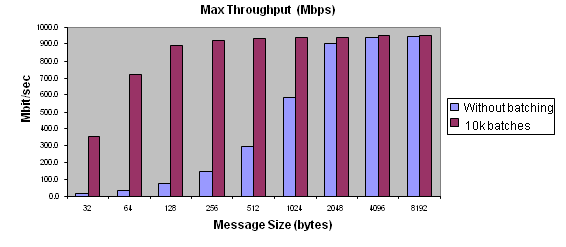
Batching delivers tremendous benefits for messages of small size.
Figure 6.3: Benefits of Batching: Sample Rates
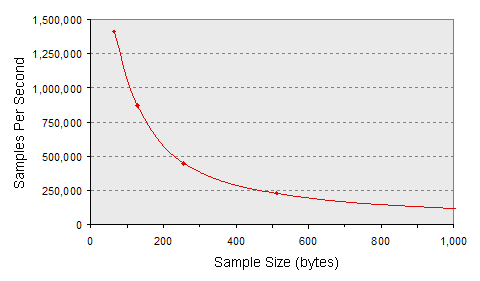
A subset of the batched throughput data above, expressed in terms of DDS samples per second.
Collecting DDS samples into a batch implies that they are not sent on the network (flushed) immediately when the application writes them; this can potentially increase latency. However, if the application sends data faster than the network can support, an increased share of the network's available bandwidth will be spent on acknowledgments and resending dropped data. In this case, reducing that meta-data overhead by turning on batching could decrease latency even while increasing throughput. Only an evaluation of your system's requirements and a measurement of its actual performance will indicate whether batching is appropriate. Fortunately, it is easy to enable and tune batching, as you will see below.
Batching is particularly useful when the system has to send a large number of small messages at a fast rate. Without this feature enabled, you may observe that your maximum throughput is less than the maximum bandwidth of your network. Simultaneously, you may observe high CPU loads. In this situation, the bottleneck in your system is the ability of the CPU to send packets through the OS network stack.
For example, in some algorithmic trading applications, market data updates arrive at a rate of from tens of thousands of messages per second to over a million; each update is some hundreds of bytes in size. It is often better to send these updates in batches than to publish them individually. Batching is also useful when sending a large number of small DDS samples over a connection where the bandwidth is severely constrained.
6.3.1 Implementation
RTI can automatically flush batches based on the maximum number of DDS samples, the total batch size, or elapsed time since the first DDS sample was placed in the batch, whichever comes first. Your application can also flush the current batch manually. Batching is completely transparent on the subscribing side; no special configuration is necessary.
Figure 6.4: Batching Implementation

RTI collects DDS samples in a batch until the batch is flushed.
For more information on batching, see the RTI Connext DDS Core Libraries User's Manual (Section 6.5.2) or API Reference HTML documentation (the Batch QosPolicy is described in the Infrastructure Module).
Using the batching feature is simple—just modify the QoS in the publishing application’s configuration file.
For example, to enable batching with a batch size of 100 DDS samples, set the following QoS in your XML configuration file:
<datawriter_qos>
...
<batch>
<enable>true</enable>
<max_samples>100</max_samples>
</batch>
...
</datawriter_qos>
To enable batching with a maximum batch size of 8K bytes:
<datawriter_qos>
...
<batch>
<enable>true</enable>
<max_data_bytes>8192</max_data_bytes>
</batch>
...
</datawriter_qos>
To force the DataWriter to send whatever data is currently stored in a batch, use the DataWriter’s flush() operation.

© 2019 RTI