3. Controlling Data: Processing Data Streams¶
In chapter Routing Data: Connecting and Scaling Systems we presented how Routing Service can easily connect and scale systems. In order to do so, data is forwarded among systems, thus generating data streams flowing from one system to another. The forwarding process is a basic operation that consists of propagating data streams from the input to the output.
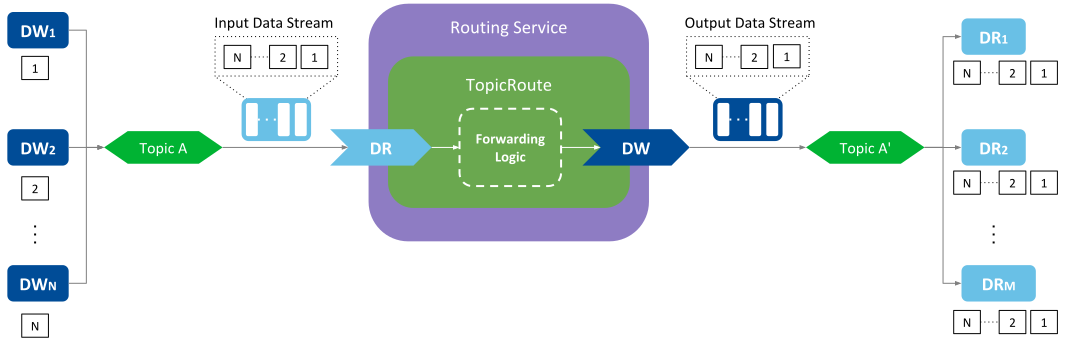
Figure 3.1 Basic forwarding of an input data stream¶
Figure 3.1 illustrates the forwarding
process of Topic data. At the publication side, there are N DataWriters each
producing samples for Topic A. The Routing Service has a TopicRoute with a single input DataReader
and a single output DataWriter. At the subscription side there are M DataReaders all
receiving samples from topic Topic A'. All the samples the user DataWriters
produce in the publication side are received by the input DataReader, which are then
forwarded through the output DataWriter to all the user DataReaders in the
subscription side. You can observe that the TopicRoute has a component the performs
the forwarding logic that involves reading from the input DataReader and writing to
the output DataReader.
The forwarding logic in the TopicRoute may be limiting when system connectivity demands other requirements beyond basic data forwarding. You can anticipate the simple read-and-write logic may be inadequate in TopicRoutes that define multiple INPUTs| and Outputs and the types of the associated Topics are different. These cases require the use of a custom logic to process the data streams, and this is the task of the Processor. Figure 3.2 shows the concept.
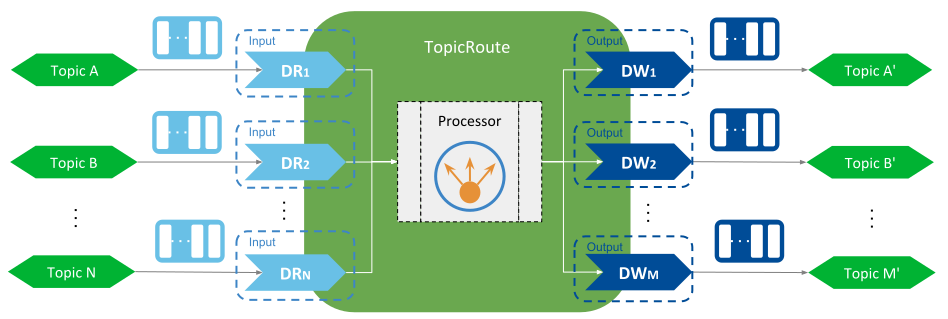
Figure 3.2 Processor concept¶
A Processor is a pluggable component that allows you control the forwarding process of a TopicRoute. You can create your own Processor implementations based on the needs of your system integration, defining your own data flows, and processing the data streams at your convenience.
A Processor receives notifications from the TopicRoute about relevant events such as the availability of Inputs and Outputs, state of the TopicRoute, or arrival of data. Then a Processor can react to any of these events and perform whichever necessary actions. The basic forward logic presented above is actually a builtin Processor implementation and that is set as the default in all the TopicRoutes.
The following sections will guide you through the process of creating your own Processor, how to configure it and install it in Routing Service. We will show you this functionality with examples of Aggregation and Splitting patterns.
Note
All the following sections require you to be familiar with the routing concepts explained in section Routing Data: Connecting and Scaling Systems. Also this section requires software programming knowledge in C/C++, understanding of CMake, and shared library management.
See also
- Forwarding Processor
Details on the default forwarding Processor of the TopicRoutes.
3.1. DynamicData as a Data Representation Model¶
The nature of the architecture of Routing Service makes it possible to work with data streams of different types. This demands a strategy for dealing with all the possible times both a compilation and run time. This is provided through DynamicData.
DynamicData a generic container that holds data for any type by keeping a custom and flexible internal representation of the data. DynamicData is a feature specific from Connext and is part of the core libraries. Figure 3.3 shows the concept of DynamicData.
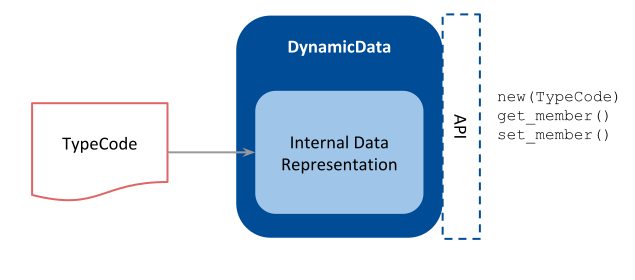
Figure 3.3 DynamicData concept¶
DynamicData is a container-like structure that holds data of any type. The description of how that type looks like is given by the TypeCode, a structure that allows representing any type. Using the TypeCode information, a DynamicData object can then contain data for the associated type and behave as if it was an actual structure of such type. The DynamicData class has a rich interface to access the data members and manipulate its content.
The Processor API makes the inputs and outputs to interface with DynamicData. Hence the inputs will return a list of DynamicData samples when reading, while the outputs expect a DynamicData object on the write operation. This common representation model has two benefits:
It allows implementations to work without knowing before hand the types. This is very convenient for general purpose processors, such as data member mappers.
It allows implementations to work independently from the the data domain where the data streams flow. This is particularly important when a different data other than DDS is used through a custom Adapter (Data Integration: Combining Different Data Domains).
See also
- Objects of Dynamically Defined Types.
Section in RTI Connext User’s manual about DynamicData and TypeCode.
- DynamicData C++ API reference
Online API documentation for the DynamicData class.
3.2. Aggregating Data From Different Topics¶
A very common scenario involves defining routing paths to combine data from two or more input Topics into a single output Topic. This pattern is known as Topic aggregation. You can leverage the Processor component to perform the custom Topic aggregation that best suits the needs of your system.
An example of Topic aggregation is shown in
Figure 3.4. There are two input Topics,
Square and Circle, and a single output Topic, Triangle. All Topics
have the same type ShapeType. The goal is to produce output samples by combining
data samples from the two inputs.
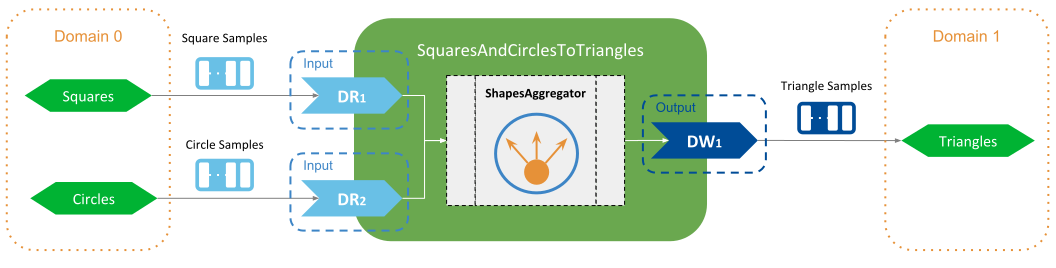
Figure 3.4 Aggregation example of two Topics¶
Let’s review all the tasks you need to do to create a custom Processor using the Example: Using a Shapes Processor . You can run it first to see it in action but you can also run one step at a time as we explain each.
3.2.1. Develop a Custom Processor¶
Once you know the stream processing pattern you want perform, including what
your data inputs and outputs are, you can then write the custom code of the
Processor. A custom processor must implement the interface
rti::routing::Processor, which defines the abstract operations that the
TopicRoute calls upon occurrence of certain events.
In our example, we create a ShapesAggregator class to be our Processor
implementation:
class ShapesAggregator : public rti::routing::processor::NoOpProcessor {
void on_data_available(rti::routing::processor::Route &);
void on_output_enabled(
rti::routing::processor::Route &route,
rti::routing::processor::Output &output);
...
}
Note how the processor class inherits from NoOpProcessor. This class inherits
from rti::routing::processor::Processor and implements all its virtual methods
as no-op. This is a convenience that allows us to implement only the
methods for the notification of interest. In this example:
on_output_enabled: Notifies that an output has been enabled and it is available to write. In our example, we create a buffer of the output type (ShapeType) that will hold the aggregated content of the input samples.on_data_available: Indicates that at least one input has data available to read. In our example, this is where the aggregation logic takes place and it will simply generate aggregated output samples that contain the same values as theSquaresamples, except for the fieldy, which is obtained from theCircle.
See also
- Route States
Different states of a TopicRoute and which Processor notifications are triggered under each of them.
3.2.3. Define a Configuration with the Aggregating TopicRoute¶
This is a similar process than the one we explained in section Routing a Topic between two different domains. There are two main differences that are particular to the use with a processor.
3.2.3.1. Configure a plugin library¶
Within the root element of the XML configuration, you can define a plugin library element that contains the description of all the plugins that can be loaded by Routing Service. In our case, we define a plugin library with a single entry for our aggregation processor plugin:
<plugin_library name="ShapesPluginLib">
<processor_plugin name="ShapesProcessor">
<dll>shapesaggregator</dll>
<create_function>
ShapesAggregatorPlugin_create_processor_plugin
</create_function>
</processor_plugin>
</plugin_library>
The values specified for the name attributes can be set at your convenience
and they shall uniquely identify a plugin instance. We will use these names
later within the TopicRoute to refer to this plugin. For the definition of our
processor plugin we have specified two elements:
dll: The name of the shared library as we specified in the build step. We just provide the library name so Routing Service will try to load it from the working directory, or assume that the library path is set accordingly.<create_function>: Name of the entry point (external function) that creates the plugin object, exactly as we defined in code with theRTI_PROCESSOR_PLUGIN_CREATE_FUNCTION_DECLmacro.
Once we have the plugin defined in the library, we can move to the next step and define the TopicRoute with the desired routing paths and our Processor in it.
Warning
When a name is specified in the <dll> element, Routing Service will automatically append a d suffix when running the debug version of Routing Service.
See also
- Plugins
Documentation about the
<plugin_library>element.- Plugin Management
For in-depth understanding of plugins.
3.2.3.2. Configure a Routing Service with the custom routing paths¶
In this example we need to define a TopicRoute that contains the two Inputs to
receive the data streams from the Square and Circle Topics, and the
single output to write the single data stream to the Triangle Topic. The
key element in our TopicRoute is the specification of a custom Processor, to
indicate that the TopicRoute should use an instance of our plugin to process the
route’s events and data:
<topic_route name="SquaresAndCirclestoTriangles">
<processor plugin_name="ShapesPluginLib::ShapesAggregator">
...
</processor>
<input name="Square" participant="domain0">
<topic_name>Square</topic_name>
<registered_type_name>ShapeType</registered_type_name>
<datareader_qos base_name="RsShapesQosLib::RsShapesQosProfile"/>
</input>
<input name="Circle" participant="domain0">
<topic_name>Circle</topic_name>
<registered_type_name>ShapeType</registered_type_name>
<datareader_qos base_name="RsShapesQosLib::RsShapesQosProfile"/>
</input>
<output name="Triangle" participant="domain1">
<topic_name>Triangle</topic_name>
<registered_type_name>ShapeType</registered_type_name>
</output>
</topic_route>
There are three important aspects in this TopicRoute configuration:
The custom Processor is specified with the
<processor>tag. Theplugin_nameattribute must contain the qualified name of an existing processor plugin within a plugin library. The qualified name is built using the values from thenameattributes of the plugin library and plugin element. Although our example does not make use of it, you could provide run-time configuration properties to our plugin through an optional<property>tag. This element represents a set of name-value string pairs that are passed to thecreate_processorcall of the plugin.Input and Output elements have all a
nameattribute. This is the configuration name for these elements can be used within the Processor to look up and individual Input or Output by its name, such as we do in our example. Also notice how the names match the Topic names for which they are associated. Because we are not specifying<topic_name>element, Routing Service uses the Input and Output names as Topic names. In our example this makes it convenient to identify 1:1 inputs and outputs with their topics.The input DataReaders are configured with a QoS that sets a
KEEP_LASThistory of just one sample. This allows our processor to just read and aggregate the latest available sample from each input.
3.3. Splitting Data From a single Topic¶
Another common pattern consists of defining routing paths to divide or split data from a input Topic into several output Topics. This mechanism represents the reverse equivalent to aggregation and is known as Topic splitting. You can leverage the Processor component to perform the Topic splitting that best suits the needs of your system.
An example of Topic splitting is shown in
Figure 3.5. There is a single input Topic,
Squares, and two output Topics, Circles and Triangles. All Topics
have the same type ShapeType. The goal is to produce output samples by splitting
the content of data samples from the input.
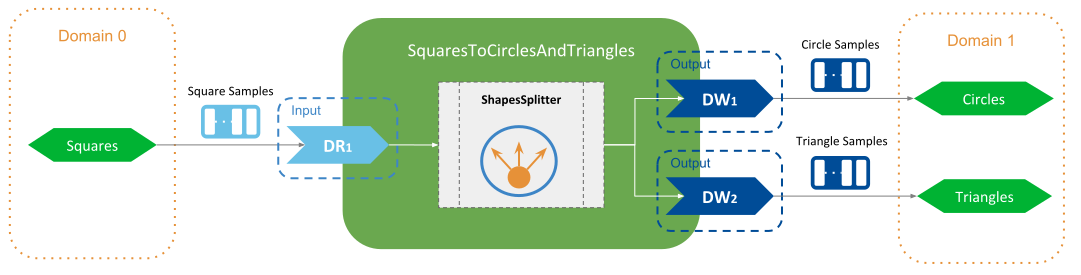
Figure 3.5 Splitting example of a Topic¶
The steps required to create a custom splitting Processor are the same as described in the previous section Aggregating Data From Different Topics. For this example we focus only in the aspects that are different.
3.3.1. Custom Processor implementation¶
In this example, we create a ShapesSplitter class to be our Processor
implementation. Similar to ShapesAggregator, this class reacts only to two
event notifications:
on_input_enabled: Creates a sample buffer that will be used to contain the split content from the inputs. Because all the inputs and outputs have the same type (ShapeType), we can obtain use the input type to create the output sample.on_data_available: This is where the splitting logic takes place and it will simply generate split output samples that contain the same values as theSquaresamples for all fields exceptxandy, which are set as follows:Circleoutput: thexfield has the same value than the inputSquareand setsyto zero.Triangleoutput: theyfield has the same value than the inputSquareand setsxto zero.
3.3.2. Define a Configuration with the Splitting TopicRoute¶
In this example we need to define a TopicRoute that contains the single Input to receive
the data streams from the Square Topic, and the two Outputs to write
the data streams fro the Circle and Triangle Topics. The TopicRoute specifies
a custom processor to be created from our plugin library, and it’s configured
to create the SplitterProcessor
<topic_route name="SquaresToCirclesAndTriangles">
<processor plugin_name="ShapesPluginLib::ShapesSplitter"/>
<input name="Square" participant="domain0">
<registered_type_name>ShapeType</registered_type_name>
</input>
<output name="Circle" participant="domain1">
<registered_type_name>ShapeType</registered_type_name>
</output>
<output name="Triangle" participant="domain1">
<registered_type_name>ShapeType</registered_type_name>
</output>
</topic_route>
In this TopicRoute configuration, the input DataReader and output DataWriters are create with default QoS. This is an important difference with regards to the configuration of aggregation example. The splitting pattern in this case is simpler since there’s a single input and each received sample can hence be split individually.
Note that the splitting pattern can include multiple inputs if needed, and generate output samples based on more complex algorithms in which different content from different inputs is spread across the outputs.
3.4. Periodic and Delayed Action¶
Processors can react to certain events affecting TopicRoutes. One special event that requires attention is the periodic event. In addition to events of asynchronous nature such as data available or route running, a TopicRoute can be configured to also provide notifications occurring at a specified periodic rate.
Example below shows the XML that enables the periodic event notification at a rate of one second:
<topic_route>
<periodic_action>
<sec>1</sec>
<nanosec>0</nanosec>
</periodic_action>
...
</topic_route>
If a TopicRoute enables the periodic event, then your Processor can implement
the on_periodic_action notification and perform any operation of interest,
including reading and writing data. For details on the XML configuration for
periodic action and TopicRoutes in general, see Section 8.2.6.
Note that each TopicRoute can specify a different period, allowing you to have different
event timing for different routing paths. Similarly, the event period that can
be modified at runtime through the Route::set_period operation that is available
as part of the Processor API.
The configuration above will generate periodic action events in addition to
data available events coming from the inputs. You could disable the
notification of data available using the tag <enable_data_on_inputs>,
causing the TopicRoute to be periodic-based only.
3.5. Simple data transformation: introduction to Transformation¶
There are cases involving basic manipulation of data streams that can be performed independently in a per-sample basis. That is, for a given input sample (or set of them) there’s a transformed output sample (or set of them). For this particular use case, Routing Service defines the concept of Transformation, shown in Figure 3.6.
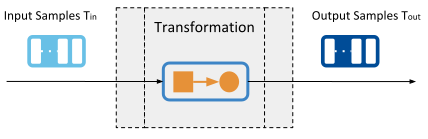
Figure 3.6 Transformation concept¶
A Transformation is a pluggable component that receives an input data stream of type Tin and produces an output data stream of type Tout. The relation between the number of input samples and output samples can also be different.
This component can be installed in two different entities in Routing Service. A Transformation can appear to process the data stream after is produced by an Input DataReader and/or to process a data stream before is passed to an Output DataWriter. Figure 3.7 shows the complete model and context of this component.
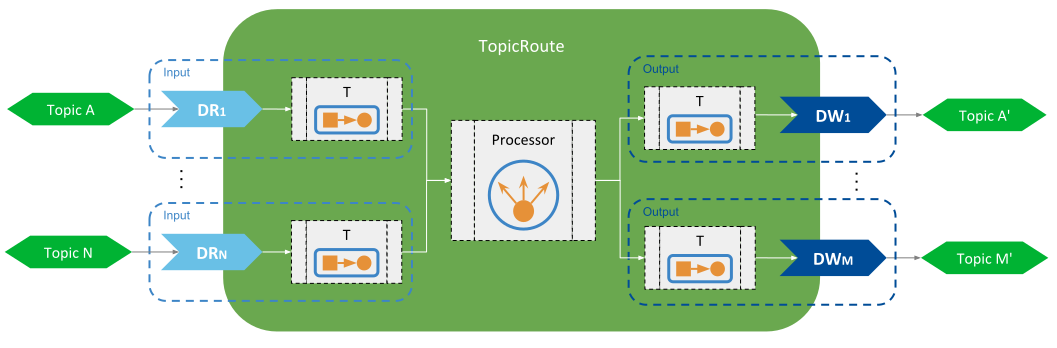
Figure 3.7 Transformation model and context¶
You can observe that a each Input and Output can contain a transformation. On the input side, the Transformation is applied to the data stream generated by the input DataReader and the result is fed to the Processor. Alternatively, on the output side the Transformation is applied to the data stream produced by the Processor and the result is passed to the output DataWriter.
When transformations are used it’s a requirement that the type of the samples provided by the input DataReader is the same type Tin expected by the input Transformation. Similarly, the type Toutof the samples produced by the output Transformation must be the same than the type of the samples expected by the output DataWriter. As in with a Processor, a Transformation is expected to work with DynamicData (DynamicData as a Data Representation Model).
You can run Example: Transforming the Data with a Custom Transformation to see how a transformation can
be used. In this example, the transformation implementation receives and
generates samples of type ShapeType. The output samples are equal to the
input samples except for the field x, which is adjusted to produce only
two possible constant values.
3.5.1. Transformations vs Processors¶
A Transformation is fundamentally different than a Processor. Moreover, they complement each other. A Transformation can be seen a very simplified version of a Processor that has a single input and a single output and in which the input data stream is processed as it is read.
In general you will find yourself implementing a Processor to perform the data stream processing required by your system. Nevertheless there are cases where a Transformation is more suitable for certain patterns such as format conversion, content reduction, or normalization (see What stream processing patterns can I perform?).
3.6. What stream processing patterns can I perform?¶
With Routing Service you have the ability to define routing paths with multiple inputs and outputs, and provide custom processing logic for the data streams of those paths. This provides a great degree of flexibility that allows to perform pretty much any processing pattern.
In addition to the presented patterns of aggregation, splitting, and periodic action, there are other well-known patterns:
Data format conversion: this is the case where the input samples are represented in one format and are converted to produce output samples of a different format. For example, input samples could be represented as a byte array and converted to a JSON string.
Content Enrichment: an output sample is the result of amplifying or adding content to an input sample. For example, output samples can be enhanced to contain additional fields that represents result of computations performed on input sample fields (e.g., statistic metrics).
Content Reduction: an output sample is the result of attenuating or removing content from an input sample. For example, output samples can have some fields removed that are not relevant to the final destination, to improve bandwidth usage.
Normalizer: output samples are semantically equivalent to the input samples except the values are adjusted or normalized according to a specific convention. For example, input samples may contain a field indicating the temperature in Fahrenheit and the output samples provide the same temperature in Celsius.
Event-based or Triggered Forwarding: output samples are generated based on the reception and content of concrete input samples in which some of them act as events indicating which, how, and when data is forwarded.
3.7. Key Terms¶
- Data Stream
The collection of samples received by a TopicRoute’s Input or written to a TopicRoute’s Output.
- DynamicData
A general purpose structure that contains data of any type.
- Processor
Pluggable component to control the forwarding process of a TopicRoute
An output artifact that contains the implementation of pluggable components that Routing Service can load at run-time.
- Entry Point
External symbol in a shared library that Routing Service calls to instantiate a custom plugin instance.
- Stream Processing Patterns
Processing algorithms applied to the data streams of a TopicRoute.
- Periodic action
TopicRoute event notification occurring at a configurable period.
- Transformation
Pluggable component perform modifications of a forwarded data stream.