RTI Connext
Core Libraries and Utilities
User’s Manual
Part 3 — Advanced Concepts
Chapters
Version 5.0
RTI Connext
Core Libraries and Utilities
User’s Manual
Part 3 — Advanced Concepts
Chapters
Version 5.0

© 2012
All rights reserved.
Printed in U.S.A. First printing.
August 2012.
Trademarks
Copy and Use Restrictions
No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form (including electronic, mechanical, photocopy, and facsimile) without the prior written permission of Real- Time Innovations, Inc. The software described in this document is furnished under and subject to the RTI software license agreement. The software may be used or copied only under the terms of the license agreement.
Note: In this section, "the Software" refers to
This product implements the DCPS layer of the Data Distribution Service (DDS) specification version 1.2 and the DDS Interoperability Wire Protocol specification version 2.1, both of which are owned by the Object Management, Inc. Copyright
Portions of this product were developed using ANTLR (www.ANTLR.org). This product includes software developed by the University of California, Berkeley and its contributors.
Portions of this product were developed using AspectJ, which is distributed per the CPL license. AspectJ source code may be obtained from Eclipse. This product includes software developed by the University of California, Berkeley and its contributors.
Portions of this product were developed using MD5 from Aladdin Enterprises.
Portions of this product include software derived from Fnmatch, (c) 1989, 1993, 1994 The Regents of the University of California. All rights reserved. The Regents and contributors provide this software "as is" without warranty.
Portions of this product were developed using EXPAT from Thai Open Source Software Center Ltd and Clark Cooper Copyright (c) 1998, 1999, 2000 Thai Open Source Software Center Ltd and Clark Cooper Copyright (c) 2001, 2002 Expat maintainers. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
Technical Support
232 E. Java Drive
Sunnyvale, CA 94089
Phone: |
(408) |
Email: |
support@rti.com |
Website: |
Contents, Part 3
|
|||
|
|||
|
|||
10.3.4 Controlling Heartbeats and Retries with DataWriterProtocol QosPolicy |
|||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
10.3.5 Avoiding Message Storms with DataReaderProtocol QosPolicy |
|||
10.3.6 Resending Samples to |
|||
|
|||
|
|||
|
|||
|
|||
iii
iv
|
|||||
|
|
||||
|
|
|
|||
|
|
|
|||
|
|
||||
|
|
||||
|
|||||
|
|
||||
|
|
|
|||
|
|
|
14.3.1.2 Maintaining DataWriter Liveliness for kinds AUTOMATIC and |
|
|
|
|
|
|
||
|
|
||||
|
|
||||
|
|
||||
|
|||||
|
|||||
|
|
||||
|
|
||||
|
|
14.5.3 Automatic Selection of participant_id and Port Reservation |
|||
|
|
||||
|
|||||
|
|||||
|
|||||
|
|||||
|
Setting Builtin Transport Properties of the Default Transport Instance |
|
|||
|
|
||||
|
Setting Builtin Transport Properties with the PropertyQosPolicy |
||||
|
|
||||
|
|
15.6.2 Setting the Maximum |
|||
|
|
15.6.3 Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ Address Lists |
|||
|
Installing Additional Builtin Transport Plugins with register_transport() |
||||
|
|
||||
|
|
||||
|
|
||||
|
Installing Additional Builtin Transport Plugins with PropertyQosPolicy |
||||
|
|||||
|
|
||||
|
|
||||
|
|
||||
|
|||||
|
|||||
|
|||||
|
|
||||
v
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
||
|
||
|
||
|
||
vi
|
|||
|
|||
|
|||
|
|||
20.1.4 |
|
20.2.1 Memory Management for DataReaders Using Generated |
|
20.2.6 |
vii

Chapter 10 Reliable Communications
Connext uses
This chapter includes the following sections:
❏Sending Data Reliably (Section 10.1)
❏Overview of the Reliable Protocol (Section 10.2)
❏Using QosPolicies to Tune the Reliable Protocol (Section 10.3)
10.1Sending Data Reliably
The DCPS reliability model recognizes that the optimal balance between
The QosPolicies provide a way to customize the determinism/reliability
There are two delivery models:
❏
❏Reliable delivery model “Make sure all samples get there, in order.”
10.1.1
By default, Connext uses the
The
10.1.2Reliable Delivery Model
Reliable delivery means the samples are guaranteed to arrive, in the order published.
The DataWriter maintains a send queue with space to hold the last X number of samples sent. Similarly, a DataReader maintains a receive queue with space for consecutive X expected samples.
The send and receive queues are used to temporarily cache samples until Connext is sure the samples have been delivered and are not needed anymore. Connext removes samples from a publication’s send queue after the sample has been acknowledged by all reliable subscriptions. When positive acknowledgements are disabled (see DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3) and DATA_READER_PROTOCOL QosPolicy (DDS Extension) (Section 7.6.1)), samples are removed from the send queue after the corresponding keep- duration has elapsed (see Table 6.36, “DDS_RtpsReliableWriterProtocol_t,” on page
If an
DataReader.
DataWriters can be set up to wait for available queue space when sending samples. This will cause the sending thread to block until there is space in the send queue. (Or, you can decide to sacrifice sending samples reliably so that the sending rate is not compromised.) If the DataWriter is set up to ignore the full queue and sends anyway, then older cached samples will be pushed out of the queue before all DataReaders have received them. In this case, the DataReader (or its Subscriber) is notified of the missing samples through its Listener and/or Conditions.
Connext automatically sends acknowledgments (ACKNACKs) as necessary to maintain reliable communications. The DataWriter may choose to block for a specified duration to wait for these acknowledgments (see Waiting for Acknowledgments in a DataWriter (Section 6.3.11)).
Connext establishes a virtual reliable channel between the matching DataWriter and all DataReaders. This mechanism isolates DataReaders from each other, allows the application to control memory usage, and provides mechanisms for the DataWriter to balance reliability and determinism. Moreover, the use of send and receive queues allows Connext to be implemented efficiently without introducing unnecessary delays in the stream.
Note that a successful return code (DDS_RETCODE_OK) from write() does not necessarily mean that all DataReaders have received the data. It only means that the sample has been added to the DataWriter’s queue. To see if all DataReaders have received the data, look at the RELIABLE_WRITER_CACHE_CHANGED Status (DDS Extension) (Section 6.3.6.7) to see if any samples are unacknowledged.
Suppose DataWriter A reliably publishes a Topic to which DataReaders B and C reliably subscribe. B has space in its queue, but C does not. Will DataWriter A be notified? Will DataReader C receive any error messages or callbacks? The exact behavior depends on the QoS settings:
❏If HISTORY_KEEP_ALL is specified for C, C will reject samples that cannot be put into the queue and request A to resend missing samples. The Listener is notified with the on_sample_rejected() callback (see SAMPLE_REJECTED Status (Section 7.3.7.8)). If A has a queue large enough, or A is no longer writing new samples, A won’t notice unless it checks the RELIABLE_WRITER_CACHE_CHANGED Status (DDS Extension) (Section 6.3.6.7).
❏If HISTORY_KEEP_LAST is specified for C, C will drop old samples and accept new ones. The Listener is notified with the on_sample_lost() callback (see SAMPLE_LOST Status (Section 7.3.7.7)). To A, it is as if all samples have been received by C (that is, they have all been acknowledged).

10.2Overview of the Reliable Protocol
An important advantage of Connext is that it can offer the reliability and other QoS guarantees mandated by DDS on top of a very wide variety of transports, including
In order to work in this wide range of environments, the reliable protocol defined by RTPS is highly configurable with a set of parameters that let the application
The most important features of the RTPS protocol are:
❏Support for both push and pull operating modes
❏Support for both positive and negative acknowledgments
❏Support for high
❏Support for multicast DataReaders
❏Support for
In order to support these features, RTPS uses several types of messages: Data messages (DATA), acknowledgments (ACKNACKs), and heartbeats (HBs).
❏DATA messages contain snapshots of the value of
❏HB messages announce to the DataReader that it should have received all snapshots up to the one tagged with a range of sequence numbers and can also request the DataReader to send an acknowledgement back. For example,
❏ACKNACK messages communicate to the DataWriter that particular snapshots have been successfully stored in the DataReader’s history. ACKNACKs also tell the DataWriter which snapshots are missing on the DataReader side. The ACKNACK message includes a set of sequence numbers represented as a bit map. The sequence numbers indicate which ones the DataReader is missing. (The bit map contains the base sequence number that has not been received, followed by the number of bits in bit map and the optional bit map.
The maximum size of the bit map is 256.) All numbers up to (not including) those in the set are considered positively acknowledged. They are represented in Figure 10.1 through Figure 10.7 as
1. For a link to the RTPS specification, see the RTI website, www.rti.com.
missing>). For example, ACKNACK(4) indicates that the snapshots with sequence numbers 1, 2, and 3 have been successfully stored in the DataReader history, and that 4 has not been received.
It is important to note that Connext can bundle multiple of the above messages within a single network packet. This ‘submessage bundling’ provides for higher performance communications.
Figure 10.1 Basic RTPS Reliable Protocol
Assigned sequence number
History of send data values
Whether or not the sample has been delivered to the reader history
DataWriter DataReader
write
(A)
1 |
A |
X |
|
|
DATA (A,1); |
|
||
|
cache |
HB (1) |
|
|||||
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
(A, 1) |
|
|
cache |
|
|
|
|
|
|
|
|
(A, 1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
check
(1)
|
|
|
|
|
|
ACKNACK |
1 |
A |
4 |
|
|
|
(2) |
|
acked |
|||||
|
|
|
|
|
||
|
|
|
|
|||
|
|
|
(1) |
|
|
|
|
|
|
|
|
time |
time |
|
|
|
|
|
||
|
|
|
|
|
||
|
|
|
||||
Assigned sequence number
DataReader history
Whether or not the sample is available for the application to read/take
1 A 4
Figure 10.1 illustrates the basic behavior of the protocol when an application calls the write() operation on a DataWriter that is associated with a DataReader. As mentioned, the RTPS protocol can bundle multiple submessages into a single network packet. In Figure 10.1 this feature is used to piggyback a HB message to the DATA message. Note that before the message is sent, the data is given a sequence number (1 in this case) which is stored in the DataWriter’s send queue. As soon as the message is received by the DataReader, it places it into the DataReader’s receive queue. From the sequence number the DataReader can tell that it has not missed any messages and therefore it can make the data available immediately to the user (and call the DataReaderListener). This is indicated by the “✔” symbol. The reception of the HB(1) causes the DataReader to check that it has indeed received all updates up to and including the one with sequenceNumber=1. Since this is true, it replies with an ACKNACK(2) to positively acknowledge all messages up to (but not including) sequence number 2. The DataWriter notes that the update has been acknowledged, so it no longer needs to be retained in its send queue. This is indicated by the “✔” symbol.
Figure 10.2 illustrates the behavior of the protocol in the presence of lost messages. Assume that the message containing DATA(A,1) is dropped by the network. When the DataReader receives
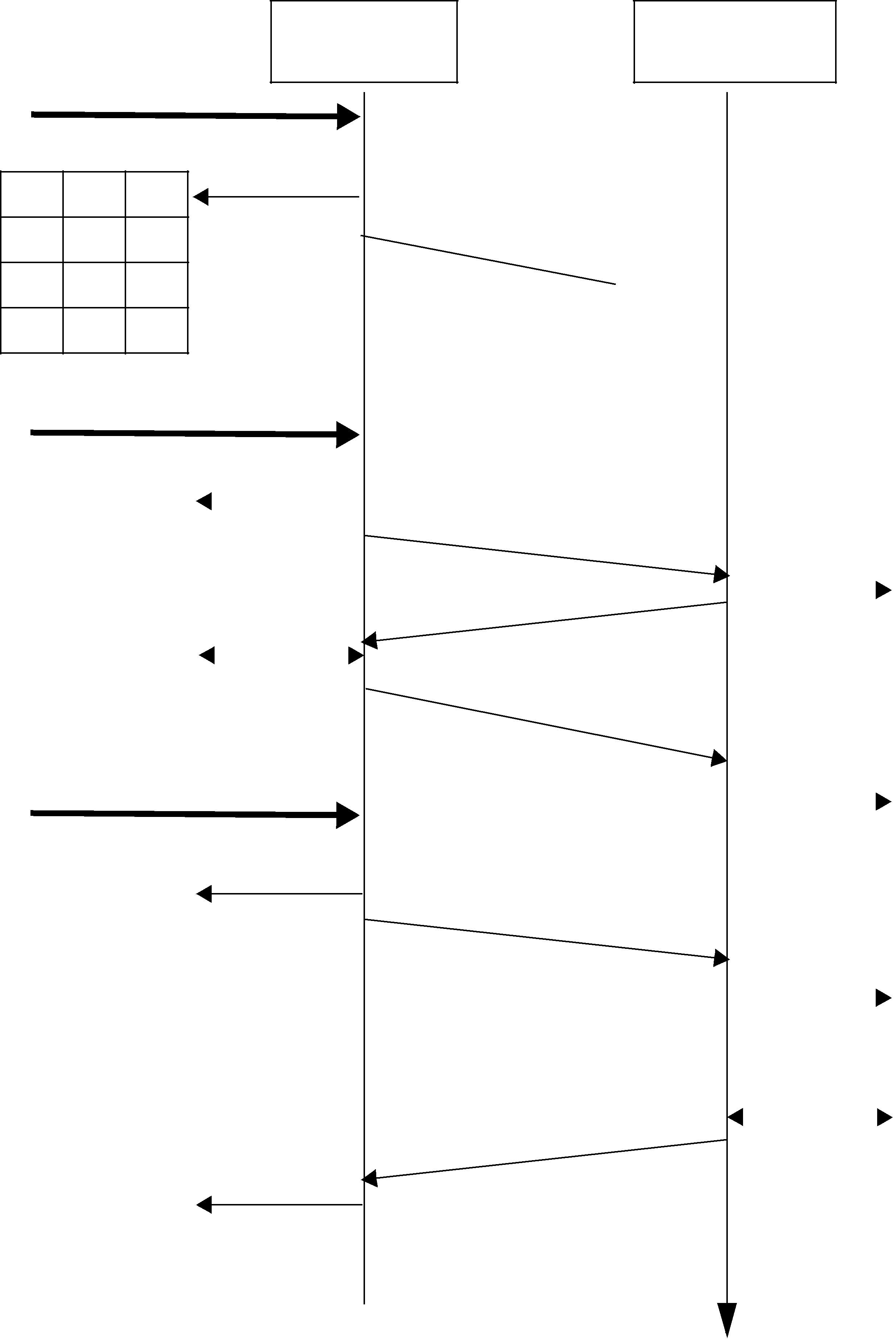
Figure 10.2 RTPS Reliable Protocol in the Presence of Message Loss
DataWriter
write(S01)
1 A X
cache (A, 1)
D |
|
AT |
|
A ( |
|
A, |
|
1); |
|
|
HB (1) |
DataReader
 r
r
write(S02)
1 |
A |
X |
|
|
|
|
|
cache(B,2) |
|||||||
|
|
|
|||||
2 |
B |
X |
|||||
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
get(1)
write(S03)
DATA |
|
|
|
(B,2); |
|
|
|
HB |
|
K(1) |
|
KNAC |
|
|
AC |
|
|
D |
|
|
AT |
|
|
|
A ( |
|
|
A,1) |
|
1 |
A |
X |
cache(C,3) |
|
|
|
|
||
2 |
B |
X |
||
|
||||
|
|
|
|
|
3 |
C |
X |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
A |
4 |
|
|
|
|
|
|
|
2 |
B |
4 |
|
|
|
|
|
||
3 |
C |
4 |
||
|
||||
|
|
|
|
|
|
|
|
|
DATA (C,3); HB
|
K(4) |
KNAC |
|
AC |
|
 time
time
|
|
|
|
1 |
|
X |
|
cache (B,2) |
|
||||||
|
|
|
|||||
2 |
B |
X |
|||||
|
|
|
|||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
1 |
A |
4 |
|
cache (A,1) |
|||||||
|
|
|
|||||
2 |
B |
4 |
|||||
|
|
|
|||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
1 |
A |
4 |
|
cache (C,3) |
|||||||
|
|
|
|||||
2 |
B |
4 |
|||||
|
|
|
|||||
|
|
|
|
|
|
||
|
|
|
|
3 |
C |
4 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|||||
time |
See Figure 10.1 for |
|
meaning of table columns. |
||
|
the next message (DATA(B,2);
1.The data associated with sequence number 2 (B) is tagged with ‘X’ to indicate that it is not deliverable to the application (that is, it should not be made available to the application, because the application needs to receive the data associated with sample 1
(A) first).
2.An ACKNACK(1) is sent to the DataWriter to request that the data tagged with sequence number 1 be resent.
Reception of the ACKNACK(1) causes the DataWriter to resend DATA(A,1). Once the DataReader receives it, it can ‘commit’ both A and B such that the application can now access both (indicated

by the “✔”) and call the DataReaderListener. From there on, the protocol proceeds as before for the next data message (C) and so forth.
A subtle but important feature of the RTPS protocol is that ACKNACK messages are only sent as a direct response to HB messages. This allows the DataWriter to better control the overhead of these ‘administrative’ messages. For example, if the DataWriter knows that it is about to send a chain of DATA messages, it can bundle them all and include a single HB at the end, which minimizes ACKNACK traffic.
10.3Using QosPolicies to Tune the Reliable Protocol
Reliability is controlled by the QosPolicies in Table 10.1. To enable reliable delivery, read the following sections to learn how to change the QoS for the DataWriter and DataReader:
❏Enabling Reliability (Section 10.3.1)
❏Tuning Queue Sizes and Other Resource Limits (Section 10.3.2)
❏Controlling Heartbeats and Retries with DataWriterProtocol QosPolicy (Section 10.3.4)
❏Avoiding Message Storms with DataReaderProtocol QosPolicy (Section 10.3.5)
❏Resending Samples to
Then see this section to explore example use cases:
Table 10.1 QosPolicies for Reliable Communications
QosPolicy |
Description |
Related |
Reference |
|
Entitiesa |
||||
|
|
|
||
|
|
|
|
|
|
To establish reliable communication, this QoS must be |
|
||
Reliability |
set to DDS_RELIABLE_RELIABILITY_QOS for the |
DW, DR |
||
|
DataWriter and its DataReaders. |
|
||
|
|
|
||
|
|
|
|
|
|
This QoS determines the amount of resources each side |
|
|
|
|
can use to manage instances and samples of instances. |
|
|
|
|
Therefore it controls the size of the DataWriter’s send |
|
||
ResourceLimits |
queue and the DataReader’s receive queue. The send |
DW, DR |
||
|
queue stores samples until they have been ACKed by |
|
||
|
|
|
||
|
all DataReaders. The DataReader’s receive queue stores |
|
|
|
|
samples for the user’s application to access. |
|
|
|
|
|
|
|
|
History |
This QoS affects how a DataWriter/DataReader behaves |
DW, DR |
||
|
when its send/receive queue fills up. |
|
||
DataWriterProtocol |
This QoS configures |
DW |
||
|
QoS can disable positive ACKs for its DataReaders. |
|
||
|
When a reliable DataReader receives a heartbeat from a |
|
|
|
|
DataWriter and needs to return an ACKNACK, the |
|
||
DataReaderProtocol |
DataReader can choose to delay a while. This QoS sets |
DR |
||
|
the minimum and maximum delay. It can also disable |
|
||
|
|
|
||
|
positive ACKs for the DataReader. |
|
|
|
|
|
|
|
Table 10.1 QosPolicies for Reliable Communications
QosPolicy |
Description |
Related |
Reference |
|
Entitiesa |
||||
|
|
|
||
|
|
|
|
|
|
This QoS determines additional amounts of resources |
|
|
|
|
that the DataReader can use to manage samples |
|
|
|
DataReaderResource- |
(namely, the size of the DataReader’s internal queues, |
DR |
||
Limits |
which cache samples until they are ordered for reliabil- |
|
||
|
ity and can be moved to the DataReader’s receive queue |
|
|
|
|
for access by the user’s application). |
|
|
|
|
|
|
|
|
Durability |
This QoS affects whether |
DW, DR |
||
|
receive all |
|
a.DW = DataWriter, DR = DataReader
10.3.1Enabling Reliability
You must modify the RELIABILITY QosPolicy (Section 6.5.19) of the DataWriter and each of its reliable DataReaders. Set the kind field to DDS_RELIABLE_RELIABILITY_QOS:
❏ DataWriter
writer_qos.reliability.kind = DDS_RELIABLE_RELIABILITY_QOS;
❏ DataReader
reader_qos.reliability.kind = DDS_RELIABLE_RELIABILITY_QOS;
10.3.1.1Blocking until the Send Queue Has Space Available
The max_blocking_time property in the RELIABILITY QosPolicy (Section 6.5.19) indicates how long a DataWriter can be blocked during a write().
If max_blocking_time is
If the number of unacknowledged samples in the reliability send queue drops below max_samples (set in the RESOURCE_LIMITS QosPolicy (Section 6.5.20)) before max_blocking_time, the sample is sent and write() returns DDS_RETCODE_OK.
If max_blocking_time is zero and the reliability send queue is full, write() returns DDS_RETCODE_TIMEOUT and the sample is not sent.
10.3.2Tuning Queue Sizes and Other Resource Limits
Set the HISTORY QosPolicy (Section 6.5.10) appropriately to accommodate however many samples should be saved in the DataWriter’s send queue or the DataReader’s receive queue. The defaults may suit your needs; if so, you do not have to modify this QosPolicy.
Set the DDS_RtpsReliableWriterProtocol_t in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3) appropriately to accommodate the number of unacknowledged samples that can be
For more information, see the following sections:
❏Understanding the Send Queue and Setting its Size (Section 10.3.2.1)
❏Understanding the Receive Queue and Setting Its Size (Section 10.3.2.2)
Note: The HistoryQosPolicy’s depth must be less than or equal to the ResourceLimitsQosPolicy’s max_samples_per_instance; max_samples_per_instance must be less than or equal to the ResourceLimitsQosPolicy’s max_samples (see RESOURCE_LIMITS QosPolicy (Section 6.5.20)), and max_samples_per_remote_writer (see
DATA_READER_RESOURCE_LIMITS QosPolicy (DDS Extension) (Section 7.6.2)) must be less than or equal to max_samples.
❏depth <= max_samples_per_instance <= max_samples
❏max_samples_per_remote_writer <= max_samples
Examples:
❏ DataWriter
writer_qos.resource_limits.initial_instances = 10; writer_qos.resource_limits.initial_samples = 200; writer_qos.resource_limits.max_instances = 100; writer_qos.resource_limits.max_samples = 2000; writer_qos.resource_limits.max_samples_per_instance = 20; writer_qos.history.depth = 20;
❏ DataReader
reader_qos.resource_limits.initial_instances = 10; reader_qos.resource_limits.initial_samples = 200; reader_qos.resource_limits.max_instances = 100; reader_qos.resource_limits.max_samples = 2000; reader_qos.resource_limits.max_samples_per_instance = 20; reader_qos.history.depth = 20; reader_qos.reader_resource_limits.max_samples_per_remote_writer = 20;
10.3.2.1Understanding the Send Queue and Setting its Size
A DataWriter’s send queue is used to store each sample it writes. A sample will be removed from the send queue after it has been acknowledged (through an ACKNACK) by all the reliable DataReaders. A DataReader can request that the DataWriter resend a missing sample (through an ACKNACK). If that sample is still available in the send queue, it will be resent. To elicit timely ACKNACKs, the DataWriter will regularly send heartbeats to its reliable DataReaders.
A DataWriter’s send queue size is determined by its RESOURCE_LIMITS QosPolicy (Section 6.5.20), specifically the max_samples field. The appropriate value depends on application parameters such as how fast the publication calls write().
A DataWriter has a "send window" that is the maximum number of unacknowledged samples allowed in the send queue at a time. The send window enables configuration of the number of samples queued for reliability to be done independently from the number of samples queued for history. This is of great benefit when the size of the history queue is much different than the size of the reliability queue. For example, you may want to resend a large history to
The send window is determined by the DataWriterProtocolQosPolicy, specifically the fields min_send_window_size and max_send_window_size within the rtps_reliable_writer field of type DDS_RtpsReliableWriterProtocol_t. Other fields control a dynamic send window, where the send window size changes in response to network congestion to maximize the effective send rate. Like for max_samples, the appropriate values depend on application parameters.
Strict reliability: If a DataWriter does not receive ACKNACKs from one or more reliable DataReaders, it is possible for the reliability send
reliability queue before writing any more samples. Connext provides two mechanisms to do this:
❏Allow the write() operation to block until there is space in the reliability queue again to store the sample. The maximum time this call blocks is determined by the max_blocking_time field in the RELIABILITY QosPolicy (Section 6.5.19) (also discussed in Section 10.3.1.1).
❏Use the DataWriter’s Listener to be notified when the reliability queue fills up or empties again.
When the HISTORY QosPolicy (Section 6.5.10) on the DataWriter is set to KEEP_LAST, strict reliability is not guaranteed. When there are depth number of samples in the queue (set in the HISTORY QosPolicy (Section 6.5.10), see Section 10.3.3) the oldest sample will be dropped from the queue when a new sample is written. Note that in such a reliable mode, when the send window is larger than max_samples, the DataWriter will never block, but strict reliability is no longer guaranteed.
If there is a request for the purged sample from any DataReaders, the DataWriter will send a heartbeat that no longer contains the sequence number of the dropped sample (it will not be able to send the sample).
Alternatively, a DataWriter with KEEP_LAST may block on write() when its send window is smaller than its send queue. The DataWriter will block when its send window is full. Only after the blocking time has elapsed, the DataWriter will purge a sample, and then strict reliability is no longer guaranteed.
The send queue size is set in the max_samples field of the RESOURCE_LIMITS QosPolicy (Section 6.5.20). The appropriate size for the send queue depends on application parameters (such as the send rate), channel parameters (such as
The DataReader’s receive queue size should generally be larger than the DataWriter’s send queue size. Receive queue size is discussed in Section 10.3.2.2.
A good rule of thumb, based on a simple model that assumes individual packet drops are not correlated and
Figure 10.3 Calculating Minimum Send Queue Size for a Desired Level of Reliability
NRTlog ( 1 – Q)
=2
log ( p)
Simple formula for determining the minimum size of the send queue required for strict reliability.
In the above equation, R is the rate of sending samples, T is the
Table 10.2 gives the required size of the send queue for several common scenarios.
Table 10.2 Required Size of the Send Queue for Different Network Parameters
Qa |
pb |
Tc |
|
Rd |
Ne |
|
|
|
|
|
|
99% |
1% |
0.001f sec |
100 Hz |
|
1 |
99% |
1% |
0.001 sec |
2000 Hz |
|
2 |
|
|
|
|
|
|
99% |
5% |
0.001 sec |
100 Hz |
|
1 |
|
|
|
|
|
|
99% |
5% |
0.001 sec |
2000 Hz |
|
4 |
|
|
|
|
|
|
99.99% |
1% |
0.001 sec |
100 Hz |
|
1 |
|
|
|
|
|
|
Table 10.2 Required Size of the Send Queue for Different Network Parameters
Qa |
pb |
|
Tc |
|
Rd |
Ne |
|
|
|
|
|
|
|
99.99% |
1% |
0.001 sec |
|
2000 Hz |
|
6 |
|
|
|
|
|
|
|
99.99% |
5% |
0.001 sec |
|
100 Hz |
|
1 |
|
|
|
|
|
|
|
99.99% |
5% |
0.001 sec |
|
2000 Hz |
|
8 |
|
|
|
|
|
|
|
a."Q" is the desired level of reliability measured as the probability that any data update will eventually be delivered successfully. In other words, percentage of samples that will be successfully delivered.
b."p" is the probability that any single packet gets lost in the network.
c."T" is the
d."R" is the rate at which the publisher is sending updates.
e."N" is the minimum required size of the send queue to accomplish the desired level of reliability "Q".
f.The typical
Note: Packet loss on a network frequently happens in bursts, and the packet loss events are correlated. This means that the probability of a packet being lost is much higher if the previous packet was lost because it indicates a congested network or busy receiver. For this situation, it may be better to use a queue size that can accommodate the longest period of network congestion, as illustrated in Figure 10.4.
Figure 10.4 Calculating Minimum Send Queue Size for Networks with Dropouts
N = RD( Q)
Send queue size as a function of send rate "R" and maximum dropout time D.
In the above equation R is the rate of sending samples, D(Q) is a time such that Q percent of the dropouts are of equal or lesser length, and Q is the required probability that a sample is eventually successfully delivered. The problem with the above formula is that it is hard to determine the value of D(Q) for different values of Q.
For example, if we want to ensure that 99.9% of the samples are eventually delivered successfully, and we know that the 99.9% of the network dropouts are shorter than 0.1 seconds, then we would use N = 0.1*R. So for a rate of 100Hz, we would use a send queue of N = 10; for a rate of 2000Hz, we would use N = 200.
10.3.2.2Understanding the Receive Queue and Setting Its Size
Samples are stored in the DataReader’s receive queue, which is accessible to the user’s application.
A sample is removed from the receive queue after it has been accessed by take(), as described in Accessing Data Samples with Read or Take (Section 7.4.3). Note that read() does not remove samples from the queue.
A DataReader's receive queue size is limited by its RESOURCE_LIMITS QosPolicy (Section 6.5.20), specifically the max_samples field. The storage of
A DataReader can maintain reliable communications with multiple DataWriters (e.g., in the case of the OWNERSHIP_STRENGTH QosPolicy (Section 6.5.16) setting of SHARED). The maximum number of
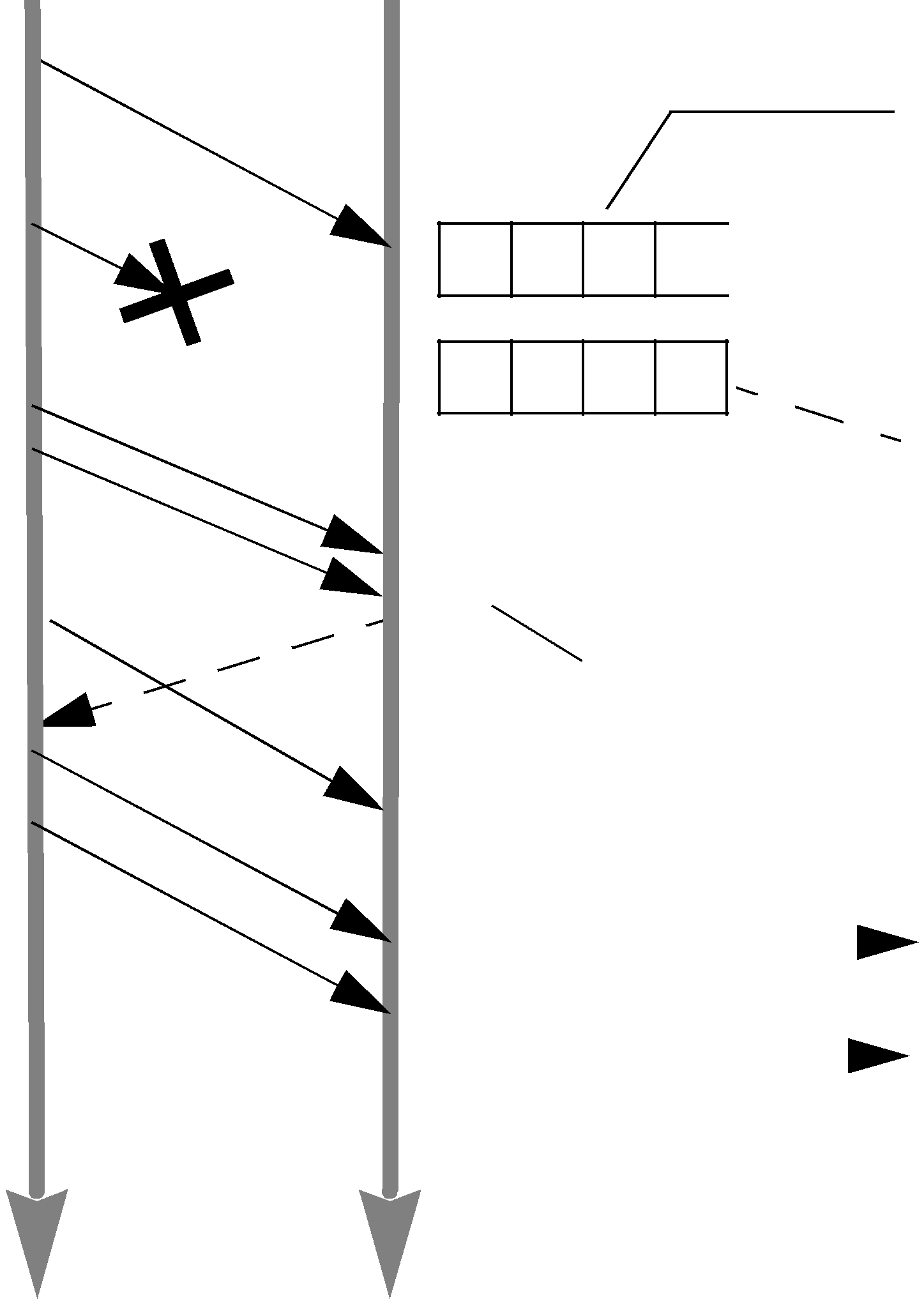
The DataReader will cache samples that arrive out of order while waiting for missing samples to be resent. (Up to 256 samples can be resent; this limitation is imposed by the wire protocol.) If there is no room, the DataReader has to reject
The appropriate size of the receive queue depends on application parameters, such as the DataWriter’s sending rate and the probability of a dropped sample. However, the receive queue size should generally be larger than the send queue size. Send queue size is discussed in Section 10.3.2.1.
Figure 10.5 and Figure 10.6 compare two hypothetical DataReaders, both interacting with the same DataWriter. The queue on the left represents an ordering cache, allocated from receive
In Figure 10.6 on page
Figure 10.5 Effect of
DataWriter DataReader
Send Sample “1”
Send Sample “2”
1
 Sample
Sample
Send Sample “3” “2” lost. Send HeartBeat
max_samples is 4. This also limits the number of unordered samples that can be cached.

 Sample 1 is taken
Sample 1 is taken
 Note: no unordered samples cached
Note: no unordered samples cached
Send Sample “4”
C |
||||
A |
||||
|
|
|
||
Send Sample “5” |
|
|||
|
|
|
|
|
( |
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
) |
“ |
” |
|
|
|
|
|
|
|
|
|
Space reserved for missing sample “2”. |
||
|
|
K |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
C |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Samples “3” and “4” are cached |
|
|
|
|
|
|
|
3 |
4 |
|
|
|
|
|
|
while waiting for missing sample “2”. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
3 |
4 |
|
|
|
|
|
|
Samples |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
Sample 5 is taken |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
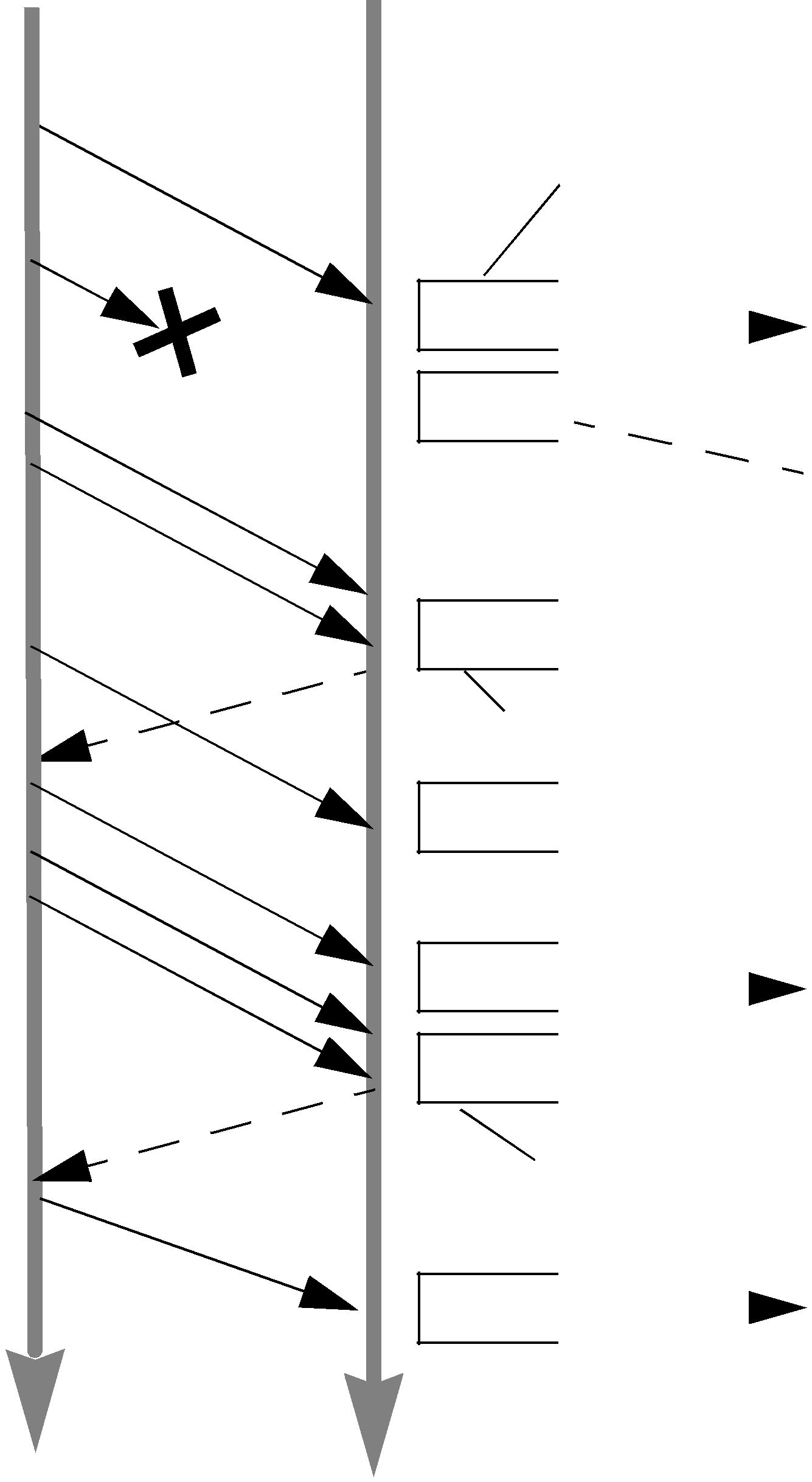
Figure 10.6 Effect of Receive Queue Size on Performance: Small Queue Size
DataWriter DataReader
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Send Sample “1” |
|
|
|
|
|
|
|
|
|
|
|
||
Send Sample “2” |
|
|
|
|
|
|
|
|
|
|
|
||
Send Sample “3” |
|
|
|
Sample |
|
|
|||||||
|
|
|
“2” lost |
|
|
|
|||||||
Send Heartbeat |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
B ( |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
Send Sample “4” |
|
|
|
|
) |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
2 |
) |
||||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
( |
|
|
|
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
C |
|
A |
|
|
|
|
|
|||
A |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||
Send Sample “5” |
|
|
|
|
|
|
|
|
|
|
|
||
Send Heartbeat |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
B ( |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
) |
|
|
|
|
|
|
|
|
|
|
|
( |
|
|
|
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|||||
CK |
|
|
|
|
|
|
|
|
|||||
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
max_samples is 2. This also limits the |
|
|
|
|
|
|
|
|
|
|
|
number of unordered samples that |
|
|
|
|
|
|
|
|
|
|
|
can be cached. |
1 |
|
|
|
|
|
|
|
|
|
|
Move sample 1 to receive queue. |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
Note: no unordered samples cached |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Space reserved for missing sample “2”. |
||
|
|
3 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
||
|
|
3 |
|
|
|
|
|
Sample “4” must be dropped |
|||
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|||||
2 |
|
|
|
|
|
|
|
|
|
because it does not fit in the queue. |
|
|
|
|
|
|
|
|
|
|
Move samples 2 and 3 to receive queue. |
||
|
3 |
|
|
|
|
|
|
||||
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
Space reserved for missing sample “4”. |
|
4 |
|
|
|
|
|
|
|
|
Move samples 4 and 5 to receive queue. |
||
|
5 |
|
|
|
|
|
|
||||
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
10.3.3Controlling Queue Depth with the History QosPolicy
If you want to achieve strict reliability, set the kind field in the HISTORY QosPolicy (Section 6.5.10) for both the DataReader and DataWriter to KEEP_ALL; in this case, the depth does not matter.
Or, for
The depth field in the HISTORY QosPolicy (Section 6.5.10) controls how many samples Connext will attempt to keep on the DataWriter’s send queue or the DataReader’s receive queue. For reliable communications, depth should be >= 1. The depth can be set to 1, but cannot be more than the max_samples_per_instance in RESOURCE_LIMITS QosPolicy (Section 6.5.20).
Example:
❏ DataWriter
writer_qos.history.depth = <number of samples to keep in send queue>;
❏ DataReader
reader_qos.history.depth = <number of samples to keep in receive queue>;
10.3.4Controlling Heartbeats and Retries with DataWriterProtocol QosPolicy
In the Connext reliability model, the DataWriter sends data samples and heartbeats to reliable DataReaders. A DataReader responds to a heartbeat by sending an ACKNACK, which tells the DataWriter what the DataReader has received so far.
In addition, the DataReader can request missing samples (by sending an ACKNACK) and the DataWriter will respond by resending the missing samples. This section describes some advanced timing parameters that control the behavior of this mechanism. Many applications do not need to change these settings. These parameters are contained in the
DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
The protocol described in Overview of the Reliable Protocol (Section 10.2) uses very simple rules such as piggybacking HB messages to each DATA message and responding immediately to ACKNACKs with the requested repair messages. While correct, this protocol would not be capable of accommodating optimum performance in more advanced use cases.
This section describes some of the parameters configurable by means of the rtps_reliable_writer structure in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3) and how they affect the behavior of the RTPS protocol.
10.3.4.1How Often Heartbeats are Resent (heartbeat_period)
If a DataReader does not acknowledge a sample that has been sent, the DataWriter resends the heartbeat. These heartbeats are resent at the rate set in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3), specifically its heartbeat_period field.
For example, a heartbeat_period of 3 seconds means that if a DataReader does not receive the latest sample (for example, it gets dropped by the network), it might take up to 3 seconds before the DataReader realizes it is missing data. The application can lower this value when it is important that recovery from packet loss is very fast.
The basic approach of sending HB messages as a piggyback to DATA messages has the advantage of minimizing network traffic. However, there is a situation where this approach, by itself, may result in large latencies. Suppose there is a DataWriter that writes bursts of data, separated by relatively long periods of silence. Furthermore assume that the last message in one of the bursts is lost by the network. This is the case shown for message DATA(B, 2) in Figure 10.7. If HBs were only sent piggybacked to DATA messages, the DataReader would not realize it missed the ‘B’ DATA message with sequence number ‘2’ until the DataWriter wrote the next message. This may be a long time if data is written sporadically. To avoid this situation,
Connext can be configured so that HBs are sent periodically as long as there are samples that have not been acknowledged even if no data is being sent. The period at which these HBs are sent is configurable by setting the rtps_reliable_writer.heartbeat_period field in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
Note that a small value for the heartbeat_period will result in a small
Also note that the heartbeat_period should not be less than the rtps_reliable_reader.heartbeat_suppression_duration in the DATA_READER_PROTOCOL QosPolicy (DDS Extension) (Section 7.6.1); otherwise those HBs will be lost.
Figure 10.7 Use of heartbeat_period
DataWriter |
DataReader |
write(A)
1 A X
cache (A, 1)
DATA (A,1)
cache (A,1) 1 |
A 4 |
write(B)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cache(B,2) |
|
|
|
|
||||||
|
1 |
|
A |
X |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
DATA (B,2) |
|
|
||
|
2 |
|
B |
X |
|
heartbeat peri |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
acked(1) |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|||||||
|
|
get(2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
K(2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
KNAC |
|||
|
|
|
|
|
|
|
|
|
|
|
AC |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A( |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2) |
|
|
|
|
|
|
|
|
|
|
|
|
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B( |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
A |
4 |
|
|
|
|
|
|
|
|
|
|
K(3) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
KNAC |
||||
|
2 |
|
B |
4 |
|
|
|
|
|
|
AC |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
time |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 r
r
10.3.4.2How Often Piggyback Heartbeats are Sent (heartbeats_per_max_samples)
A DataWriter will automatically send heartbeats with new samples to request regular ACKNACKs from the DataReader. These are called “piggyback” heartbeats.

If batching is disabled1: one piggyback heartbeat will be sent every [max_samples2/ heartbeats_per_max_samples] number of samples.
If batching is enabled: one piggyback heartbeat will be sent every [max_batches3/ heartbeats_per_max_samples] number of samples.
Furthermore, one piggyback heartbeat will be sent per send window. If the above calculation is greater than the send window size, then the DataWriter will send a piggyback heartbeat for every [send window size] number of samples.
The heartbeats_per_max_samples field is part of the rtps_reliable_writer structure in the
DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3). If heartbeats_per_max_samples is set equal to max_samples, this means that a heartbeat will be sent with each sample. A value of 8 means that a heartbeat will be sent with every 'max_samples/ 8' samples. Say max_samples is set to 1024, then a heartbeat will be sent once every 128 samples. If you set this to zero, samples are sent without any piggyback heartbeat. The max_samples field is part of the RESOURCE_LIMITS QosPolicy (Section 6.5.20).
Figure 10.1 on page
There are two reasons to send a HB:
❏To request that a DataReader confirm the receipt of data via an ACKNACK, so that the
DataWriter can remove it from its send queue and therefore prevent the DataWriter’s history from filling up (which could cause the write() operation to temporarily block4).
❏To inform the DataReader of what data it should have received, so that the DataReader can send a request for missing data via an ACKNACK.
The DataWriter’s send queue can buffer many
A HB is used to get confirmation from DataReaders so that the DataWriter can remove acknowledged samples from the queue to make space for new samples. Therefore, if the queue size is large, or new samples are added slowly, HBs can be sent less frequently.
In Figure 10.8 on page
10.3.4.3Controlling Packet Size for Resent Samples (max_bytes_per_nack_response)
A repair packet is the maximum amount of data that a DataWriter will resend at a time. For example, if the DataReader requests 20 samples, each 10K, and the max_bytes_per_nack_response is set to 100K, the DataWriter will only send the first 10 samples. The DataReader will have to ACKNACK again to receive the next 10 samples.
1.Batching is enabled with the BATCH QosPolicy (DDS Extension) (Section 6.5.2).
2.max_samples is set in the RESOURCE_LIMITS QosPolicy (Section 6.5.20)
3.max_batches is set in the DATA_WRITER_RESOURCE_LIMITS QosPolicy (DDS Extension) (Section 6.5.4)
4.Note that data could also be removed from the DataWriter’s send queue if it is no longer relevant due to some other QoS such a HISTORY KEEP_LAST (Section 6.5.10) or LIFESPAN (Section 6.5.12).
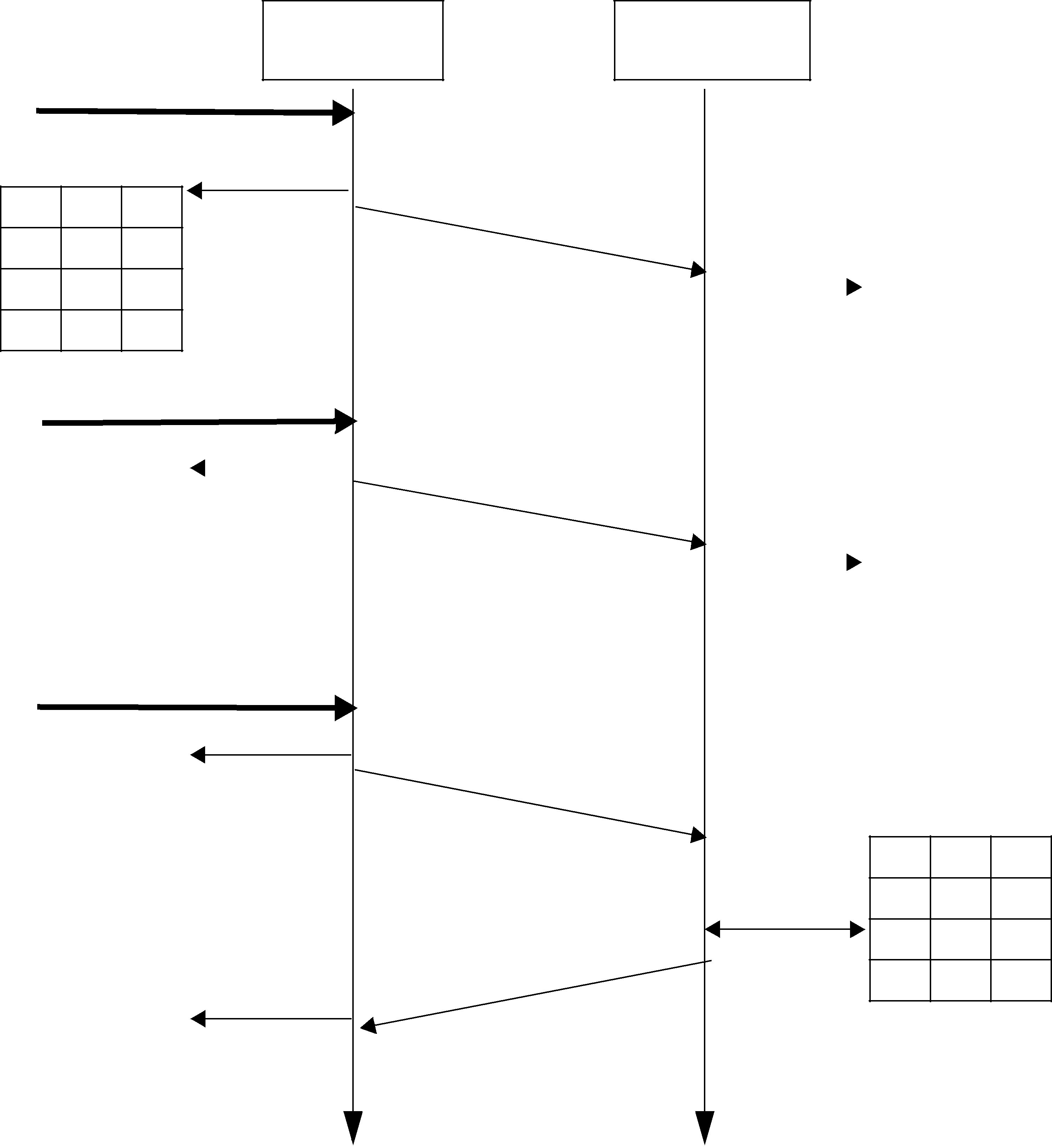
Figure 10.8 Use of heartbeats_per_max_samples
DataWriter |
DataReader |
write(A)
1 A X  cache (A, 1)
cache (A, 1)
write(B)
DATA (A,1)
cache (A,1) |
|
1 |
A |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
cache(B,2) |
|
|
|
1 |
A |
X |
|
|
||
|
|
|
|
|
|
|
2 |
B |
X |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
write(C)
DATA(B,2)
cache (B,2) |
|
1 |
A |
4 |
|
|
|
|
|
|
|
2 |
B |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
A |
X |
|
|
|
2 |
B |
X |
|
|
|
3 |
C |
X |
|
|
|
|
|
|
1 |
A |
4 |
|
|
|
2 |
B |
4 |
|
|
|
3 |
C |
4 |
|
|
|
|
|
|
cache(C,3)
D |
|
AT |
|
A( |
|
C,3);H |
|
|
|
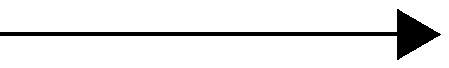 1 A 4
1 A 4
cache (C,3)
2 B 4
|
|
|
|
4) |
|
|
|
K( |
|
|
|
AC |
|
|
|
KN |
|
|
|
|
AC |
|
|
|
time |
|
|
|
time |
See Figure 10.1 for meaning of table columns.
A DataWriter may resend multiple missed samples in the same packet. The max_bytes_per_nack_response field in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3) limits the size of this ‘repair’ packet.
10.3.4.4Controlling How Many Times Heartbeats are Resent (max_heartbeat_retries)
If a DataReader does not respond within max_heartbeat_retries number of heartbeats, it will be dropped by the DataWriter and the reliable DataWriter’s Listener will be called with a
RELIABLE_READER_ACTIVITY_CHANGED Status (DDS Extension) (Section 6.3.6.8).
If the dropped DataReader becomes available again (perhaps its network connection was down temporarily), it will be added back to the DataWriter the next time the DataWriter receives some message (ACKNACK) from the DataReader.
When a DataReader is ‘dropped’ by a DataWriter, the DataWriter will not wait for the DataReader to send an ACKNACK before any samples are removed. However, the DataWriter will still send data and HBs to this DataReader as normal.
The max_heartbeat_retries field is part of the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
10.3.4.5Treating
In addition to max_heartbeat_retries, if inactivate_nonprogressing_readers is set, then not only are
One example for which it could be useful to turn on inactivate_nonprogressing_readers is when a DataReader’s
10.3.4.6Coping with Redundant Requests for Missing Samples (max_nack_response_delay)
When a DataWriter receives a request for missing samples from a DataReader and responds by resending the requested samples, it will ignore additional requests for the same samples during the time period max_nack_response_delay.
The rtps_reliable_writer.max_nack_response_delay field is part of the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
If your send period is smaller than the
While these redundant messages provide an extra cushion for the level of reliability desired, you can conserve the CPU and network bandwidth usage by limiting how often the same ACKNACK messages are sent; this is controlled by min_nack_response_delay.
Reliable subscriptions are prevented from resending an ACKNACK within min_nack_response_delay seconds from the last time an ACKNACK was sent for the same sample. Our testing shows that the default min_nack_response_delay of 0 seconds achieves an optimal balance for most applications on typical Ethernet LANs.
However, if your system has very slow computers and/or a slow network, you may want to consider increasing min_nack_response_delay. Sending an ACKNACK and resending a missing sample inherently takes a long time in this system. So you should allow a longer time for recovery of the lost sample before sending another ACKNACK. In this situation, you should increase min_nack_response_delay.
If your system consists of a fast network or computers, and the receive queue size is very small, then you should keep min_nack_response_delay very small (such as the default value of 0). If the queue size is small, recovering a missing sample is more important than conserving CPU and network bandwidth (new samples that are too far ahead of the missing sample are thrown away). A fast system can cope with a smaller min_nack_response_delay value, and the reliable sample stream can normalize more quickly.
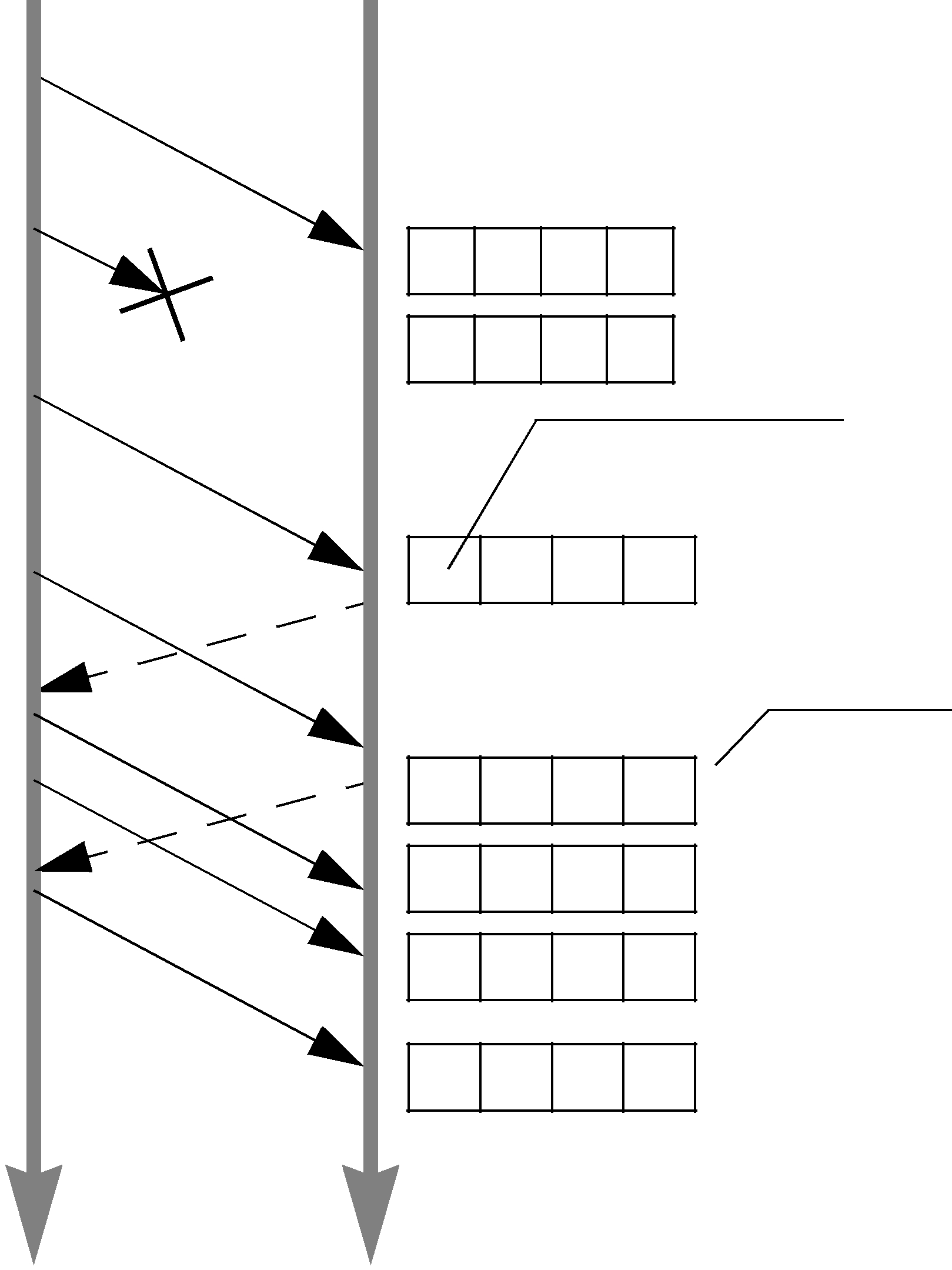
Figure 10.9 Resending Missing Samples due to Duplicate ACKNACKs
DataWriter DataReader
Send Sample “1” 
Send Sample “2” 
1
Send Sample “3” 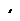
Send Sample “4” 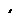
Resend Sample “2” 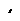 Send Sample “5”
Send Sample “5” 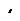
Resend Sample “2” 
|
|
|
|
|
|
|
|
) |
||
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
( |
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
) |
||
|
|
|
|
|
|
|
2 |
|
||
|
|
|
|
|
|
( |
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
|
|
|
C |
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3
3 4
2 3 4
5
Space must be reserved for missing sample “2”.
Samples “3” and “4” are cached while waiting for missing sample “2”.
Sample “2” is dropped since it is older than the last sample that has been handed to the application.
10.3.4.7Disabling Positive Acknowledgements (disable_postive_acks_min_sample_keep_duration)
When ACKNACK storms are a primary concern in a system, an alternative to tuning heartbeat and ACKNACK response delays is to disable positive acknowledgments (ACKs) and rely just on NACKs to maintain reliability. Systems with
Normally when ACKs are enabled, strict reliability is maintained by the DataWriter, guaranteeing that a sample stays in its send queue until all DataReaders have positively acknowledged it (aside from relevant DURABILITY, HISTORY, and LIFESPAN QoS policies). When ACKs are disabled, strict reliability is no longer guaranteed, but the DataWriter should still keep the sample for a sufficient duration for
The keep duration should be configured for the expected
If the peak send rate is known and writer resources are available, the writer queue can be sized so that writes will not block. For this case, the queue size must be greater than the send rate multiplied by the keep duration.
10.3.5Avoiding Message Storms with DataReaderProtocol QosPolicy
DataWriters send data samples and heartbeats to DataReaders. A DataReader responds to a heartbeat by sending an acknowledgement that tells the DataWriter what the DataReader has received so far and what it is missing. If there are many DataReaders, all sending ACKNACKs to the same DataWriter at the same time, a message storm can result. To prevent this, you can set a delay for each DataReader, so they don’t all send ACKNACKs at the same time. This delay is set in the DATA_READER_PROTOCOL QosPolicy (DDS Extension) (Section 7.6.1).
If you have several DataReaders per DataWriter, varying this delay for each one can avoid ACKNACK message storms to the DataWriter. If you are not concerned about message storms, you do not need to change this QosPolicy.
Example:
reader_qos.protocol.rtps_reliable_reader.min_heartbeat_response_delay.sec = 0; reader_qos.protocol.rtps_reliable_reader.min_heartbeat_response_delay.nanosec = 0; reader_qos.protocol.rtps_reliable_reader.max_heartbeat_response_delay.sec = 0; reader_qos.protocol.rtps_reliable_reader.max_heartbeat_response_delay.nanosec =
0.5 * 1000000000UL; // 0.5 sec
As the name suggests, the minimum and maximum response delay bounds the random wait time before the response. Setting both to zero will force immediate response, which may be necessary for the fastest recovery in case of lost samples.
10.3.6Resending Samples to
The DURABILITY QosPolicy (Section 6.5.7) is also somewhat related to Reliability. Connext requires a finite time to "discover" or match DataReaders to DataWriters. If an application attempts to send data before the DataReader and DataWriter "discover" one another, then the sample will not actually get sent. Whether or not samples are resent when the DataReader and DataWriter eventually "discover" one another depends on how the DURABILITY and HISTORY QoS are set. The default setting for the Durability QosPolicy is VOLATILE, which means that the DataWriter will not store samples for redelivery to
Connext also supports the TRANSIENT_LOCAL setting for the Durability, which means that the samples will be kept stored for redelivery to
See also: Waiting for Historical Data (Section 7.3.6).
10.3.7Use Cases
This section contains advanced material that discusses practical applications of the reliability related QoS.
10.3.7.1Importance of Relative Thread Priorities
For high throughput, the Connext Event thread’s priority must be sufficiently high on the sending application. Unlike an unreliable writer, a reliable writer relies on internal Connext threads: the Receive thread processes ACKNACKs from the DataReaders, and the Event thread schedules the events necessary to maintain reliable data flow.
❏When samples are sent to the same or another application on the same host, the Receive thread priority should be higher than the writing thread priority (priority of the thread calling write() on the DataWriter). This will allow the Receive thread to process the messages as they are sent by the writing thread. A sustained reliable flow requires the reader to be able to process the samples from the writer at a speed equal to or faster than the writer emits.
❏The default Event thread priority is low. This is adequate if your reliable transfer is not sustained; queued up events will eventually be processed when the writing thread yields the CPU. The Connext can automatically grow the event queue to store all pending events. But if the reliable communication is sustained, reliable events will continue to be scheduled, and the event queue will eventually reach its limit. The default Event thread priority is unsuitable for maintaining a fast and sustained reliable communication and should be increased through the participant_qos.event.thread.priority. This value maps directly to the OS thread priority, see EVENT QosPolicy (DDS Extension) (Section 8.5.5)).
The Event thread should also be increased to minimize the reliable latency. If events are processed at a higher priority, dropped packets will be resent sooner.
Now we consider some practical applications of the reliability related QoS:
❏Aperiodic Use Case:
❏Aperiodic, Bursty (Section 10.3.7.3)
10.3.7.2Aperiodic Use Case:
Suppose you have aperiodically generated data that needs to be delivered reliably, with minimum latency, such as a series of commands (“Ready,” “Aim,” “Fire”). If a writing thread may block between each sample to guarantee reception of the just sent sample on the reader’s middleware end, a smaller queue will provide a smaller upper bound on the sample delivery time. Adequate writer QoS for this use case are presented in Figure 10.10.
Figure 10.10 QoS for an Aperiodic,
1
2
3
5//use these hard coded value unless you use a key
6
7
8
9
10
12// want to piggyback HB w/ every sample.
13
14
15
16
17
18
19
20//consider making
21
22
24// should be faster than the send rate, but be mindful of OS resolution
25
26
27alertReaderWithinThisMs * 1000000;
29
30
32// essentially turn off slow HB period
33
Line 1 (Figure 10.10): This is the default setting for a writer, shown here strictly for clarity.
Line 2 (Figure 10.10): Setting the History kind to KEEP_ALL guarantees that no sample is ever lost.
Line 3 (Figure 10.10): This is the default setting for a writer, shown here strictly for clarity. ‘Push’ mode reliability will yield lower latency than ‘pull’ mode reliability in normal situations where there is no sample loss. (See DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).) Furthermore, it does not matter that each packet sent in response to a command will be small, because our data sent with each command is likely to be small, so that maximizing throughput for this data is not a concern.
Line 5 - Line 10 (Figure 10.10): For this example, we assume a single writer is writing samples one at a time. If we are not using keys (see Section 2.2.2), there is no reason to use a queue with room for more than one sample, because we want to resolve a sample completely before moving on to the next. While this negatively impacts throughput, it minimizes memory usage. In this example, a written sample will remain in the queue until it is acknowledged by all active readers (only 1 for this example).
Line 12 - Line 14 (Figure 10.10): The fastest way for a writer to ensure that a reader is
Line
Line
Line
❏Suppose that the
end, and assuming that this retry succeeds, the time to recover the sample from the original publication time is: alertReaderWithinThisMs + 50 sec + 25 sec.
If the OS is capable of
❏What if two packets are dropped in a row? Then the recovery time would be
2 * alertReaderWithinThisMs + 2 * 50 sec + 25 sec. If alertReaderWithinThisMs is 100 ms, the recovery time now exceeds 200 ms, and can perhaps degrade user experience.
Line
So if we set blockingTime to about 80 ms, we will have given enough chance for recovery. Of course, in a dynamic system, a reader may drop out at any time, in which case max_heartbeat_retries will be exceeded, and the unresponsive reader will be dropped by the writer. In either case, the writer can continue writing. Inappropriate values will cause a writer to prematurely drop a temporarily unresponsive (but otherwise healthy) reader, or be stuck trying unsuccessfully to feed a crashed reader. In the unfortunate case where a reader becomes temporarily unresponsive for a duration exceeding (alertReaderWithinThisMs * max_heartbeat_retries), the writer may issue gaps to that reader when it becomes active again; the dropped samples are irrecoverable. So estimating the worst case unresponsive time of all potential readers is critical if sample drop is unacceptable.
Line
Figure 10.11 shows how to set the QoS for the reader side, followed by a
Figure 10.11 QoS for an Aperiodic,
1
2
3
4// 1 is ok for normal use. 2 allows fast infinite loop
5
6
7
9
10
11
12
Line
Line
1.The sender application writes sample 1 to the reader. The receiver application processes it and sends a
2.The sender application writes sample 2 to the receiving application in response to response 1. Because the reader’s queue is 2, it can accept sample 2 even though it may not yet have acknowledged sample 1. Otherwise, the reader may drop sample 2, and would have to recover it later.
3.At the same time, the receiver application acknowledges sample 1, and frees up one slot in the queue, so that it can accept sample 3, which it on its way.
The above steps can be repeated
Line 7 (Figure 10.11): Since we are not using keys, there is just one instance.
Line
10.3.7.3Aperiodic, Bursty
Suppose you have aperiodically generated bursts of data, as in the case of a new aircraft approaching an airport. The data may be the same or different, but if they are written by a single writer, the challenge to this writer is to feed all readers as quickly and efficiently as possible when this burst of hundreds or thousands of samples hits the system.
❏If you use an unreliable writer to push this burst of data, some of them may be dropped over an unreliable transport such as UDP.
❏If you try to shape the burst according to however much the slowest reader can process, the system throughput may suffer, and places an additional burden of queueing the samples on the sender application.
❏If you push the data reliably as fast they are generated, this may cost dearly in repair packets, especially to the slowest reader, which is already burdened with application chores.
Connext pull mode reliability offers an alternative in this case by letting each reader pace its own data stream. It works by notifying the reader what it is missing, then waiting for it to request only as much as it can handle. As in the aperiodic
Line 1 (Figure 10.12): This is the default setting for a writer, shown here strictly for clarity.
Line 2 (Figure 10.12): Since we do not want any data lost, we want the History kind set to KEEP_ALL.
Figure 10.12 QoS for an Aperiodic, Bursty Writer
1
2
3
5//use these hard coded value until you use key
6
7
8
9= worstBurstInSample;
10
11
12
13// piggyback HB not used
14
16
17
19
20
21
22
23
25// should be faster than the send rate, but be mindful of OS resolution
26
27
28alertReaderWithinThisMs * 1000000;
29
31// essentially turn off slow HB period
32
Line 3 (Figure 10.12): The default Connext reliable writer will push, but we want the reader to pull instead.
Line
Line
Line
Line 19- Line 23 (Figure 10.12): Similar to the
this time will decrease; other factors such as the traversal time through Connext and the transport are typically in microseconds range (depending on machines of course).
For example, let’s also say that the worst case burst is 1000 samples. The writing thread will of course not block because it is merely copying each of the 1000 samples to the Connext queue on the writer side; on a typical modern machine, the act of writing these 1000 samples will probably take no more than a few ms. But it would take at least 1000/20 = 50 resend packets for the reader to catch up to the writer, or 50 times 11 ms = 550 ms. Since the burst model deals with one burst at a time, we would expect that another burst would not come within this time, and that we are allowed to block for at least this period. Including a safety margin, it would appear that we can comfortably handle a burst of 1000 every second or so.
But what if there are multiple readers? The writer would then take more time to feed multiple readers, but with a fast transport, a few more readers may only increase the 11 ms to only 12 ms or so. Eventually, however, the number of readers will justify the use of multicast. Even in pull mode, Connext supports multicast by measuring how many multicast readers have requested sample repair. If the writer does not delay response to NACK, then repairs will be sent in unicast. But a suitable NACK delay allows the writer to collect potentially NACKs from multiple readers, and feed a single multicast packet. But as discussed in Section 10.3.7.2, by delaying reply to coalesce response, we may end up waiting much longer than desired. On a Windows system with 10 ms minimum sleep achievable, the delay would add at least 10 ms to the 11 ms delay, so that the time to push 1000 samples now increases to 50 times 21 ms = 1.05 seconds. It would appear that we will not be able to keep up with incoming burst if it came at roughly 1 second, although we put fewer packets on the wire by taking advantage of multicast.
Line
Line 29 (Figure 10.12): With a fast heartbeat period of 50 ms, a writer will take 500 ms (50 ms times the default max_heartbeat_retries of 10) to
Line
Figure 10.13 shows example code for a corresponding aperiodic, bursty reader.
Figure 10.13 QoS for an Aperiodic, Bursty Reader
1
2
3
4
5
7//use these hard coded value until you use key
8
9
10
11
13// the writer probably has more for the reader; ask right away
14
15
16
17
Line
Line
Line
Line
10.3.7.4Periodic
In a periodic reliable model, we can use the writer and the reader queue to keep the data flowing at a smooth rate. The data flows from the sending application to the writer queue, then to the transport, then to the reader queue, and finally to the receiving application. Unless the sending application or any one of the receiving applications becomes unresponsive (including a crash) for a noticeable duration, this flow should continue uninterrupted.
The latency will be low in most cases, but will be several times higher for the recovered and many subsequent samples. In the event of a disruption (e.g., loss in transport, or one of the readers becoming temporarily unresponsive), the writer’s queue level will rise, and may even block in the worst case. If the writing thread must not block, the writer’s queue must be sized sufficiently large to deal with any fluctuation in the system. Figure 10.14 shows an example, with
Line 1 (Figure 10.14): This is the default setting for a writer, shown here strictly for clarity.
Line 2 (Figure 10.14): Since we do not want any data lost, we set the History kind to KEEP_ALL.
Line 3 (Figure 10.14): This is the default setting for a writer, shown here strictly for clarity. Pushing will yield lower latency than pulling.
Line
Line
Figure 10.14 QoS for a Periodic Reliable Writer
1
2
3
5//use these hard coded value until you use key
6
7
9int unresolvedSamplePerRemoteWriterMax =
10worstCaseApplicationDelayTimeInMs * dataRateInHz / 1000;
11
12
13
14 |
|
15 |
|
16int piggybackEvery = 8;
17
18
19
20
21
22
23
24
25
27
28
30
31
32alertReaderWithinThisMs * 1000000;
33
35// essentially turn off slow HB period
36
Line 12 (Figure 10.14): Even though we have sized the queue according to the worst case, there is a possibility for saving some memory in the normal case. Here, we initially size the queue to be only half of the worst case, hoping that the worst case will not occur. When it does, Connext will keep increasing the queue size as necessary to accommodate new samples, until the maximum is reached. So when our optimistic initial queue size is breached, we will incur the penalty of dynamic memory allocation. Furthermore, you will wind up using more memory, as the initially allocated memory will be orphaned (note: does not mean a memory leak or dangling pointer); if the initial queue size is M_i and the maximal queue size is M_m, where M_m = M_i * 2^n, the memory wasted in the worst case will be (M_m - 1) * sizeof(sample) bytes. Note that the memory allocation can be avoided by setting the initial queue size equal to its max value.
Line
Line
Line
for the fast heartbeat period is to allow a writer to abandon inactive readers before the queue fills. If the high watermark is set equal to the queue size, the writer would not doubt the status of an unresponsive reader until the queue completely
Line
Line
Line
Figure 10.15 shows how to set the QoS for a matching reader, followed by a
Figure 10.15 QoS for a Periodic Reliable Reader
1
2
3
4
5
6((2*piggybackEvery - 1) + dataRateInHz * delayInMs / 1000);
8//use these hard coded value until you use key
9
10
11
12
14
15
16
17
Line
Line
but to drop all subsequent samples received until the one being sought is recovered. Connext uses speculative caching, which minimizes the disruption caused by a few dropped samples. Even for the same duration of disruption, the demand on reader queue size is greater if the writer will send more rapidly. In sizing the reader queue, we consider 2 factors that comprise the lost sample recovery time:
❏How long it takes a reader to request a resend to the writer.
The piggyback heartbeat tells a reader about the writer’s state. If only samples between two piggybacked samples are dropped, the reader must cache piggybackEvery samples before asking the writer for resend. But if a piggybacked sample is also lost, the reader will not get around to asking the writer until the next piggybacked sample is received. Note that in this worst case calculation, we are ignoring
❏How long it takes for the writer to respond to the request.
Even ignoring the flight time of the resend request through the transport, the writer takes a finite time to respond to the repair
Line
Line
Chapter 11 Collaborative DataWriters
The Collaborative DataWriters feature allows you to have multiple DataWriters publishing samples from a common logical data source. The DataReaders will combine the samples coming from these DataWriters in order to reconstruct the correct order in which they were produced at the source. This combination process for the DataReaders can be configured using the AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1). It requires the middleware to provide a way to uniquely identify every sample published in a domain independently of the actual DataWriter that published the sample.
In Connext, every modification (sample) to the global dataspace made by a DataWriter within a domain is identified by a pair (virtual GUID, sequence number).
❏The virtual GUID (Global Unique Identifier) is a
❏The virtual sequence number is a
Several DataWriters can be configured with the same virtual GUID. If each of these DataWriters publishes a sample with sequence number '0', the sample will only be received once by the DataReaders subscribing to the content published by the DataWriters (see Figure 11.1).
Figure 11.1 Global Dataspace Changes
11.1Collaborative DataWriters Use Cases
❏Ordered delivery of samples in high availability scenarios
One example of this is RTI Persistence Service1. When a
❏Ordered delivery of samples in
Multiple instances of the same application can work together to process and deliver samples. When the samples arrive through different
❏Ordered delivery of samples with Group Ordered Access
The Collaborative DataWriters feature can also be used to configure the sample ordering process when the Subscriber is configured with PRESENTATION QosPolicy (Section 6.4.6) access_scope set to GROUP. In this case, the Subscriber must deliver in order the samples published by a group of DataWriters that belong to the same Publisher and have access_scope set to GROUP.
Figure 11.2
1. For more information on Persistence Service, see Part 6: RTI Persistence Service.

11.2Sample Combination (Synchronization) Process in a DataReader
A DataReader will deliver a sample (VGUIDn, VSNm) to the application only when if one of the following conditions is satisfied:
❏(GUIDn,
❏All the known DataWriters publishing VGUIDn have announced that they do not have (VGUIDn,
❏None of the known DataWriters publishing VGUIDn have announced potential availability of (VGUIDn,
For additional details on how the reconstruction process works see the AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1).
11.3Configuring Collaborative DataWriters
11.3.1Assocating Virtual GUIDs with Data Samples
There are two ways to associate a virtual GUID with the samples published by a DataWriter.
❏Per DataWriter: Using virtual_guid in DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
❏Per Sample: By setting the writer_guid in the identity field of the WriteParams_t structure provided to the write_w_params operation (see Writing Data (Section 6.3.8)). Since the writer_guid can be set per sample, the same DataWriter can potentially write samples from independent logical data sources. One example of this is RTI Persistence Service where a single persistence service DataWriter can write samples on behalf of multiple original DataWriters.
11.3.2Assocating Virtual Sequence Numbers with Data Samples
You can associate a virtual sequence number with a sample published by a DataWriter by setting the sequence_number in the identity field of the WriteParams_t structure provided to the write_w_params operation (see Writing Data (Section 6.3.8)). Virtual sequence numbers for a given virtual GUID must be strictly monotonically increasing. If you try to write a sample with a sequence number less than or equal to the last sequence number, the write operation will fail.
11.3.3Specifying which DataWriters will Deliver Samples to the DataReader from a Logical Data Source
The required_matched_endpoint_groups field in the AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1) can be used to specify the set of DataWriter groups that are expected to provide samples for the same data source (virtual GUID). The quorum count in a group represents the number of DataWriters that must be discovered for that group before the DataReader is allowed to provide
A DataWriter becomes a member of an endpoint group by configuring the role_name in ENTITY_NAME QosPolicy (DDS Extension) (Section 6.5.9).

11.3.4Specifying How Long to Wait for a Missing Sample
A DataReader’s AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1) specifies how long to wait for a missing sample. For example, this is important when the first sample is received: how long do you wait to determine the lowest sequence number available in the system?
❏The max_data_availability_waiting_time defines how much time to wait before delivering a sample to the application without having received some of the previous samples.
❏The max_endpoint_availability_waiting_time defines how much time to wait to discover DataWriters providing samples for the same data source (virtual GUID).
11.4Collaborative DataWriters and Persistence Service
The DataWriters created by persistence service are automatically configured to do collaboration:
❏Every sample published by the Persistence Service DataWriter keeps its original identity.
❏Persistence Service associates the role name PERSISTENCE_SERVICE with all the DataWriters that it creates. You can overwrite that setting by changing the DataWriter QoS configuration in persistence service.
For more information, see Part 6: RTI Persistence Service.
Chapter 12 Mechanisms for Achieving Information Durability and Persistence
12.1Introduction
Connext offers the following mechanisms for achieving durability and persistence:
❏Durable Writer History This feature allows a DataWriter to persist its historical cache, perhaps locally, so that it can survive shutdowns, crashes and restarts. When an application restarts, each DataWriter that has been configured to have durable writer history automatically load all of the data in this cache from disk and can carry on sending data as if it had never stopped executing. To the rest of the system, it will appear as if the DataWriter had been temporarily disconnected from the network and then reappeared.
❏Durable Reader State This feature allows a DataReader to persist its state and remember which data it has already received. When an application restarts, each DataReader that has been configured to have durable reader state automatically loads its state from disk and can carry on receiving data as if it had never stopped executing. Data that had already been received by the DataReader before the restart will be suppressed so that it is not even sent over the network.
❏Data Durability This feature is a full implementation of the OMG DDS Persistence Profile. The DURABILITY QosPolicy (Section 6.5.7) allows an application to configure a DataWriter so that the information written by the DataWriter survives beyond the lifetime of the DataWriter. In this manner, a
These features can be configured separately or in combination. To use Durable Writer State and Durable Reader State, you need a relational database, which is not included with Connext. Supported databases are listed in the Release Notes. Persistence Service does not require a database when used in TRANSIENT mode (see Section 12.5.1) or in PERSISTENT mode with
To understand how these features interact we will examine the behavior of the system using the following scenarios:
❏Scenario 1. DataReader Joins after DataWriter Restarts (Durable Writer History) (Section 12.1.1)
❏Scenario 2: DataReader Restarts While DataWriter Stays Up (Durable Reader State) (Section 12.1.2)

❏Scenario 3. DataReader Joins after DataWriter Leaves Domain (Durable Data) (Section 12.1.3)
12.1.1Scenario 1. DataReader Joins after DataWriter Restarts (Durable Writer History)
In this scenario, a DomainParticipant joins the domain, creates a DataWriter and writes some data, then the DataWriter shuts down (gracefully or due to a fault). The DataWriter restarts and a DataReader joins the domain. Depending on whether the DataWriter is configured with durable history, the
Figure 12.1 Durable Writer History
DataWriter |
|
DataWriter |
|
|
|
a |
|
|
|
a |
|
|
||
|
|
|
|
|
b |
|
|
|
b |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DataReader |
|
|
|
|
|||||
|
|
|
DataReader |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a
b
Without Durable Writer History:
the
With Durable Writer History:
the restarted DataWriter will recover its history and deliver its data to the late- joining DataReader
12.1.2Scenario 2: DataReader Restarts While DataWriter Stays Up (Durable Reader State)
In this scenario, two DomainParticipants join a domain; one creates a DataWriter and the other a DataReader on the same Topic. The DataWriter publishes some data ("a" and "b") that is received by the DataReader. After this, the DataReader shuts down (gracefully or due to a fault) and then
Depending on whether the DataReader is configured with Durable Reader State, the DataReader may or may not receive a duplicate copy of the data it received before it restarted. This is illustrated in Figure 12.2. For more information, see Durable Reader State (Section 12.4).
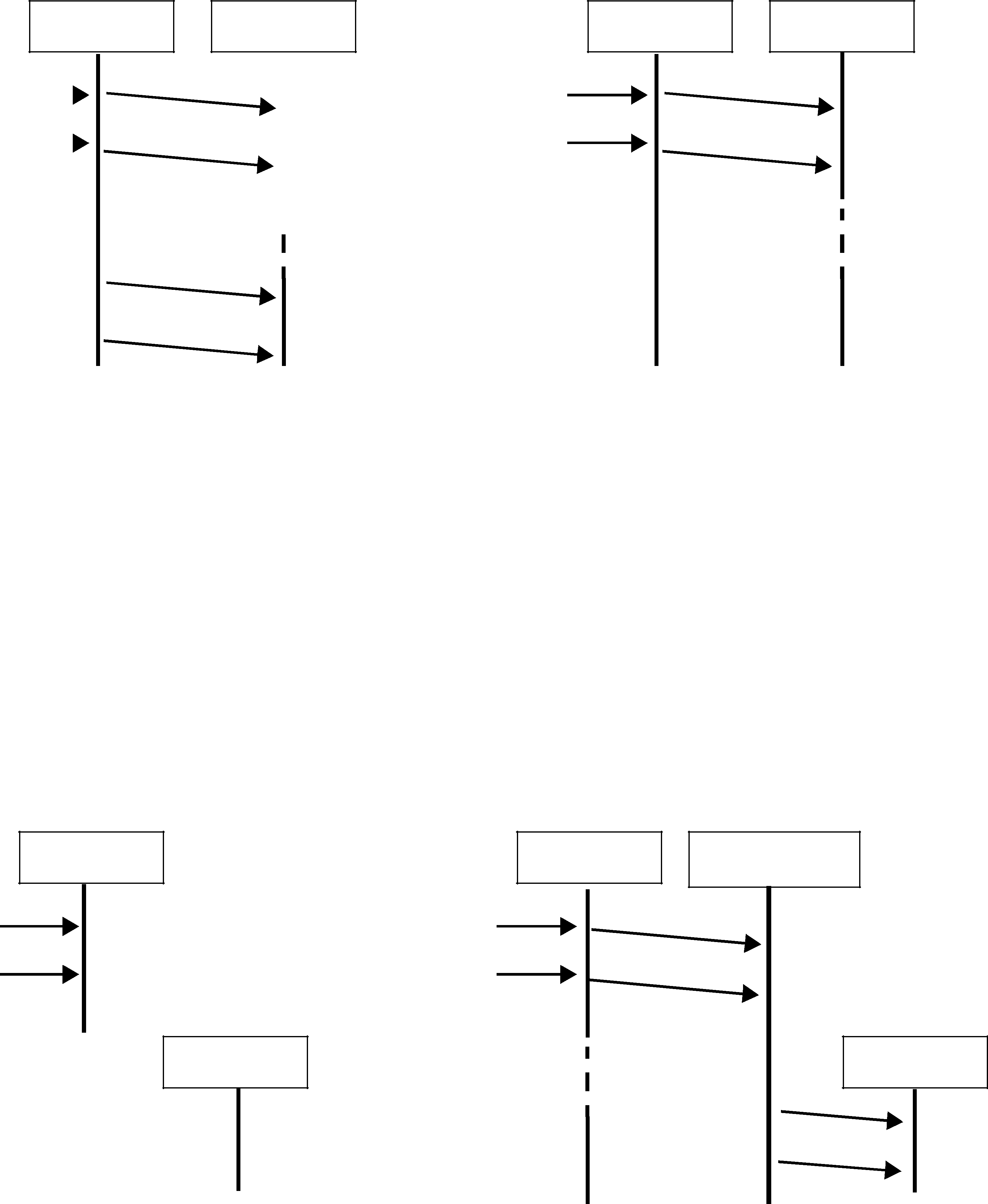
Figure 12.2 Durable Reader State
DataWriter DataReader
a |
a |
b |
b |
|
|
|
|
|
|
|
|
a b
Without Durable Reader State:
the DataReader will receive the data that was already received before the restart.
DataWriter DataReader
a a
b b
With Durable Reader State:
the DataReader remembers that it already received the data and does not request it again.
12.1.3Scenario 3. DataReader Joins after DataWriter Leaves Domain (Durable Data)
In this scenario, a DomainParticipant joins a domain, creates a DataWriter, publishes some data on a Topic and then shuts down (gracefully or due to a fault). Later, a DataReader joins the domain and subscribes to the data. Persistence Service is running.
Depending on whether Durable Data is enabled for the Topic, the DataReader may or may not receive the data previous published by the DataWriter. This is illustrated in Figure 12.3. For more information, see Data Durability (Section 12.5)
Figure 12.3 Durable Data
DataWriter
a
b
DataReader
Without Durable Data:
the
DataWriter Persistence
Service
a a
b b
DataReader
a
b
With Durable Data:
Persistence Service remembers what data was published and delivers it to the
This third scenario is similar to Scenario 1. DataReader Joins after DataWriter Restarts (Durable Writer History) (Section 12.1.1) except that in this case the DataWriter does not need to restart for the DataReader to get the data previously written by the DataWriter. This is because Persistence Service acts as an intermediary that stores the data so it can be given to
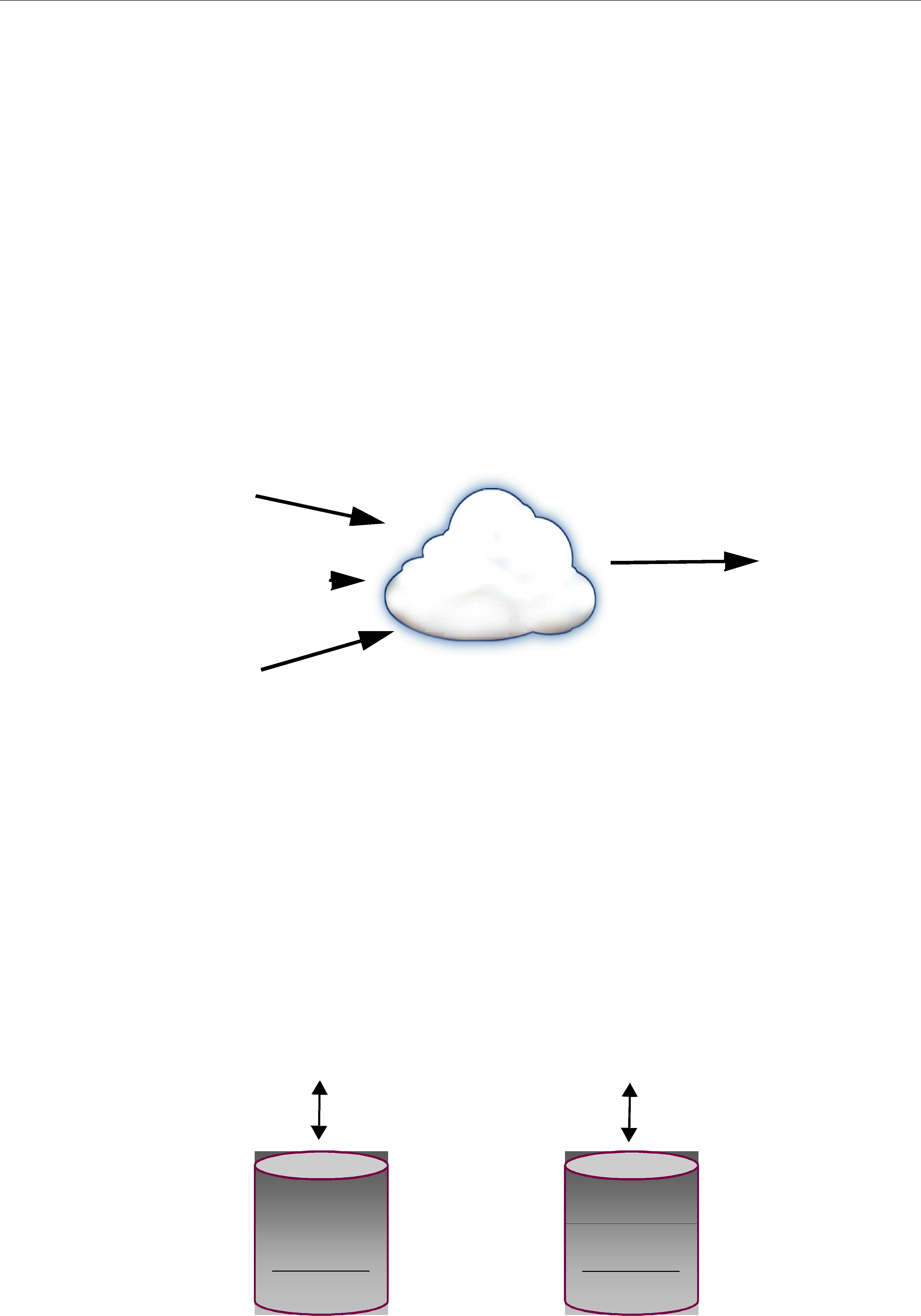
12.2Durability and Persistence Based on Virtual GUIDs
Every modification to the global dataspace made by a DataWriter is identified by a pair (virtual GUID, sequence number).
❏The virtual GUID (Global Unique Identifier) is a
❏The sequence number is a
DataWriter.
Several DataWriters can be configured with the same virtual GUID. If each of these DataWriters publishes a sample with sequence number '0', the sample will only be received once by the DataReaders subscribing to the content published by the DataWriters (see Figure 12.4).
Figure 12.4 Global Dataspace Changes
|
DataWriter |
|
(vg: 1, sn: 0) |
|
|
|
|
||
|
(vg: 1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(vg: 1, sn: 0) |
|
|
|
|
|
|
|
|
(vg: 1, sn: 0) |
DataReader |
||
|
|
|
|
|
|
|
|
||
|
DataWriter |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
(vg: 1) |
||
|
|
|
|
|
|
|
|
||
|
(vg: 1) |
|
|
|
|
(vg: 2, sn: 0) |
(vg: 2, sn: 0) |
||
|
|
|
|
|
|
||||
|
|
|
(vg: 1, sn: 0) |
|
|
|
|||
|
|
|
|
|
|
|
|
||
DataWriter |
|
|
|
|
|
|
|
||
(vg: 2) |
|
(vg: 2, sn: 0) |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
Additionally, Connext uses the virtual GUID to associate a persisted state (state in permanent storage) to the corresponding Entity.
For example, the history of a DataWriter will be persisted in a database table with a name generated from the virtual GUID of the DataWriter. If the DataWriter is restarted, it must have associated the same virtual GUID to restore its previous history.
Likewise, the state of a DataReader will be persisted in a database table whose name is generated from the DataReader virtual GUID (see Figure 12.5).
Figure 12.5 History/State Persistence Based on the Virtual GUID
DataWriter |
|
DataReader |
|
|
|
vg: 1 |
|
|
|
vg: 1 |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A DataWriter’s virtual GUID can be configured using the member virtual_guid in the DATA_WRITER_PROTOCOL QosPolicy (DDS Extension) (Section 6.5.3).
A DataReader’s virtual GUID can be configured using the member virtual_guid in the DATA_READER_PROTOCOL QosPolicy (DDS Extension) (Section 7.6.1).
The DDS_PublicationBuiltinTopicData and DDS_SubscriptionBuiltinTopicData structures include the virtual GUID associated with the discovered publication or subscription (see
12.3Durable Writer History
The DURABILITY QosPolicy (Section 6.5.7) controls whether or not, and how, published samples are stored by the DataWriter application for DataReaders that are found after the samples were initially written. The samples stored by the DataWriter constitute the DataWriter’s history.
Connext provides the capability to make the DataWriter history durable, by persisting its content in a relational database. This makes it possible for the history to be restored when the DataWriter restarts. See the Release Notes for the list of supported relational databases.
The association between the history stored in the database and the DataWriter is done using the virtual GUID.
12.3.1Durable Writer History Use Case
The following use case describes the durable writer history functionality:
1.A DataReader receives two samples with sequence number 1 and 2 published by a DataWriter with virtual GUID 1.
1, 2 |
|
DataWriter |
1, 2 |
|
DataReader |
1, 2 |
||
|
|
|
|
|
|
|
||
|
|
(vg: 1) |
|
|
|
(vg: 1) |
|
|
|
|
|
|
|
|
|
|
|
2.The process running the DataWriter is stopped and a new
DataReader (vg: 1)
DataReader (vg: 2)
The new DataReader with virtual GUID 2 does not receive samples 1 and 2 because the original DataWriter has been destroyed. If the samples must be available to
DataReaders after the DataWriter deletion, you can use Persistence Service, described in Chapter 26: Introduction to RTI Persistence Service.
3. The DataWriter is restarted using the same virtual GUID.
DataWriter
DataReader
(vg: 1)
1, 2
(vg: 1)
DataReader |
|
1, 2 |
(vg: 2) |
|
|
|
||
|
|
|

After being restarted, the DataWriter restores its history. The
4. The DataWriter publishes two new samples.
|
|
|
3, 4 |
DataReader |
3, 4 |
||
|
|
|
|
|
|
||
|
DataWriter |
|
|
(vg: 1) |
|
|
|
|
(vg: 1) |
|
3, 4 |
|
|
3, 4 |
|
|
|
|
|
||||
|
|
|
|
|
|||
|
|
|
DataReader |
|
|||
|
|
|
|
|
|||
|
|
|
|
(vg: 2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The two new samples with sequence numbers 3 and 4 will be received by both DataRead- ers.
12.3.2How To Configure Durable Writer History
Connext allows a DataWriter’s history to be stored in a relational database that provides an ODBC driver.
For each DataWriter history that is configured to be durable, Connext will create a maximum of two tables:
❏The first table is used to store the samples associated with the writer history. The name of that table is WS<32 uuencoding of the writer virtual GUID>.
❏The second table is only created for
To configure durable writer history, use the PROPERTY QosPolicy (DDS Extension) (Section 6.5.17) associated with DataWriters and DomainParticipants.
A ‘durable writer history’ property defined in the DomainParticipant will be applicable to all the DataWriters belonging to the DomainParticipant unless it is overwritten by the DataWriter. Table 12.1 lists the supported ‘durable writer history’ properties.
Table 12.1 Durable Writer History Properties
Property |
Description |
|
|
|
Required. |
dds.data_writer.history.plugin_name |
Must be set to "dds.data_writer.history.odbc_plugin.builtin" to enable |
|
durable writer history in the DataWriter. |
|
|
dds.data_writer.history.odbc_plugin. |
Required. |
The ODBC DSN (Data Source Name) associated with the database where |
|
dsn |
the writer history must be persisted. |
|
|
|
|
|
Tells Connext which ODBC driver to load. If the property is not |
dds.data_writer.history.odbc_plugin. |
specified, Connext will try to use the standard ODBC driver manager |
driver |
library (UnixOdbc on UNIX/Linux systems, the Windows ODBC driver |
|
manager on Windows systems). |
|
|
dds.data_writer.history.odbc_plugin. |
|
username |
Configures the username/password used to connect to the database. |
|
Default: No password or username |
dds.data_writer.history.odbc_plugin. |
|
password |
|
|
|
|
When set to 1, Connext will create a single connection per DSN that will |
dds.data_writer.history.odbc_plugin. |
be shared across DataWriters within the same Publisher. |
shared |
A DataWriter can be configured to create its own database connection by |
|
setting this property to 0 (the default). |
|
|
Table 12.1 Durable Writer History Properties
Property |
|
|
Description |
|
|
||
|
|
||||||
|
|
||||||
dds.data_writer.history.odbc_plugin. |
These properties configure the resource limits associated with the ODBC |
||||||
instance_cache_max_size |
writer history caches. |
|
|
|
|
||
|
To minimize the number of accesses to the database, Connext uses two |
||||||
dds.data_writer.history.odbc_plugin. |
|||||||
instance_cache_init_size |
caches, one for samples and one for instances. The initial size and the |
||||||
|
maximum size of these caches are configured using these properties. |
|
|||||
dds.data_writer.history.odbc_plugin. |
|
||||||
sample_cache_max_size |
The resource limits, initial_instances, max_instances, initial_samples, |
||||||
max_samples, |
and |
max_samples_per_instance |
defined |
in |
|||
|
|||||||
|
|||||||
|
RESOURCE_LIMITS QosPolicy (Section 6.5.20) are used to configure the |
||||||
|
maximum number of samples and instances that can be stored in the |
||||||
|
relational database. |
|
|
|
|
||
|
Defaults: |
|
|
|
|
|
|
|
❏ instance_cache_max_size: |
max_instances |
in |
||||
|
|
|
|||||
dds.data_writer.history.odbc_plugin. |
❏ instance_cache_init_size: |
initial_instances |
in |
||||
sample_cache_init_size |
|
|
|||||
|
❏ sample_cache_max_size: 32 |
|
|
|
|||
|
❏ sample_cache_init_size: 32 |
|
|
|
|||
|
Note: If the property in_memory_state (see below in this table) is 1, |
||||||
|
then instance_cache_max_size is always equal to max_instances in |
||||||
|
RESOURCE_LIMITS QosPolicy (Section |
||||||
|
changed. |
|
|
|
|
|
|
|
|
||||||
|
This property indicates whether or not the persisted writer history must |
||||||
|
be restored once the DataWriter is restarted. |
|
|
||||
dds.data_writer.history.odbc_plugin. |
If this property is 0, the content of the database associated with the |
||||||
DataWriter being restarted will be deleted. |
|
|
|
||||
restore |
If it is 1, the DataWriter will restore its previous state from the database |
||||||
|
|||||||
|
content. |
|
|
|
|
|
|
|
Default: 1 |
|
|
|
|
|
|
|
|
||||||
|
This property determines how much state will be kept in memory by the |
||||||
|
ODBC writer history in order to avoid accessing the database. |
|
|||||
|
If this property is 1, then the property |
instance_cache_max_size (see |
|||||
|
above in this table) is always equal to max_instances |
in |
|||||
|
RESOURCE_LIMITS QosPolicy (Section |
||||||
|
In addition, the ODBC writer history will keep in memory a fixed state |
||||||
dds.data_writer.history.odbc_plugin. |
overhead of 24 bytes per sample. This mode provides the best ODBC |
||||||
in_memory_state |
writer history performance. However, the restore operation will be |
||||||
|
slower and the maximum number of samples that the writer history can |
||||||
|
manage is limited by the available physical memory. |
|
|
||||
|
If it is 0, all the state will be kept in the underlying database. In this |
||||||
|
mode, the maximum number of samples in the writer history is not |
||||||
|
limited by the physical memory available. |
|
|
|
|||
|
Default: 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Note: Durable Writer History is not supported for
See also: Durable Reader State (Section 12.4).
Example C++ Code
/* Get default QoS */
...
retcode = DDSPropertyQosPolicyHelper::add_property (writerQos.property, "dds.data_writer.history.plugin_name", "dds.data_writer.history.odbc_plugin.builtin",

DDS_BOOLEAN_FALSE);
if (retcode != DDS_RETCODE_OK) { /* Report error */
}
retcode = DDSPropertyQosPolicyHelper::add_property (writerQos.property, "dds.data_writer.history.odbc_plugin.dsn",
"<user DSN>", DDS_BOOLEAN_FALSE);
if (retcode != DDS_RETCODE_OK) { /* Report error */
}
retcode = DDSPropertyQosPolicyHelper::add_property (writerQos.property, "dds.data_writer.history.odbc_plugin.driver",
"<ODBC library>", DDS_BOOLEAN_FALSE);
if (retcode != DDS_RETCODE_OK) { /* Report error */
}
retcode = DDSPropertyQosPolicyHelper::add_property (writerQos.property, "dds.data_writer.history.odbc_plugin.shared", "<0|1>",
DDS_BOOLEAN_FALSE); if (retcode != DDS_RETCODE_OK) {
/* Report error */
}
/* Create Data Writer */
...
12.4Durable Reader State
Durable reader state allows a DataReader to locally store its state in disk and remember the data that has already been processed by the application1. When an application restarts, each DataReader configured to have durable reader state automatically reads its state from disk. Data that has already been processed by the application before the restart will not be provided to the application again.
Important: The DataReader does not persist the full contents of the data in its historical cache; it only persists an identification (e.g. sequence numbers) of the data the application has processed. This distinction is not meaningful if your application always uses the ‘take’ methods to access your data, since these methods remove the data from the cache at the same time they deliver it to your application. (See Read vs. Take (Section 7.4.3.1)) However, if your application uses the ‘read’ methods, leaving the data in the DataReader's cache after you've accessed it for the first time, those previously viewed samples will not be restored to the DataReader's cache in the event of a restart.
Connext requires a relational database to persist the state of a DataReader. This database is accessed using ODBC. See the Release Notes for the list of supported relational databases.
12.4.1Durable Reader State With Protocol Acknowledgment
For each DataReader configured to have durable state, Connext will create one database table with the following naming convention: RS<32 uuencoding of the reader virtual GUID>. This table will store the last sequence number processed from each virtual GUID. For DataReaders on
1.The circumstances under which a data sample is considered “processed by the application” are described in the sections that follow.
keyed topics requesting
Criteria to consider a sample “processed by the application”
❏For the read/take methods that require calling return_loan(), a sample 's1' with sequence number 's1_seq_num' and virtual GUID ‘vg1’ is considered processed by the application when the DataReader’s return_loan() operation is called for sample 's1' or any other sample with the same virtual GUID and a sequence number greater than 's1_seq_num'. For example:
retcode =
if (retcode == DDS_RETCODE_NO_DATA) { return;
}else if (retcode != DDS_RETCODE_OK) { /* report error */
return;
}
for (i = 0; i < data_seq.length(); ++i) { /* Operate with the data */
}
/* Return the loan */
retcode =
/* Report and error */
}
/* At this point the samples contained in data_seq will be considered as received. If the DataReader restarts, the samples will not be received again */
❏For the read/take methods that do not require calling return_loan(), a sample 's1' with sequence number 's1_seq_num' and virtual GUID ‘vg1’ will be considered processed after the application reads or takes the sample 's1' or any other sample with the same virtual GUID and with a sequence number greater than 's1_seq_num'. For example:
retcode =
/* At this point the sample contained in data will be considered as received. All the samples with a sequence number smaller than the sequence number associated with data will also be considered as received. If the DataReader restarts these sample will not be received again */
Important: If you access the samples in the DataReader cache out of
12.4.1.1Bandwidth Utilization
To optimize network usage, if a DataReader configured with durable reader state is restarted and it discovers a DataWriter with a virtual GUID ‘vg’, the DataReader will ACK all the samples with a sequence number smaller than ‘sn’, where ‘sn’ is the first sequence number that has not been being processed by the application for ‘vg’.
Notice that the previous algorithm can significantly reduce the number of duplicates on the wire. However, it does not suppress them completely in the case of keyed DataReaders where the durable state is kept per (instance, virtual GUID). In this case, and assuming that the application has read samples out of order (e.g., by reading different instances), the ACK is sent for the
lowest sequence number processed across all instances and may cause samples already processed to flow on the network again. These redundant samples waste bandwidth, but they will be dropped by the DataReader and not be delivered to the application.
12.4.2Durable Reader State with Application Acknowledgment
This section assumes you are familiar with the concept of Application Acknowledgment as described in Section 6.3.12.
For each DataReader configured to be durable and that uses application acknowledgement (see Section 6.3.12), Connext will create one database table with the following naming convention:
RS<32 uuencoding of the reader virtual GUID>. This table will store the list of sequence number intervals that have been acknowledged for each virtual GUID. The size of the column that stores the sequence number intervals is limited to 32767 bytes. If this size is exceeded for a given virtual GUID, the operation that persists the DataReader state into the database will fail.
12.4.2.1Bandwidth Utilization
To optimize network usage, if a DataReader configured with durable reader state is restarted and it discovers a DataWriter with a virtual GUID ‘vg’, the DataReader will send an APP_ACK message with all the samples that were
Notice that this algorithm can significantly reduce the number of duplicates on the wire. However, it does not suppress them completely since the DataReader may send a NACK and receive some samples from the DataWriter before the DataWriter receives the APP_ACK message.
12.4.3Durable Reader State Use Case
The following use case describes the durable reader state functionality:
1.A DataReader receives two samples with sequence number 1 and 2 published by a DataWriter with virtual GUID 1. The application takes those samples.
1, 2 |
|
DataWriter |
|
1, 2 |
|
DataReader |
|
take 1, 2 |
|
|
|
(vg: 1) |
|
|
|
|
(vg: 1) |
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
2.After the application returns the loan on samples 1 and 2, the DataReader considers them as processed and it persists the state change.
|
DataWriter |
|
|
DataReader |
return loan 1, 2 |
||
|
(vg: 1) |
|
|
(vg: 1) |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
(dw vg: 1,last sn: 2)
3. The process running the DataReader is stopped.
4. The DataReader is restarted.
DataWriter |
|
DataReader |
(vg: 1) |
|
(vg: 1) |
|
|
|
(dw vg: 1,last sn: 2)
Because all the samples with sequence number smaller or equal than 2 were considered as received, the reader will not ask for these samples to the DataWriter.
12.4.4How To Configure a DataReader for Durable Reader State
To configure a DataReader with durable reader state, use the PROPERTY QosPolicy (DDS Extension) (Section 6.5.17) associated with DataReaders and DomainParticipants.
A property defined in the DomainParticipant will be applicable to all the DataReaders contained in the participant unless it is overwritten by the DataReaders. Table 12.2 lists the supported properties.
Table 12.2 Durable Reader State Properties
Property |
Description |
|
|
|
|
|
Required. |
|
dds.data_reader.state.odbc.dsn |
The ODBC DSN (Data Source Name) associated with the database where |
|
|
the DataReader state must be persisted. |
|
|
|
|
|
To enable durable reader state, this property must be set to 1. |
|
dds.data_reader.state. |
When set to 0, the reader state is not maintained and Connext does not |
|
filter_redundant_samples |
filter duplicate samples that may be coming from the same virtual writer. |
|
|
Default: 1 |
|
|
|
|
|
This property indicates which ODBC driver to load. If the property is not |
|
dds.data_reader.state.odbc.driver |
specified, Connext will try to use the standard ODBC driver manager |
|
library (UnixOdbc on UNIX/Linux systems, the Windows ODBC driver |
||
|
||
|
manager on Windows systems). |
|
|
|
|
dds.data_reader.state.odbc.username |
These two properties configure the username and password used to |
|
|
connect to the database. |
|
dds.data_reader.state.odbc.password |
||
Default: No password or username |
||
|
|
|
|
This property indicates if the persisted DataReader state must be restored |
|
|
or not once the DataReader is restarted. |
|
dds.data_reader.state.restore |
If this property is 0, the previous state will be deleted from the database. |
|
If it is 1, the DataReader will restore its previous state from the database |
||
|
||
|
content. |
|
|
Default: 1 |
|
|
|
|
|
This property controls how often the reader state is stored into the |
|
|
database. A value of N means store the state once every N samples. |
|
dds.data_reader.state. |
A high frequency will provide better performance. However, if the |
|
reader is restarted it may receive some duplicate samples. These samples |
||
checkpoint_frequency |
||
will be filtered by Connext and they will not be propagated to the |
||
|
||
|
application. |
|
|
Default: 1 |
|
|
|
|
dds.data_reader.state.persistence_ |
This property indicates how many of the most recent historical samples |
|
the persisted DataReader wants to receive upon |
||
service.request_depth |
||
Default: 0 |
||
|
||
|
|

Example (C++ code):
/* Get default QoS */
...
retcode = DDSPropertyQosPolicyHelper::add_property( readerQos.property, "dds.data_reader.state.odbc.dsn", "<user DSN>",
DDS_BOOLEAN_FALSE); if (retcode != DDS_RETCODE_OK) {
/* Report error */
}
retcode = DDSPropertyQosPolicyHelper::add_property(readerQos.property, "dds.data_reader.state.odbc.driver", "<ODBC library>", DDS_BOOLEAN_FALSE);
if (retcode != DDS_RETCODE_OK) { /* Report error */
}
retcode = DDSPropertyQosPolicyHelper::add_property(readerQos.property, "dds.data_reader.state.restore", "<0|1>", DDS_BOOLEAN_FALSE);
if (retcode != DDS_RETCODE_OK) { /* Report error */
}
/* Create Data Reader */
...
12.5Data Durability
The data durability feature is an implementation of the OMG DDS Persistence Profile. The DURABILITY QosPolicy (Section 6.5.7) allows an application to configure a DataWriter so that the information written by the DataWriter survives beyond the lifetime of the DataWriter.
Connext implements TRANSIENT and PERSISTENT durability using an external service called Persistence Service, available for purchase as a separate RTI product.
Persistence Service receives information from DataWriters configured with TRANSIENT or PERSISTENT durability and makes that information available to
The samples published by a DataWriter can be made durable by setting the kind field of the DURABILITY QosPolicy (Section 6.5.7) to one of the following values:
❏DDS_TRANSIENT_DURABILITY_QOS: Connext will store previously published samples in memory using Persistence Service, which will send the stored data to newly discovered DataReaders.
❏DDS_PERSISTENT_DURABILITY_QOS: Connext will store previously published samples in permanent storage, like a disk, using Persistence Service, which will send the stored data to newly discovered DataReaders.
A DataReader can request TRANSIENT or PERSISTENT data by setting the kind field of the corresponding DURABILITY QosPolicy (Section 6.5.7). A DataReader requesting PERSISTENT data will not receive data from DataWriters or Persistence Service applications that are configured with TRANSIENT durability.
12.5.1RTI Persistence Service
Persistence Service is a Connext application that is configured to persist topic data. Persistence Service is included with Connext Messaging. For each one of the topics that must be persisted for a specific domain, the service will create a DataWriter (known as PRSTDataWriter) and a DataReader (known as PRSTDataReader). The samples received by the PRSTDataReaders will be published by the corresponding PRSTDataWriters to be available for
For more information on Persistence Service, please see:
❏Chapter 26: Introduction to RTI Persistence Service
❏Chapter 27: Configuring Persistence Service
❏Chapter 28: Running RTI Persistence Service
Persistence Service can be configured to operate in PERSISTENT or TRANSIENT mode:
❏TRANSIENT mode The PRSTDataReaders and PRSTDataWriters will be created with TRANSIENT durability and Persistence Service will keep the received samples in memory. Samples published by a TRANSIENT DataWriter will survive the DataWriter lifecycle but will not survive the lifecycle of Persistence Service (unless you are running multiple copies).
❏PERSISTENT mode The PRSTDataWriters and PRSTDataReaders will be created with PERSISTENT durability and Persistence Service will store the received samples in files or in an external relational database. Samples published by a PERSISTENT DataWriter will survive the DataWriter lifecycle as well as any restarts of Persistence Service.
By default, a PERSISTENT/TRANSIENT DataReader will receive samples directly from the original DataWriter if it is still alive. In this scenario, the DataReader may also receive the same samples from Persistence Service. Duplicates will be discarded at the middleware level. This Peer-
Figure 12.6
|
DataWriter |
|
|
|
|
|
(vg: 1, sn: 0) |
|
|
||
|
|
|
|
|
DataReader |
||||||
|
(vg: 1) |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
(vg: 1) |
||
|
|
|
(vg: 1, sn: 0) |
|
(vg: 1, sn: 0) |
|
|
||||
|
|
|
|
|
(vg: 1, sn: 0) |
|
|||||
|
|
|
|
|
|
|
|||||
|
|
|
(vg: 1, sn: 0) |
|
(vg: 1, sn: 0) |
||||||
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
RTI Persistence |
The application only |
|
receives one sample. |
||
Service |
||
|
Relay Communication:
A PERSISTENT/TRANSIENT DataReader may also be configured to not receive samples from the original DataWriter. In this case the traffic is relayed by Persistence Service. This ‘relay communication’ pattern is illustrated in Figure 12.7. To use relay communication, set the direct_communication field in the DURABILITY QosPolicy (Section 6.5.7) to FALSE. A PERSISTENT/TRANSIENT DataReader will receive all the information from Persistence Service.
Figure 12.7 Relay Communication
|
|
|
|
|
(vg: 1, sn: 0) |
|
|
||
|
|
|
|
|
|
|
|
DataReader |
|
|
DataWriter |
|
|
RTI Persistence |
|||||
|
|
|
|
|
|
(vg: 1) |
|||
|
(vg: 1) |
|
|
Service |
|
|
|
|
|
|
|
(vg: 1, sn: 0) |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(vg: 1, sn: 0) |
|

Chapter 13 Guaranteed Delivery of Data
13.1Introduction
Some application scenarios need to ensure that the information produced by certain producers is delivered to all the intended consumers. This chapter describes the mechanisms available in Connext to guarantee the delivery of information from producers to consumers such that the delivery is robust to many kinds of failures in the infrastructure, deployment, and even the producing/consuming applications themselves.
Guaranteed information delivery is not the same as
❏With
❏With information durability alone, there is no way to specify or characterize the intended consumers of the information. Therefore the infrastructure has no way to know when the information has been consumed by all the intended recipients. The information may be persisted such that it is not lost and is available to future applications, but the infrastructure and producing applications have no way to know that all the intended consumers have joined the system, received the information, and processed it successfully.
The guaranteed
❏Required subscriptions. This feature provides a way to configure, identify and detect the applications that are intended to consume the information. See Required Subscriptions (Section 6.3.13).
❏
❏Durable subscriptions. This feature leverages the RTI Persistence Service to persist samples intended for the required subscriptions such that they are delivered even if the originating application is not available. See Configuring Durable Subscriptions in Persistence Service (Section 27.9).
These features used in combination with the mechanisms provided for Information Durability and Persistence (see Chapter 12: Mechanisms for Achieving Information Durability and Persistence) enable the creation of applications where the information delivery is guaranteed despite application and infrastructure failures. Scenarios (Section 13.2) describes various
When implementing an application that needs guaranteed data delivery, we have to consider three key aspects:
Key Aspects to Consider |
|
Related Features and QoS |
|
|
|
|
|
|
• |
Required subscriptions |
|
Identifying the required consumers of information |
• |
Durable subscriptions |
|
• |
EntityName QoS policy |
||
|
|||
|
• |
Availability QoS policy |
|
|
|
||
|
• |
||
Ensuring the intended consumer applications |
• Acknowledgment by a quorum of required and |
||
|
durable subscriptions |
||
process the data successfully |
|
||
• Reliability QoS policy (acknowledgment mode) |
|||
|
|||
|
• |
Availability QoS policy |
|
|
|
|
|
|
• |
Persistence Service |
|
Ensuring information is available to late joining |
• |
Durable Subscriptions |
|
applications |
• |
Durability QoS |
|
|
• |
Durable Writer History |
|
|
|
|
|
13.1.1Identifying the Required Consumers of Information
The first step towards ensuring that information is processed by the intended consumers is the ability to specify and recognize those intended consumers. This is done using the required subscriptions feature (Required Subscriptions (Section 6.3.13)) configured via the ENTITY_NAME QosPolicy (DDS Extension) (Section 6.5.9) and AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1)).
Connext DDS DataReader entities (as well as DataWriter and DomainParticipant entities) can have a name and a role_name. These names are configured using the ENTITY_NAME QosPolicy (DDS Extension) (Section 6.5.9), which is propagated via DDS discovery and is available as part of the
The DDS DomainParticipant, DataReader and DataWriter entities created by
DataReaders created by RTI Persistence Service have their role_name set to “PERSISTENCE_SERVICE”.
Unless explicitly set by the user, the DomainParticipant, DataReader and DataWriter entities created by
Connext uses the role_name of DataReaders to identify the consumer’s logical function. For this reason Connext’s required subscriptions feature relies on the role_name to identify intended consumers of information. The use of the DataReader’s role_name instead of the name is intentional. From the point of view of the information producer, the important thing is not the
concrete DataReader (identified by its name, for example, “Logger123”) but rather its logical function in the system (identified by its role_name, for example “LoggingService”).
A DataWriter that needs to ensure its information is delivered to all the intended consumers uses the AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1) to configure the role names of the consumers that must receive the information.
The AVAILABILITY QoS Policy set on a DataWriter lets an application configure the required consumers of the data produced by the DataWriter. The required consumers are specified in the required_matched_endpoint_groups attribute within the AVAILABILITY QoS Policy. This attribute is a sequence of DDS EndpointGroup structures. Each EndpointGroup represents a required information consumer characterized by the consumer’s role_name and quorum. The role_name identifies a logical consumer; the quorum specifies the minimum number of consumers with that role_name that must acknowledge the sample before the DataWriter can consider it delivered to that required consumer.
For example, an application that wants to ensure data written by a DataWriter is delivered to at least two Logging Services and one Display Service would configure the DataWriter’s AVAILABILITY QoS Policy with a required_matched_endpoint_groups consisting of two elements. The first element would specify a required consumer with the role_name “LoggingService” and a quorum of 2. The second element would specify a required consumer with the role_name “DisplayService” and a quorum of 1. Furthermore, the application would set the logging service DataReader ENTITY_NAME policy to have a role_name of “LoggingService” and similarly the display service DataReader ENTITY_NAME policy to have the role_name of “DisplayService.”
A DataWriter that has been configured with an AVAILABILITY QoS policy will not remove samples from the DataWriter cache until they have been “delivered” to both the already- discovered DataReaders and the minimum number (quorum) of DataReaders specified for each role. In particular, samples will be retained by the DataWriter if the quorum of matched DataReaders with a particular role_name have not been discovered yet.
We used the word “delivered” in quotes above because the level of assurance a DataWriter has that a particular sample has been delivered depends on the setting of the RELIABILITY QosPolicy (Section 6.5.19). We discuss this next in Section 13.1.2.
13.1.2Ensuring Consumer Applications Process the Data Successfully
Section 13.1.1 described mechanisms by which an application could configure who the required consumers of information are. This section is about the criteria, mechanisms, and assurance provided by Connext to ensure consumers have the information delivered to them and process it in a successful manner.
RTI provides four levels of information delivery guarantee. You can set your desired level using the RELIABILITY QosPolicy (Section 6.5.19). The levels are:
❏
❏ Reliable with protocol acknowledgment The
cache. However, there is no guarantee the application actually processed the sample. The application might crash before processing the sample, or it might simply fail to read it from the cache.
❏ Reliable with Application Acknowledgment (Auto) Application Acknowledgment in Auto mode causes Connext to send an additional
❏ Reliable with Application Acknowledgment (Explicit) Application Acknowledgment in Explicit mode causes Connext to send an
13.1.3Ensuring Information is Available to
The third aspect of guaranteed data delivery addresses situations where the application needs to ensure that the information produced by a particular DataWriter is available to DataReaders that join the system after the data was produced. The need for data delivery may even extend beyond the lifetime of the producing application; that is, it may be required that the information is delivered to applications that join the system after the producing application has left the system.
Connext provides four mechanisms to handle these scenarios:
❏The DDS Durability QoS Policy. The DURABILITY QosPolicy (Section 6.5.7) specifies whether samples should be available to late joiners. The policy is set on the DataWriter and the DataReader and supports four kinds: VOLATILE, TRANSIENT_LOCAL, TRANSIENT, or PERSISTENT. If the DataWriter’s Durability QoS policy is set to VOLATILE kind, the DataWriter’s samples will not be made available to any late joiners. If the DataWriter’s policy kind is set to TRANSIENT_LOCAL, TRANSIENT, or PERSISTENT, the samples will be made available for
❏Durable Writer History. A DataWriter configured with a DURABILITY QoS policy kind other than VOLATILE keeps its data in a local cache so that it is available when the late- joining application appears. The data is maintained in the DataWriter’s cache until it is considered to be no longer needed. The precise criteria depends on the configuration of additional QoS policies such as LIFESPAN QoS Policy (Section 6.5.12), HISTORY QosPolicy (Section 6.5.10), RESOURCE_LIMITS QosPolicy (Section 6.5.20), etc. For the purposes of guaranteeing information delivery it is important to note that the

DataWriter’s cache can be configured to be a memory cache or a durable
❏RTI Persistence Service. This service allows the information produced by a DataWriter to survive beyond the lifetime of the producing application. Persistence Service is an stand- alone application that runs on many supported platforms. This service complies with the Persistent Profile of the OMG DDS specification. The service uses DDS to subscribe to the DataWriters that specify a DURABILITY QosPolicy (Section 6.5.7) kind of TRANSIENT or PERSISTENT. Persistence Service receives the data from those DataWriters, stores the data in its internal caches, and makes the data available via DataWriters (which are automatically created by Persistence Service) to
❏Durable Subscriptions. This is a Persistence Service configuration setting that allows configuration of the required subscriptions (Identifying the Required Consumers of Information (Section 13.1.1)) for the data stored by Persistence Service (Managing Data Instances (Working with Keyed Data Types) (Section 6.3.14)). Configuring required subscriptions for Persistence Service ensures that the service will store the samples until they have been delivered to the configured number (quorum) of DataReaders that have each of the specified roles.
13.2Scenarios
In each of the scenarios below, we assume both the DataWriter and DataReader are configured for strict reliability (RELIABLE ReliabilityQosPolicyKind and KEEP_ALL HistoryQosPolicyKind, see Section 10.3.3). As a result, when the DataWriter’s cache is full of unacknowledged samples, the write() operation will block until samples are acknowledged by all the intended consumers.
13.2.1Scenario 1: Guaranteed Delivery to
A common use case is to guarantee delivery to a set of known subscribers. These subscribers may be already running and have been discovered, they may be temporarily
To guarantee delivery, the list of required subscribers should be configured using the AVAILABILITY QosPolicy (DDS Extension) (Section 6.5.1) on the DataWriters to specify the role_name and quorum for each required subscription. Similarly the ENTITY_NAME QosPolicy (DDS Extension) (Section 6.5.9) should be used on the DataReaders to specify their role_name. In
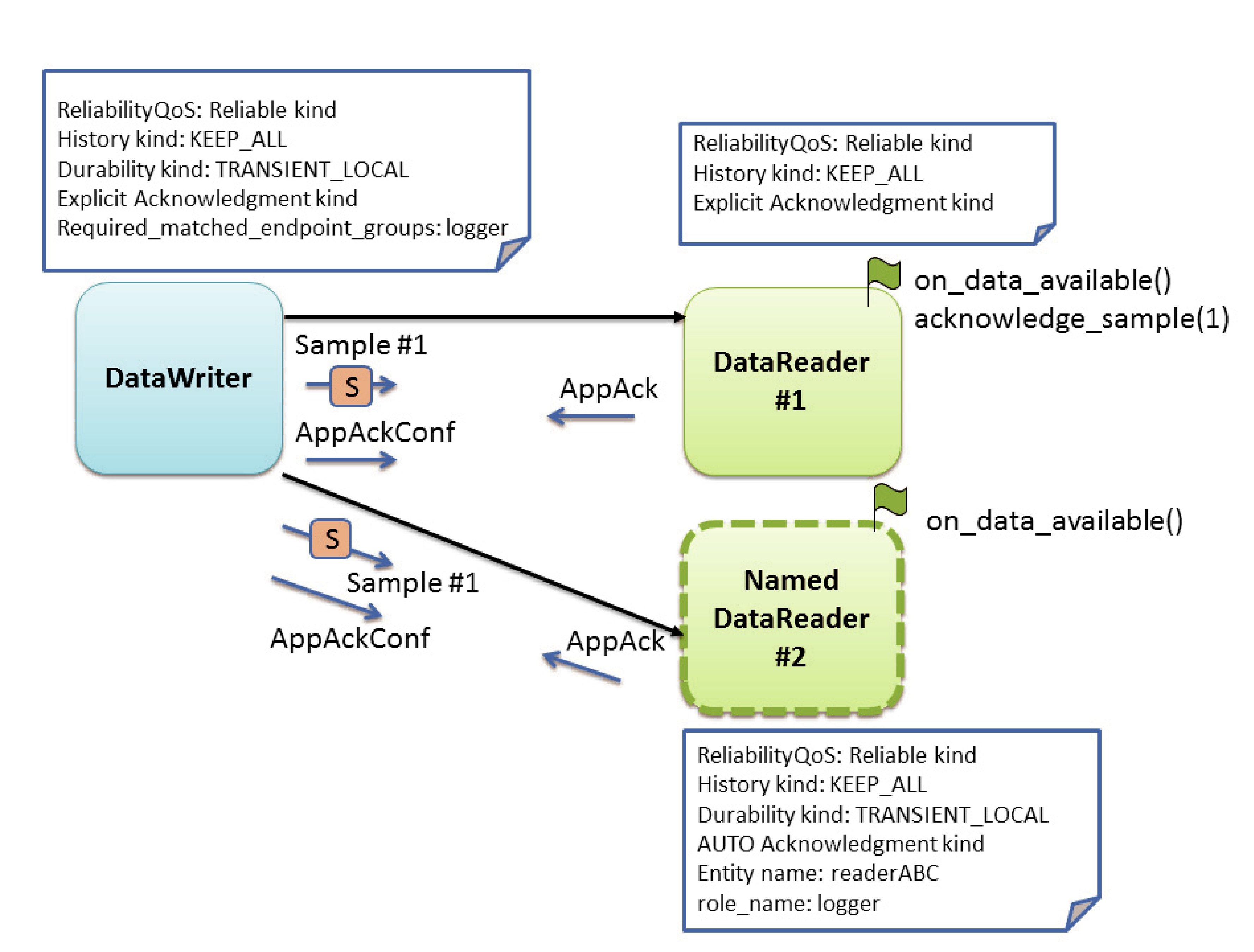
addition we use Application Acknowledgment (Section 6.3.12) to guarantee the sample was delivered and processed by the DataReader.
Figure 13.1 Guaranteed Delivery Scenario 1
The DataWriter and DataReader RELIABILITY QoS Policy can be configured for either AUTO or EXPLICIT application acknowledgment kind. As the DataWriter publishes the sample, it will await acknowledgment from the DataReader (through the
In this specific scenario, DataReader #1 is configured for EXPLICIT application acknowledgment. After reading and processing the sample, the subscribing application calls acknowledge_sample() or acknowledge_all() (see Section 7.4.4). As a result, Connext will send an
If the sample was lost in transit, the reliability protocol will repair the sample. Since it has not been acknowledged, it remains available in the writer’s queue to be automatically resent by Connext. The sample will remain available until acknowledged by the application. If the subscribing application crashes while processing the sample and restarts, Connext will repair the unacknowledged sample. Samples which already been processed and acknowledged will not be resent.
In this scenario, DataReader #2 may be a late joiner. When it starts up, because it is configured with TRANSIENT_LOCAL Durability, the reliability protocol will
DataWriter because they had not been confirmed yet by the required subscription (identified by its role_name: ‘logger’).
DataReader #2 does not explicitly acknowledge the samples it reads. It is configured to use AUTO application acknowledgment, which will automatically acknowledge samples that have been read or taken after the application calls the DataReader return_loan operation.
This configuration works well for situations where the DataReader may not be immediately available or may restart. However, this configuration does not provide any guarantee if the DataWriter restarts. When the DataWriter restarts, samples previously unacknowledged are lost and will no longer be available to any late joining DataReaders.
13.2.2Scenario 2: Surviving a Writer Restart when Delivering Samples to a priori Known Subscribers
Scenario 1 describes a use case where samples are delivered to a list of a priori known subscribers. In that scenario, Connext will deliver samples to the
To handle a situation where the producing application is restarted, we will use the Durable Writer History (Section 12.3) feature. See Figure 13.2 on page
A DataWriter can be configured to maintain its data and state in durable storage. This configuration is done using the PROPERTY QoS policy as described in Section 12.3.2.. With this configuration the data samples written by the DataWriter and any necessary internal state is persisted by the DataWriter into durable storage As a result, when the DataWriter restarts, samples which had not been acknowledged by the set of required subscriptions will be resent and
13.2.3Scenario 3: Delivery Guaranteed by Persistence Service (Store and Forward) to a priori Known Subscribers
Previous scenarios illustrated that using the DURABILITY, RELIABILITY, and AVAILABILITY QoS policies we can ensure that as long as the DataWriter is present in the system, samples written by a DataWriter will be delivered to the intended consumers. The use of the durable writer history in the previous scenario extended this guarantee even in the presence of a restart of the application writing the data.
This scenario addresses the situation where the originating application that produced the data is no longer available. For example, the network could have become partitioned, the application could have been terminated, it could have crashed and not have been restarted, etc.
In order to deliver data to applications that appear after the producing application is no longer available on the network it is necessary to have another service that stores those samples and delivers them. This is the purpose of the RTI Persistence Service.
The RTI Persistence Service can be configured to automatically discover DataWriters that specify a DURABILITY QoS with kind TRANSIENT or PERSISTENT and automatically create pairs (DataReader, DataWriter) that receive and store that information (see Chapter 26: Introduction to RTI Persistence Service). All the DataReaders created by the RTI Persistence Service have the ENTITY_QOS policy set with the role_name of “PERSISTENCE_SERVICE”. This allows an application to specify Persistence Service as one of the required subscriptions for its DataWriters.
In this third scenario, we take advantage of this capability to configure the DataWriter to have the RTI Persistence Service as a required subscription. See Figure 13.3 on page
The RTI Persistence Service can also have its DataWriters configured with required subscriptions. This feature is known as Persistence Service “durable subscriptions”. DataReader #1 is pre configured in Persistence Service as a Durable Subscription. (Alternatively, DataReader #1 could
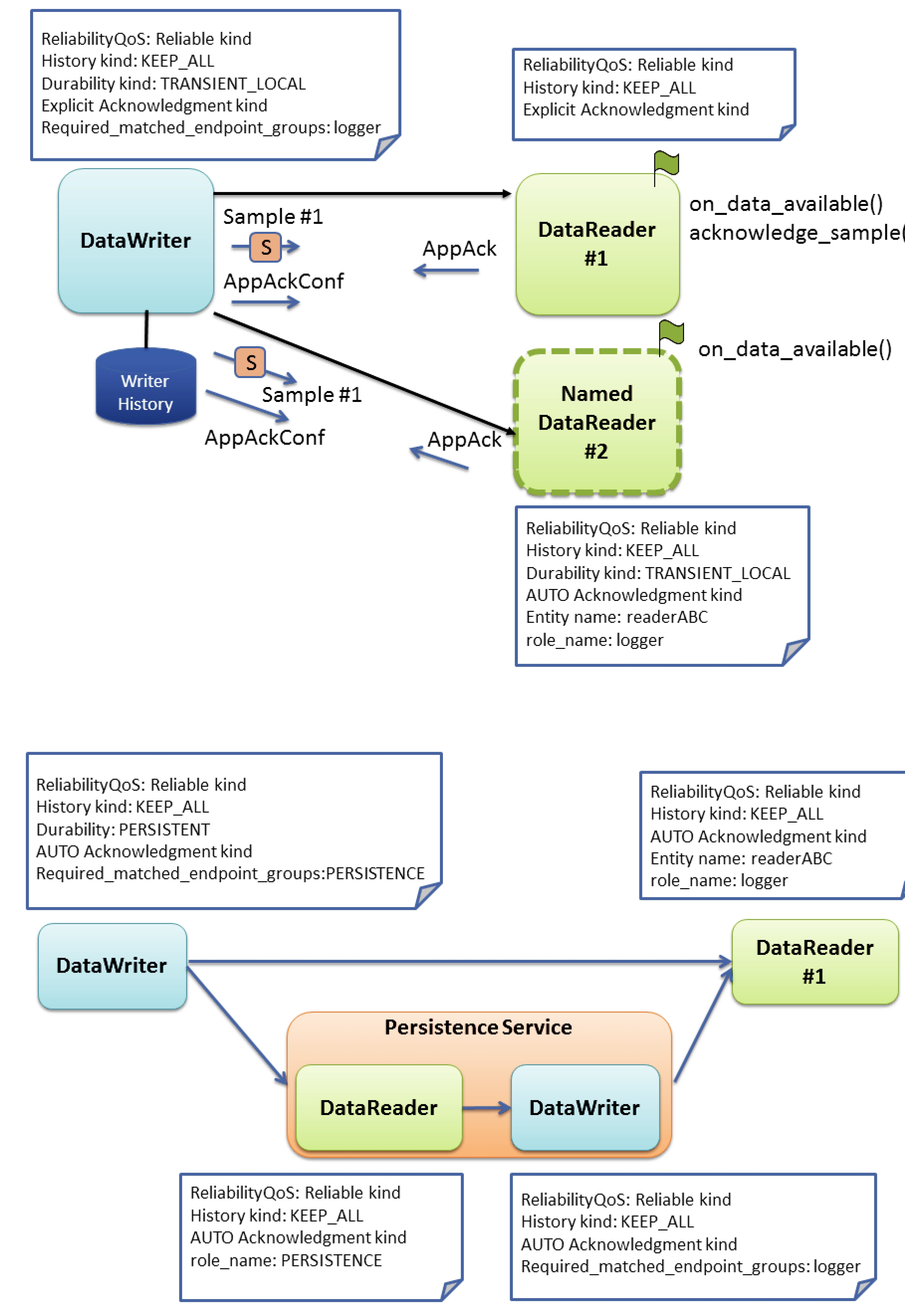
Figure 13.2 Guaranteed Delivery Scenario 2
Figure 13.3 Guaranteed Delivery Scenario 3
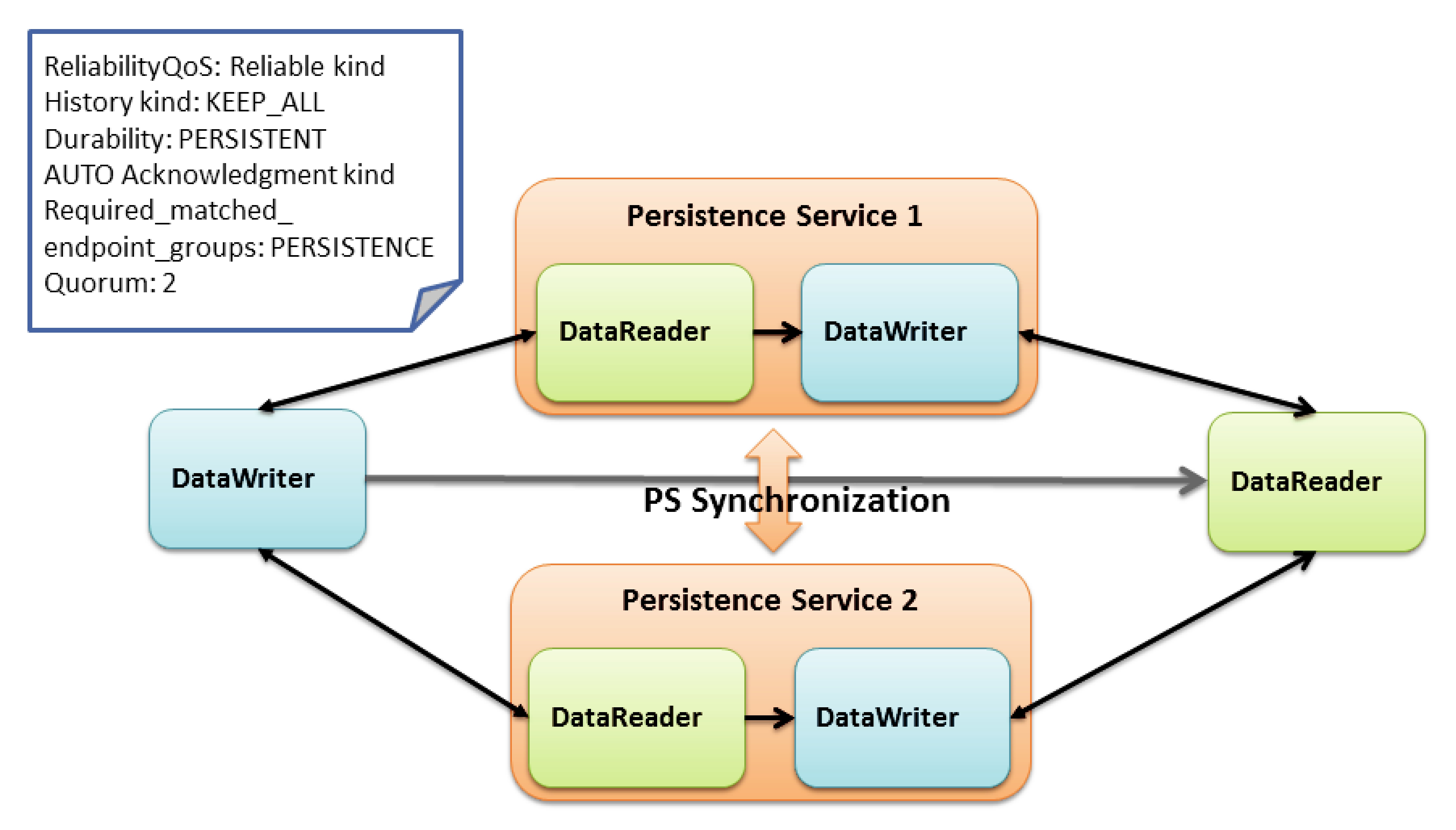
have registered itself dynamically as Durable Subscription using the DomainParticipant register_durable_subscription() operation).
We also configure the RELIBILITY QoS policy setting of the AcknowledgmentKind to APPLICATION_AUTO_ACKNOWLEDGMENT_MODE in order to ensure samples are stored in the Persistence Service and properly processed on the consuming application prior to them being removed from the DataWriter cache.
With this configuration in place the DataWriter will deliver samples to the DataReader and to the Persistence Service reliably and wait for the Application Acknowledgment from both. Delivery of samples to DataReader #1 and the Persistence Service occurs concurrently. The Persistence Service in turn takes responsibility to deliver the samples to the configured “logger” durable subscription. If the original publisher is no longer available, samples can still be delivered by the Persistence Service. to DataReader #1 and any other
When DataReader #1 acknowledges the sample through an
13.2.3.1Variation: Using Redundant Persistence Services
Using a single Persistence Service to guarantee delivery can still raise concerns about having the Persistence Service as a single point of failure. To provide a level of added redundancy, the publisher may be configured to await acknowledgment from a quorum of multiple persistence services (role_name remains PERSISTENCE). Using this configuration we can achieve higher levels of redundancy
Figure 13.4 Guaranteed Delivery Scenario 3 with Redundant Persistence Service
The RTI Persistence Services will automatically share information to keep each other synchronized. This includes both the data and also the information on the durable subscriptions. That is, when a Persistence Service discovers a durable subscription, information about durable subscriptions is automatically replicated and synchronized among persistence services (CITE: New section to be written in Persistence Service Chapter).
13.2.3.2Variation: Using
The Persistence Service will store samples on behalf of many DataWriters and, depending on the configuration, it might write those samples to a database or to disk. For this reason the Persistence Service may become a bottleneck in systems with high durable sample throughput.
It is possible to run multiple instances of the Persistence Service in a manner where each is only responsible for the guaranteed delivery of certain subset of the durable data being published. These Persistence Service can also be run different computers and in this manner achieve much higher throughput. For example, depending on the hardware, using typical
The data to be persisted can be partitioned among the persistence services by specifying different Topics to be persisted by each Persistence Service. If a single Topic has more data that can be handled y a single Persistence Service it is also possible to specify a

Chapter 14 Discovery
This chapter discusses how Connext objects on different nodes find out about each other using the default Simple Discovery Protocol (SDP). It describes the sequence of messages that are passed between Connext on the sending and receiving sides.
This chapter includes the following sections:
❏What is Discovery? (Section 14.1)
❏Configuring the Peers List Used in Discovery (Section 14.2)
❏Discovery Implementation (Section 14.3)
❏Debugging Discovery (Section 14.4)
❏Ports Used for Discovery (Section 14.5)
The discovery process occurs automatically, so you do not have to implement any special code. We recommend that all users read What is Discovery? (Section 14.1) and Configuring the Peers List Used in Discovery (Section 14.2). The remaining sections contain advanced material for those who have a particular need to understand what is happening ‘under the hood.’ This information can help you debug a system in which objects are not communicating.
You may also be interested in reading Chapter 15: Transport Plugins , as well as learning about these QosPolicies:
❏TRANSPORT_SELECTION QosPolicy (DDS Extension) (Section 6.5.22)
❏TRANSPORT_BUILTIN QosPolicy (DDS Extension) (Section 8.5.7)
❏TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23)
❏TRANSPORT_MULTICAST QosPolicy (DDS Extension) (Section 7.6.5)
14.1What is Discovery?
Discovery is the
This chapter describes the default discovery mechanism known as the Simple Discovery Protocol, which includes two phases: Simple Participant Discovery (Section 14.1.1) and Simple
Endpoint Discovery (Section 14.1.2). (Discovery can also be performed using the Enterprise Discovery
The goal of these two phases is to build, for each DomainParticipant, a complete picture of all the entities that belong to the remote participants that are in its peers list. The peers list is the list of nodes with which a participant may communicate. It starts out the same as the initial_peers list that you configure in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2). If the accept_unknown_peers flag in that same QosPolicy is TRUE, then other nodes may also be added as they are discovered; if it is FALSE, then the peers list will match the initial_peers list, plus any peers added using the DomainParticipant’s add_peer() operation.
14.1.1Simple Participant Discovery
This phase of the Simple Discovery Protocol is performed by the Simple Participant Discovery Protocol (SPDP).
During the Participant Discovery phase, DomainParticipants learn about each other. The DomainParticipant’s details are communicated to all other DomainParticipants in the same domain by sending participant declaration messages, also known as participant DATA submessages. The details include the DomainParticipant’s unique identifying key (GUID or Globally Unique ID described below), transport locators (addresses and port numbers), and QoS. These messages are sent on a periodic basis using
Participant DATAs are sent periodically to maintain the liveliness of the DomainParticipant. They are also used to communicate changes in the DomainParticipant’s QoS. Only changes to QosPolicies that are part of the DomainParticipant’s
When a DomainParticipant is deleted, a participant DATA (delete) submessage with the
DomainParticipant's identifying GUID is sent.
The GUID is a unique reference to an entity. It is composed of a GUID prefix and an Entity ID. By default, the GUID prefix is calculated from the IP address and the process ID. (For more on how the GUID is calculated, see Controlling How the GUID is Set (rtps_auto_id_kind) (Section 8.5.9.4).) The IP address and process ID are stored in the DomainParticipant’s WIRE_PROTOCOL QosPolicy (DDS Extension) (Section 8.5.9). The entityID is set by Connext (you may be able to change it in a future version).
Once a pair of remote participants have discovered each other, they can move on to the Endpoint Discovery phase, which is how DataWriters and DataReaders find each other.
14.1.2Simple Endpoint Discovery
This phase of the Simple Discovery Protocol is performed by the Simple Endpoint Discovery Protocol (SEDP).
During the Endpoint Discovery phase, Connext matches DataWriters and DataReaders. Information (GUID, QoS, etc.) about your application’s DataReaders and DataWriters is exchanged by sending publication/subscription declarations in DATA messages that we will refer to as publication DATAs and subscription DATAs. The Endpoint Discovery phase uses reliable communication.
As described in Section 14.3, these declaration or DATA messages are exchanged until each DomainParticipant has a complete database of information about the participants in its peers list and their entities. Then the discovery process is complete and the system switches to a steady state. During steady state, participant DATAs are still sent periodically to maintain the liveliness status of participants. They may also be sent to communicate QoS changes or the deletion of a
DomainParticipant.

When a remote DataWriter/DataReader is discovered, Connext determines if the local application has a matching DataReader/DataWriter. A ‘match’ between the local and remote entities occurs only if the DataReader and DataWriter have the same Topic, same data type, and compatible QosPolicies (which includes having the same partition name string, see Section 6.4.5). Furthermore, if the DomainParticipant has been set up to ignore certain DataWriters/DataReaders, those entities will not be considered during the matching process. See Section 16.4.2 for more on ignoring specific publications and subscriptions.
This ‘matching’ process occurs as soon as a remote entity is discovered, even if the entire database is not yet complete: that is, the application may still be discovering other remote entities.
A DataReader and DataWriter can only communicate with each other if each one’s application has hooked up its local entity with the matching remote entity. That is, both sides must agree to the connection.
Section 14.3 describes the details about the discovery process.
14.2Configuring the Peers List Used in Discovery
The Connext discovery process will try to contact all possible participants on each remote node in the ‘initial peers list,’ which comes from the initial_peers field of the DomainParticipant’s DISCOVERY QosPolicy.
The ‘initial peers list’ is just that: an initial list of peers to contact. Furthermore, the peers list merely contains potential
After startup, you can add to the ‘peers list’ with the add_peer() operation (see Adding and Removing Peers List Entries (Section 8.5.2.3)). The ‘peer list’ may also grow as peers are automatically discovered (if accept_unknown_peers is TRUE, see Controlling Acceptance of Unknown Peers (Section 8.5.2.6)).
When you call get_default_participant_qos() for a DomainParticipantFactory, the values used for the DiscoveryQosPolicy’s initial_peers and multicast_receive_addresses may come from the following:
❏A file named NDDS_DISCOVERY_PEERS, which is formatted as described in NDDS_DISCOVERY_PEERS File Format (Section 14.2.3). The file must be in the same directory as your application’s executable.
❏An environment variable named NDDS_DISCOVERY_PEERS, defined as a comma- separated list of peer descriptors (see NDDS_DISCOVERY_PEERS Environment Variable Format (Section 14.2.2)).
❏The value specified in the default XML QoS profile (see Overwriting Default QoS Values (Section 17.9.4)).
If NDDS_DISCOVERY_PEERS (file or environment variable) does not contain a multicast address, then multicast_receive_addresses is cleared and the RTI discovery process will not listen for discovery messages via multicast.
If NDDS_DISCOVERY_PEERS (file or environment variable) contains one or more multicast addresses, the addresses are stored in multicast_receive_addresses, starting at element 0. They will be stored in the order in which they appear in NDDS_DISCOVERY_PEERS.
Note: Setting initial_peers in the default XML QoS Profile does not modify the value of multicast_receive_address.
If both the file and environment variable are found, the file takes precedence and the environment variable will be ignored.1 The settings in the default XML QoS Profile take

precedence over the file and environment variable. In the absence of a file, environment variable, or default XML QoS profile values, Connext will use a default value. See the API Reference HTML documentation for details (in the section on the DISCOVERY QosPolicy).
If initial peers are specified in both the currently loaded QoS XML profile and in the NDDS_DISCOVERY_PEERS file, the values in the profile take precedence.
The file, environment variable, and default XML QoS Profile make it easy to reconfigure which nodes will take part in the discovery
The file, environment variable, and default XML QoS Profile are the possible sources for the default initial peers list. You can, of course, explicitly set the initial list by changing the values in the QoS provided to the DomainParticipantFactory's create_participant() operation, or by adding to the list after startup with the DomainParticipant’s add_peer() operation (see Section 8.5.2.3).
If you set NDDS_DISCOVERY_PEERS and You Want to Communicate over Shared Memory:
Suppose you want to communicate with other Connext applications on the same host and you are explicitly setting NDDS_DISCOVERY_PEERS (generally in order to use unicast discovery with applications on other hosts).
If the local host platform does not support the shared memory transport, then you can include the name of the local host in the NDDS_DISCOVERY_PEERS list. (To check if your platform supports shared memory, see the Platform Notes document.)
If the local host platform supports the shared memory transport, then you must do one of the following:
❏Include "shmem://" in the NDDS_DISCOVERY_PEERS list. This will cause shared memory to be used for discovery and data traffic for applications on the same host.
or:
❏Include the name of the local host in the NDDS_DISCOVERY_PEERS list, and disable the shared memory transport in the TRANSPORT_BUILTIN QosPolicy (DDS Extension) (Section 8.5.7) of the DomainParticipant. This will cause UDP loopback to be used for discovery and data traffic for applications on the same host.
14.2.1Peer Descriptor Format
A peer descriptor string specifies a range of participants at a given locator. Peer descriptor strings are used in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2) initial_peers field (see Section 8.5.2.2) and the DomainParticipant’s add_peer() and remove_peer() operations (see Section 8.5.2.3).
The anatomy of a peer descriptor is illustrated in Figure 14.1 using a special "StarFabric" transport example.
A peer descriptor consists of:
❏[optional] A participant ID. If a simple integer is specified, it indicates the maximum participant ID to be contacted by the Connext discovery mechanism at the given locator. If that integer is enclosed in square brackets (e.g., [2]), then only that Participant ID will be used. You can also specify a range in the form of [a,b]: in this case only the Participant IDs in that specific range are contacted. If omitted, a default value of 4 is implied.
❏A locator, as described in Section 14.2.1.1.
These are separated by the '@' character. The separator may be omitted if a participant ID limit is not explicitly specified.
1. This is true even if the file is empty.
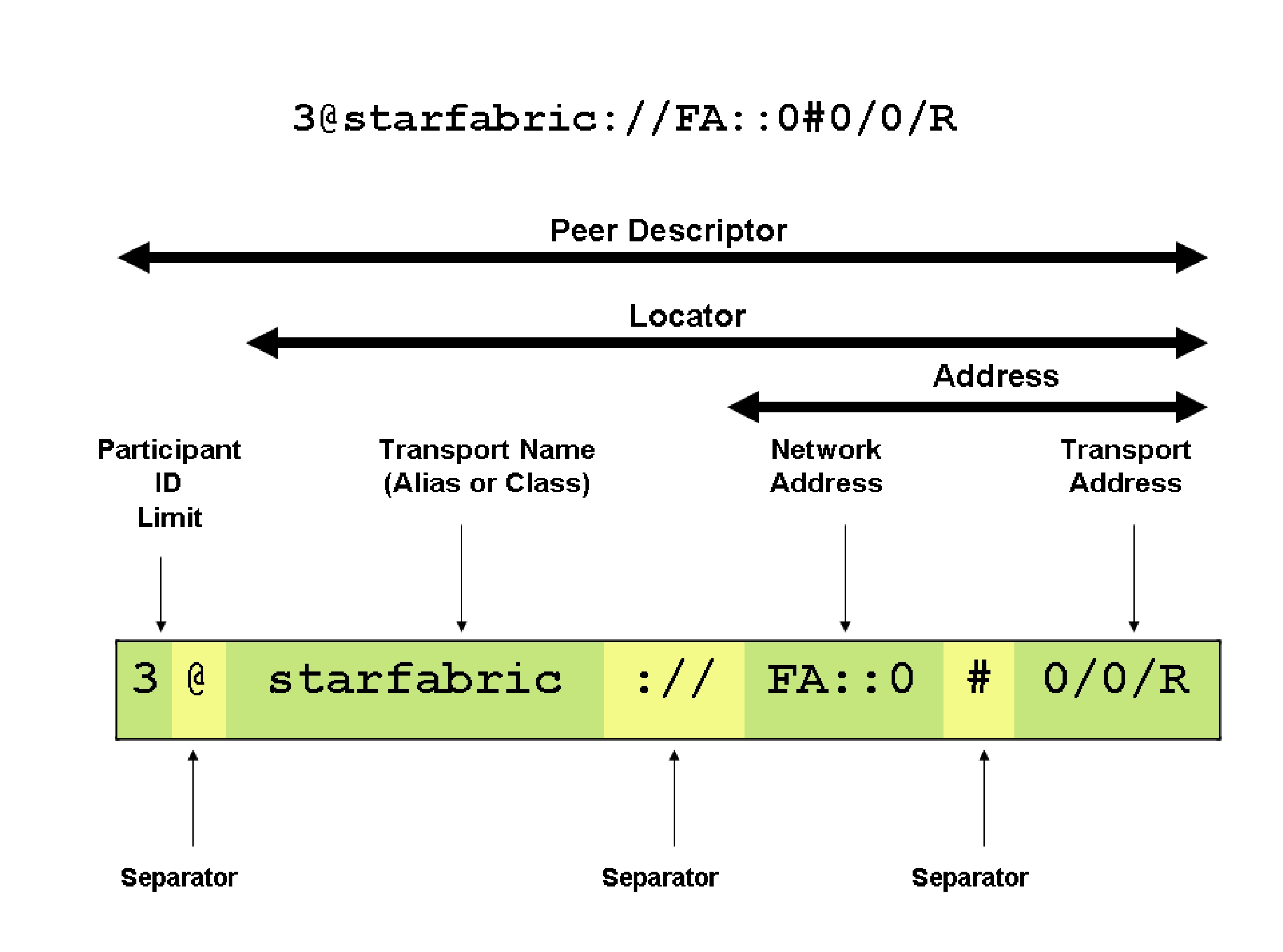
Figure 14.1 Peer Descriptor Address String
The "participant ID limit" only applies to unicast locators; it is ignored for multicast locators (and therefore should be omitted for multicast peer descriptors).
14.2.1.1Locator Format
A locator string specifies a transport and an address in string format. Locators are used to form peer descriptors. A locator is equivalent to a peer descriptor with the default participant ID limit
(4).
A locator consists of:
❏[optional] Transport name (alias or class). This identifies the set of transport
❏[optional] An address, as described in Section 14.2.1.2.
These are separated by the "://" string. The separator is specified if and only if a transport name is specified.
If a transport name is specified, the address may be omitted; in that case all the unicast addresses (across all transport
If an address is specified, the transport name and the separator string may be omitted; in that case all the available transport
The transport names for the
❏shmem - Shared Memory Transport
❏udpv4 - UDPv4 Transport
❏udpv6 - UDPv6 Transport
14.2.1.2Address Format
An address string specifies a
DDS_TransportMulticastSettings_t::receive_address fields. An address is equivalent to a locator in which the transport name and separator are omitted.
An address consists of:
❏[optional] A network address in IPv4 or IPv6 string notation. If omitted, the network address of the transport is implied.
❏[optional] A transport address, which is a string that is passed to the transport for processing. The transport maps this string into
NDDS_Transport_Property_t::address_bit_count bits. If omitted, the network address is used as the fully qualified address.
These are separated by the '#' character. If a separator is specified, it must be followed by a non- empty string which is passed to the transport
The bits resulting from the transport address string are prepended with the network address. The least significant NDDS_Transport_Property_t::address_bit_count bits of the network address are ignored.
If you omit the ‘#’ separator and the string is not a valid IPv4 or IPv6 address, it is treated as a transport address with an implicit network address (of the transport
14.2.2NDDS_DISCOVERY_PEERS Environment Variable Format
You can set the default value for the initial peers list in an environment variable named NDDS_DISCOVERY_PEERS. Multiple peer descriptor entries must be separated by commas. Table 14.1 shows some examples. The examples use an implied maximum participant ID of 4 unless otherwise noted. (If you need instructions on how to set environment variables, see the Getting Started Guide).
Table 14.1 NDDS_DISCOVERY_PEERS Environment Variable Examples
NDDS_DISCOVERY_PEERS |
Description of Host(s) |
|
|
|
|
|
|
|
239.255.0.1 |
multicast |
|
|
|
|
localhost |
localhost |
|
|
|
|
192.168.1.1 |
10.10.30.232 (IPv4) |
|
|
|
|
FAA0::1 |
FAA0::0 (IPv6) |
|
|
|
|
himalaya,gangotri |
himalaya and gangotri |
|
|
|
|
1@himalaya,1@gangotri |
himalaya and gangotri (with a maximum participant ID of 1 on each |
|
host) |
||
|
||
|
|
|
FAA0::0localhost |
FAA0::0localhost (could be a UDPv4 transport |
|
network address of FAA0::0) (IPv6) |
||
|
||
|
|
|
udpv4://himalaya |
himalaya accessed using the "udpv4" transport |
|
|
|
|
udpv4://FAA0::0localhost |
localhost using the "udpv4" transport |
|
address FAA0::0 |
||
|
||
|
|
|
udpv4:// |
all unicast addresses accessed via the "udpv4" (UDPv4) transport |
|
|
||
|
|
|
0/0/R |
0/0/R (StarFabric) |
|
#0/0/R |
||
|
||
|
|
|
starfabric://0/0/R |
0/0/R (StarFabric) using the "starfabric" (StarFabric) transport plug- |
|
starfabric://#0/0/R |
ins |
|
|
|
Table 14.1 NDDS_DISCOVERY_PEERS Environment Variable Examples
NDDS_DISCOVERY_PEERS |
Description of Host(s) |
|
|
|
|
|
|
|
starfabric://FBB0::0#0/0/R |
0/0/R (StarFabric) using the "starfabric" (StarFabric) transport plug- |
|
ins registered at network address FAA0::0 |
||
|
|
|
starfabric:// |
all unicast addresses accessed via the "starfabric" (StarFabric) |
|
transport |
||
|
||
|
|
|
shmem:// |
all unicast addresses accessed via the "shmem" (shared memory) |
|
transport |
||
|
||
|
|
|
shmem://FCC0::0 |
all unicast addresses accessed via the "shmem" (shared memory) |
|
transport |
||
|
||
|
|
14.2.3NDDS_DISCOVERY_PEERS File Format
You can set the default value for the initial peers list in a file named NDDS_DISCOVERY_PEERS. The file must be in the your application’s current working directory.
The file is optional. If it is found, it supersedes the values in any environment variable of the same name.
Entries in the file must contain a sequence of peer descriptors separated by whitespace or the comma (',') character. The file may also contain comments starting with a semicolon (';') character until the end of the line.
Example file contents:
;;NDDS_DISCOVERY_PEERS - Default Discovery Configuration File
;;Multicast builtin.udpv4://239.255.0.1 ; default discovery multicast addr
;;Unicast
localhost,192.168.1.1 |
; A comma can be used a separator |
FAA0::1 FAA0::0#localhost ; Whitespace can be used as a separator |
|
1@himalaya |
; Max participant ID of 1 on 'himalaya' |
1@gangotri |
|
;; UDPv4 |
|
udpv4://himalaya |
; 'himalaya' via 'udpv4' transport plugin(s) |
udpv4://FAA0::0#localhost ; 'localhost' via 'updv4' transport plugin
|
; |
registered at network address FAA0::0 |
;; Shared Memory |
|
|
shmem:// |
; All 'shmem' transport plugin(s) |
|
builtin.shmem:// |
; The builtin builtin 'shmem' transport plugin |
|
shmem://FCC0::0 |
; Shared memory transport plugin registered |
|
|
; |
at network address FCC0::0 |
;; StarFabric |
|
|
0/0/R |
; StarFabric node 0/0/R |
|
starfabric://0/0/R |
; 0/0/R accessed via 'starfabric' |
|
|
; |
transport plugin(s) |
starfabric://FBB0::0#0/0/R ; StarFabric transport plugin registered |
||
|
; |
at network address FBB0::0 |
starfabric:// |
; All 'starfabric' transport plugin(s) |
|

14.3Discovery Implementation
Note: this section contains advanced material not required by most users.
Discovery is implemented using
DDSDataWriter/DDSDataReader. For each DomainParticipant, three
Figure 14.2
DomainParticipant
|
|
|
|
|
participant DATA |
||
|
Advertises this |
Builtin |
|
|
|||
|
|
|
|
|
|
||
Participant |
participant |
DataWriter |
|
“DCPSParticipant” builtin topic |
|||
Discovery |
|
|
|
|
|
|
|
Phase |
Discovers other |
Builtin |
|
|
participant DATA |
||
|
DataReader |
|
|
|
|
|
|
|
participants |
|
“DCPSParticipant” builtin topic |
||||
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
publication DATA |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Builtin |
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
Advertises this |
|
|
|
|
DataWriter |
|
“DCPSPublication” builtin topic |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
participant’s |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
DataWriters and |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
subscription DATA |
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
DataReaders |
|
|
|
|
|
Builtin |
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DataWriter |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Endpoint |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
“DCPSSubscription” builtin topic |
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
(Writer/ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
Reader) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
Discovery |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
publication DATA |
||||||||||||||||||||||||||||||||||
|
|
|
Builtin |
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||
|
|
Phase |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
Discovers other |
|
|
|
|
DataReader |
|
“DCPSPublication” builtin topic |
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
participants’ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
DataWriters and |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
DataReaders |
|
|
|
|
|
Builtin |
|
|
|
|
|
subscription DATA |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DataReader |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
“DCPSSubscription” builtin topic |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
Network
For each DomainParticipant, there are six objects automatically created for discovery purposes. The top two objects are used to send/receive participant DATA messages, which are used in the Participant Discovery phase to find remote DomainParticipants. This phase uses
The implementation is split into two separate protocols:
Simple Participant Discovery Protocol (SPDP)
+Simple Endpoint Discovery Protocol (SEDP)
=Simple Discovery Protocol (SDP)
14.3.1Participant Discovery
When a DomainParticipant is created, a DataWriter and a DataReader are automatically created to exchange participant DATA messages in the network. These DataWriters and DataReaders are "special" because the DataWriter can send to a given list of destinations, regardless of whether there is a Connext application at the destination, and the DataReader can receive data from any
source, whether the source is previously known or not. In other words, these special readers and writers do not need to discover the remote entity and perform a match before they can communicate with each other.
When a DomainParticipant joins or leaves the network, it needs to notify its peer participants. The list of remote participants to use during discovery comes from the peer list described in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2). The remote participants are notified via participant DATA messages. In addition, if a participant’s QoS is modified in such a way that other participants need to know about the change (that is, changes to the USER_DATA QosPolicy (Section 6.5.25)), a new participant DATA will be sent immediately.
Participant DATAs are also used to maintain a participant’s liveliness status. These are sent at the rate set in the participant_liveliness_assert_period in the DISCOVERY_CONFIG QosPolicy (DDS Extension) (Section 8.5.3).
Let’s examine what happens when a new remote participant is discovered. If the new remote participant is in the local participant's peer list, the local participant will add that remote participant into its database. If the new remote participant is not in the local application's peer list, it may still be added, if the accept_unknown_peers field in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2) is set to TRUE.
Once a remote participant has been added to the Connext database, Connext keeps track of that remote participant’s participant_liveliness_lease_duration. If a participant DATA for that participant (identified by the GUID) is not received at least once within the participant_liveliness_lease_duration, the remote participant is considered stale, and the remote participant, together with all its entities, will be removed from the database of the local participant.
To keep from being purged by other participants, each participant needs to periodically send a participant DATA to refresh its liveliness. The rate at which the participant DATA is sent is controlled by the participant_liveliness_assert_period in the participant’s DISCOVERY_CONFIG QosPolicy (DDS Extension) (Section 8.5.3). This exchange, which keeps Participant A from appearing ‘stale,’ is illustrated in Figure 14.3. Figure 14.4 shows what happens when Participant A terminates ungracefully and therefore needs to be seen as ‘stale.’
14.3.1.1Refresh Mechanism
To ensure that a
The number of retries and the random amount of sleep between them are controlled by each participant’s DISCOVERY_CONFIG QosPolicy (DDS Extension) (Section 8.5.3) (see ① and ✍ in Figure 14.5).
Figure 14.6 provides a summary of the messages sent during the participant discovery phase.
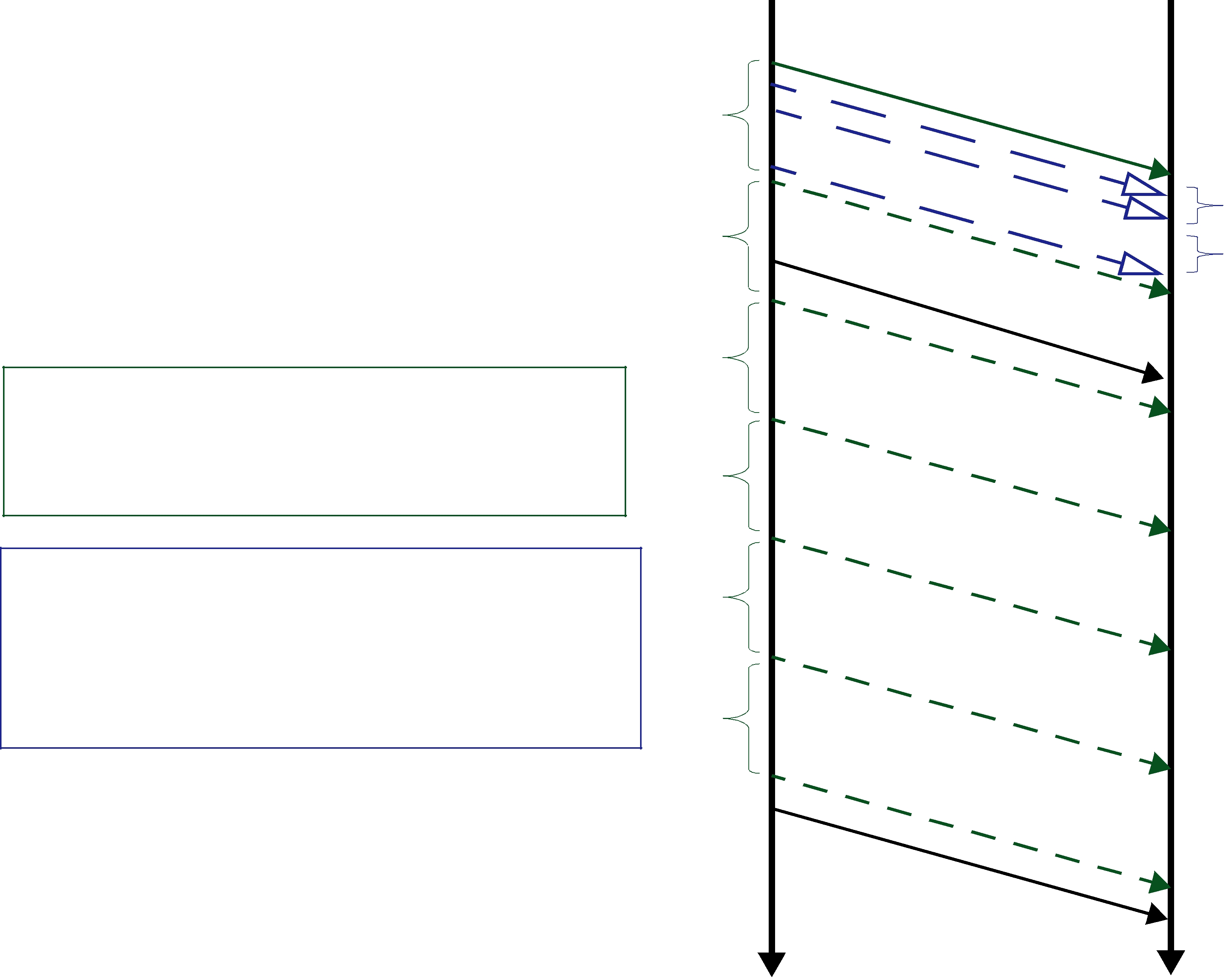
Figure 14.3 Periodic ‘participant DATAs’
Node A
Participant created
Participant’s UserDataQosPolicy  modified
modified 
① Participant A’s DDS_DomainParticipantQos.discovery_config.
participant_liveliness_assert_period
➁ Random time between min_initial_participant_announcement_period and
max_initial_participant_announcement_period (in A’s
DDS_DomainParticipantQos.discovery_config)
Participant destroyed
Node B
participant A DATA
participant A DATA (delete)
➁
➁
The DomainParticipant on Node A sends a ‘participant DATA’ to Node B, which is in Node A’s peers list. This occurs regardless of whether or not there is a Connext application on Node B.
The green short dashed lines are periodic participant DATAs. The time between these messages is controlled by the participant_liveliness_assert_period in the DiscoveryConfig QosPolicy.
➁ In addition to the periodic participant DATAs, ‘initial repeat messages’ (shown in blue, with longer dashes) are sent from A to B. These messages are sent at a random time between min_initial_participant_announcement_period and max_initial_participant_announcement_period (in A’s DiscoveryConfig QosPolicy). The number of these initial repeat messages is set in initial_participant_announcements.
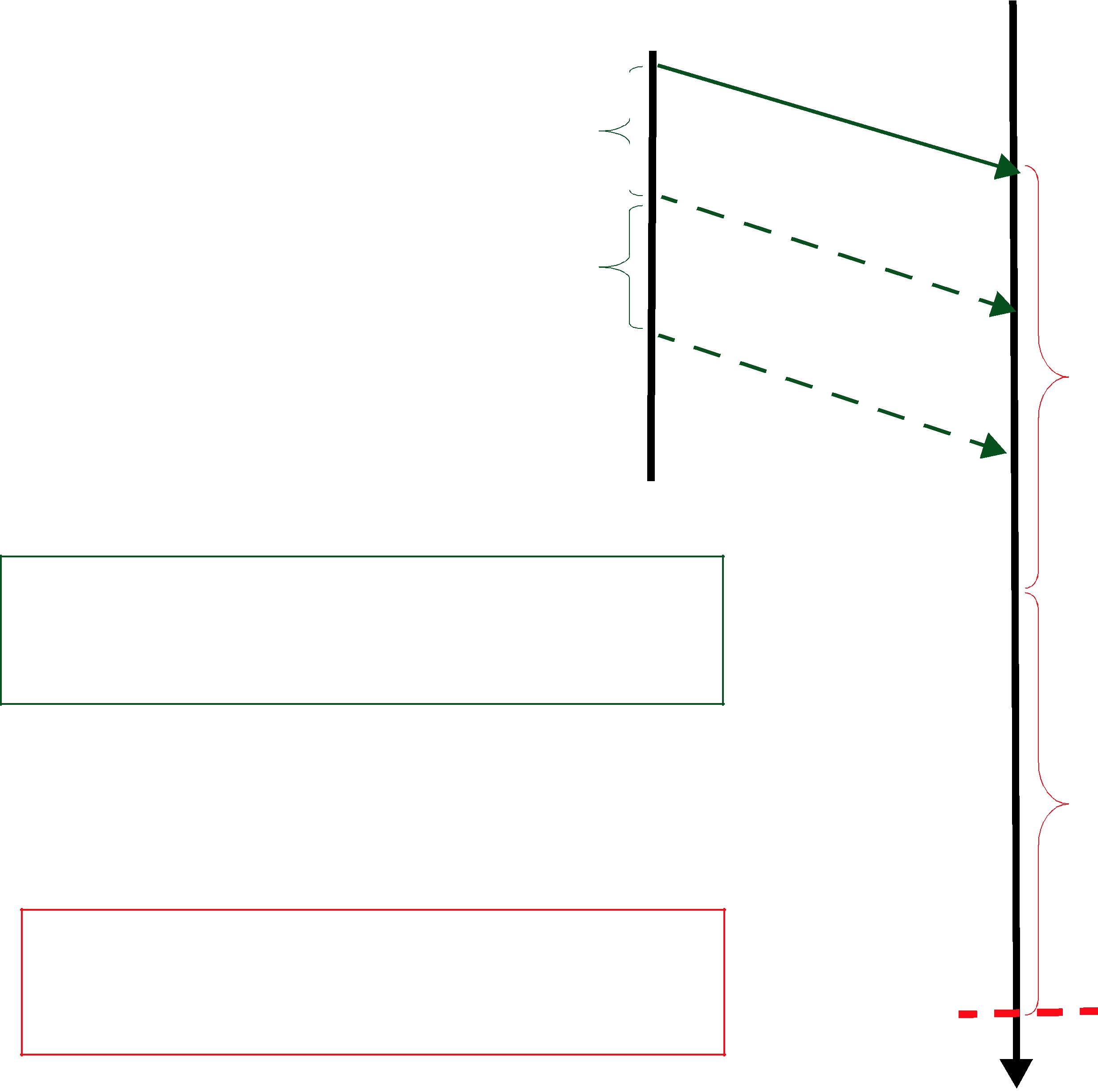
Figure 14.4 Ungraceful Termination of a Participant
Node A |
Node B |
||
|
|
Participant created |
|
Participant created |
participant A |
||
DATA |
|||
|
|
||
➀ |
|
New remote participant A |
|
|
|||
|
added to database |
||
|
|
|
|
➀
➁
Participant ungracefully terminated 
➀Participant A’s DDS_DomainParticipantQos.discovery_config. participant_liveliness_assert_period
➁Participant A’s DDS_DomainParticipantQos.discovery_config. participant_liveliness_lease_duration
➁
Remote participant A considered ‘stale,’ removed from database
Participant A is removed from participant B’s database if it is not refreshed within the liveliness lease duration. Dashed lines are periodic participant DATA messages.
(Periodic resends of ‘participant B DATA’ from B to A are omitted from this diagram for simplicity. Initial repeat messages from A to B are also omitted from this
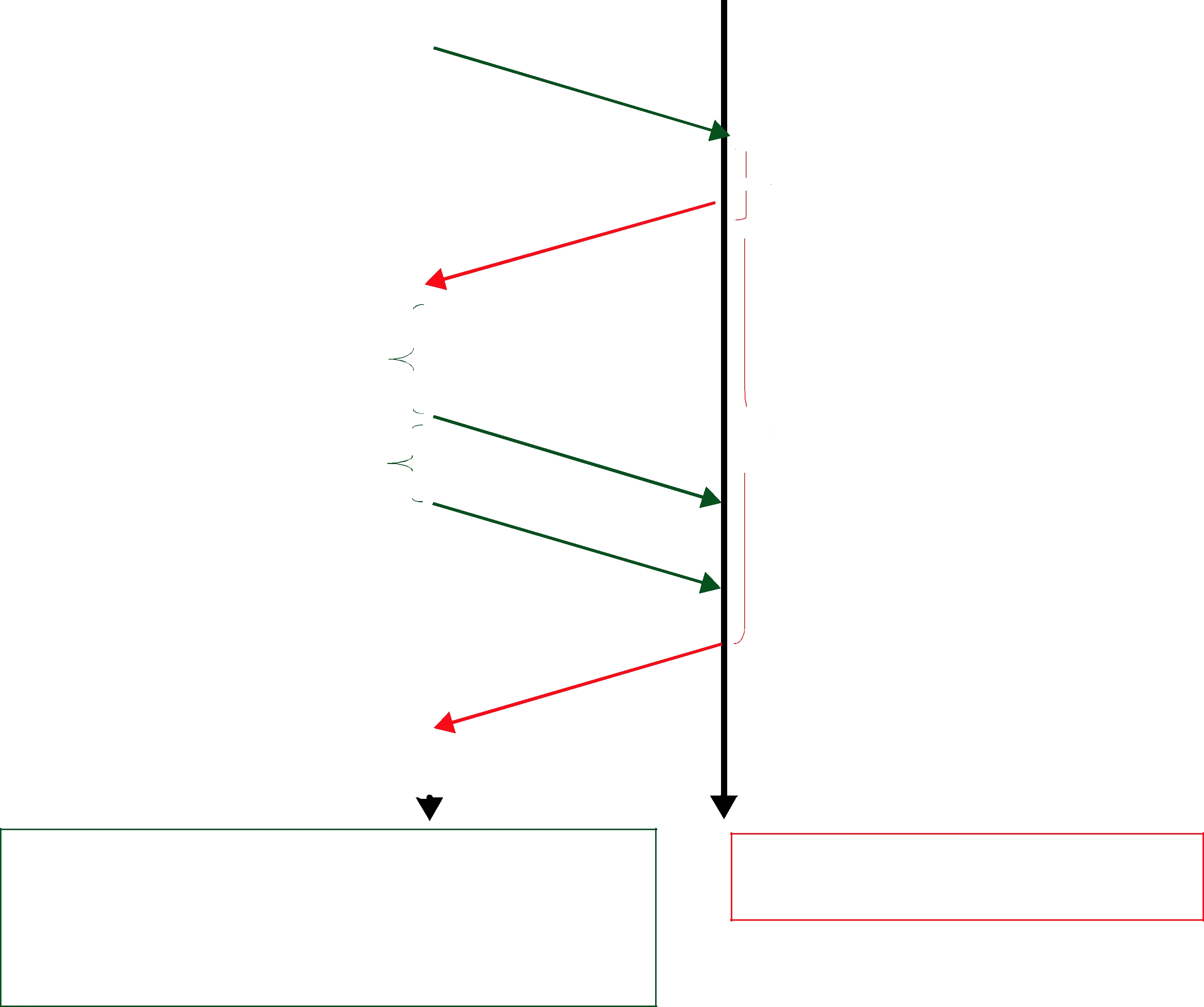
Figure 14.5 Resending ‘participant DATA’ to a
Node A |
Node B |
Participant created |
|
participant A |
|||
|
DATA |
||||
|
|||||
|
|
|
|
|
participant B |
|
|
|
|
|
DATA |
New remote participant B |
|
|
|||
added to database |
|
|
|
|
|
|
|
|
|||
➀ |
|
|
|
participant A |
|
|
|
||||
|
|
|
|
|
|
➀ |
|
|
|
|
DATA |
|
|
|
|
||
|
|
participant A |
|||
|
|
||||
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DATA |
participant B already in |
|
participant B |
|||
database, no action taken |
|
DATA |
|||
|
|
|
|
|
|
Participant created
New remote participant A  added to database
added to database

 ➁
➁
 Resend participant DATA to
Resend participant DATA to  all peers
all peers
 ➁
➁
participant A already in database, no action taken
➀wait random time (between min_initial_participant_announcement_period and max_initial_participant_announcement_period) for [initial_participant_announcements] = 2 (using values from A’s DiscoveryQosPolicy)
➁same as ➀, but using participant B’s QoS
Participant A has Participant B in its peers list. Participant B does not have Participant A in its peers list, but [DiscoveryQosPolicy.accept_unknown_peers] is set to DDS_BOOLEAN_TRUE. Participant A joins the system after B has sent its initial announcement. After B discovers A, it waits for time ➁, then resends its participant DATA.
(Initial repeat messages are omitted from this diagram for simplicity, see Figure 14.3.)
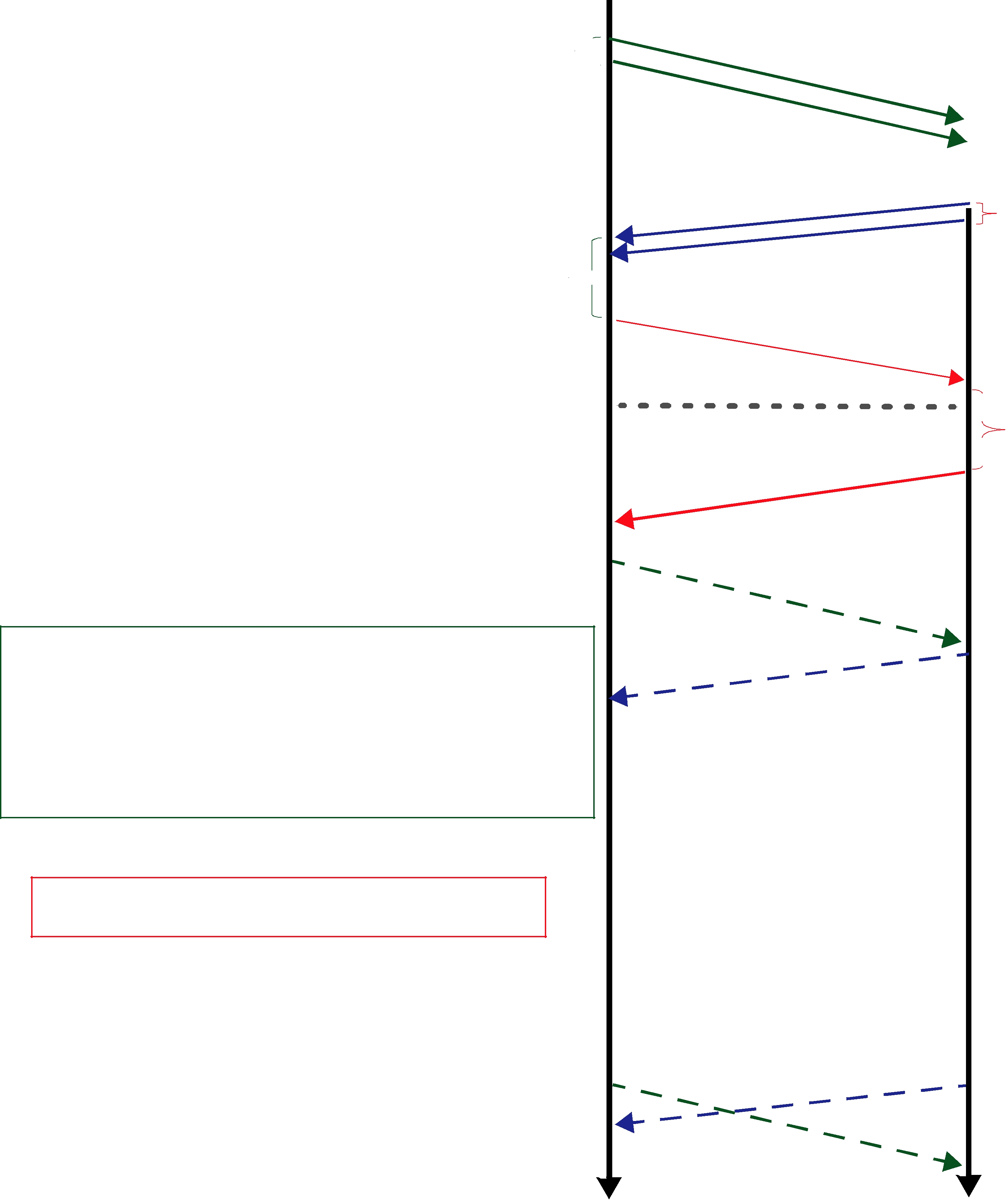
Figure 14.6 Participant Discovery Summary
Node A |
Node B |
Participant created
➀ 
|
|
p |
|
|
|
|
|
|
|
|
artic |
|
|
|
|
||
|
|
|
|
ip |
|
|
||
|
|
|
|
|
|
ant |
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
|
AT |
initial |
|
|
|
|
|
A |
||
|
|
r |
|
|
|
|
|
|
|
|
e |
|
|
|
|
|
|
p |
a |
rticip |
p |
e |
a |
t of |
|
|
a |
|
|
||||||
|
|
|
|
|||||
|
|
|
nt |
|
|
|
||
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
|
|
A |
|
Newly discovered participant B added to database
➀ 
|
|
|
|
|
A |
|
Participant created |
|
|
t B DAT |
|
||||
|
pan |
|
|
|
|
|
|
rtici |
|
|
|
|
|
|
|
pa |
|
|
|
|
|
|
➁ |
|
|
|
|
|
t of |
||
|
|
|
|
|
|
||
|
|
|
|
pea |
|
|
|
|
|
al re |
|
|
|
||
|
|
initi |
|
|
|
TA |
|
|
|
|
|
|
nt B |
DA |
|
|
|
|
pa |
|
|
||
|
|
rtici |
|
|
|
|
|
p |
|
pa |
|
|
|
|
|
|
|
|
|
|
|
|
|
artici |
|
|
|
|
|
||
|
|
pant A |
|
|
Newly discovered |
||
|
|
|
|
DA |
|
||
|
|
|
|
|
TA |
|
participant A added |
|
|
|
|
|
|
|
to database |
Participant B already in database, no action required
➀wait random time (between min_initial_participant_announcement_period and max_initial_participant_announcement_period) for [initial_participant_announcements] = 1 (using values from A’s DiscoveryQosPolicy)
Participants have discovered |
|
➁ |
||||||||
|
||||||||||
|
|
|
each other |
|
|
|
|
|
||
|
|
|
|
|
ATA |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
ant |
B D |
|
|
|
|
|
|
|
ticip |
|
|
|
|
|
|
||
par |
|
|
|
|
|
|
|
|
||
p |
|
|
|
|
|
|
|
|
|
|
er |
|
|
|
|
|
|
|
|
|
|
|
iodic |
|
|
|
|
|
|
|
||
|
|
|
pa |
|
|
|
|
|
|
|
|
|
|
|
rticip |
|
|
|
|
|
|
|
|
|
|
|
a |
|
|
|
|
|
|
|
|
|
|
nt |
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
TA |
|
|
|
|
|
|
|
|
nt B |
DA |
|
|
|
|
|
|
|
|
cipa |
|
|
|
|
|
|
|
|
|
arti |
|
|
|
|
|
|
|
|
ic p |
|
|
|
|
|
|
|
||
iod |
|
|
|
|
|
|
|
|
|
|
per |
|
|
|
|
|
|
|
|
|
|
➁same as ①, but using Participant B’s QoS
|
|
ic |
|
|
TA |
|
|
|
riod |
|
|
|
|
||
|
pe |
|
|
t B |
DA |
|
|
|
|
|
an |
|
|
|
|
|
|
ip |
|
|
|
|
|
|
rtic |
|
|
|
|
|
|
|
pa |
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
er |
|
|
|
|
|
|
|
iodic |
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
ar |
|
|
|
|
|
|
|
ti |
c |
|
|
|
|
|
|
|
ipant |
|
|
|
||
|
|
|
|
A |
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
A |
|
Participants A and B both have each other in their peers lists. Participant A is created first.
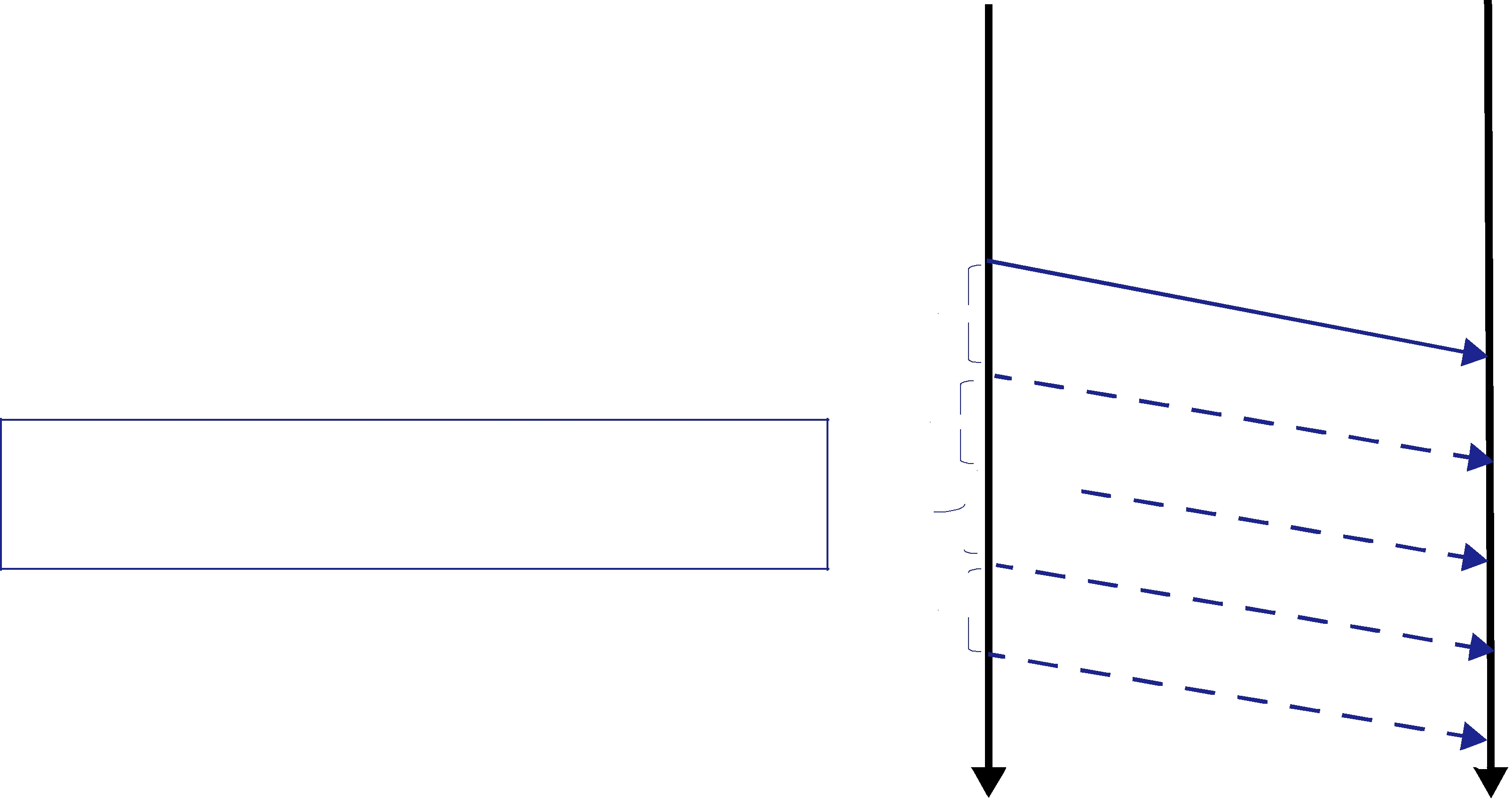
14.3.1.2Maintaining DataWriter Liveliness for kinds AUTOMATIC and MANUAL_BY_PARTICIPANT
To maintain the liveliness of DataWriters that have a LIVELINESS QosPolicy (Section 6.5.13) kind field set to AUTOMATIC or MANUAL_BY_PARTICIPANT, Connext uses a
DataWriter and DataReader pair, referred to as the
If the DomainParticipant has any DataWriters with Liveliness QosPolicy kind set to AUTOMATIC, the
Figure 14.7 DataWriter with AUTOMATIC Liveliness
Node A |
Node B |
Participant created
DataWriter C created with liveliness kind = AUTOMATIC
➀ 

➀ 

➀ DataWriter C’s 



 DDS_DataWriterQos.liveliness.lease_duration ➀
DDS_DataWriterQos.liveliness.lease_duration ➀ 
➀ 
|
A |
|
|
|
|
UT |
|
|
|
|
|
OM |
|
|
l |
|
A |
|
|
iv |
TI |
C |
|
|
|
elin |
|
|
|
|
|
ess |
|
|
|
|
mess |
|
|
|
|
|
a |
|
|
|
|
ge |
|
|
|
|
|
|
A liveliness message is sent automatically when a DataWriter with AUTOMATIC Liveliness kind is created, and then periodically, every DDS_DataWriterQos.liveliness.lease_duration.
If the DomainParticipant has any DataWriters with Liveliness QosPolicy kind set to MANUAL_BY_PARTICIPANT, Connext will periodically check to see if any of them have called write(), assert_liveliness(), dispose() or unregister(). The rate of this check is every X seconds, where X is the smallest lease_duration among all the DomainParticipant's
MANUAL_BY_PARTICIPANT DataWriters. (The lease_duration is a field in the LIVELINESS QosPolicy (Section 6.5.13).) If any of the MANUAL_BY_PARTICIPANT DataWriters have called any of those operations, the
If a DomainParticipant's assert_liveliness() operation is called, and that DomainParticipant has any MANUAL_BY_PARTICIPANT DataWriters, the
MANUAL_BY_PARTICIPANT DataWriters, as well as the liveliness of the DomainParticipant itself. Figure 14.8 shows an example sequence.
The
If the DomainParticipant has no DataWriters with LIVELINESS QosPolicy (Section 6.5.13) kind set to AUTOMATIC or MANUAL_BY_PARTICIPANT, then no liveliness messages are ever sent from the
14.3.2Endpoint Discovery
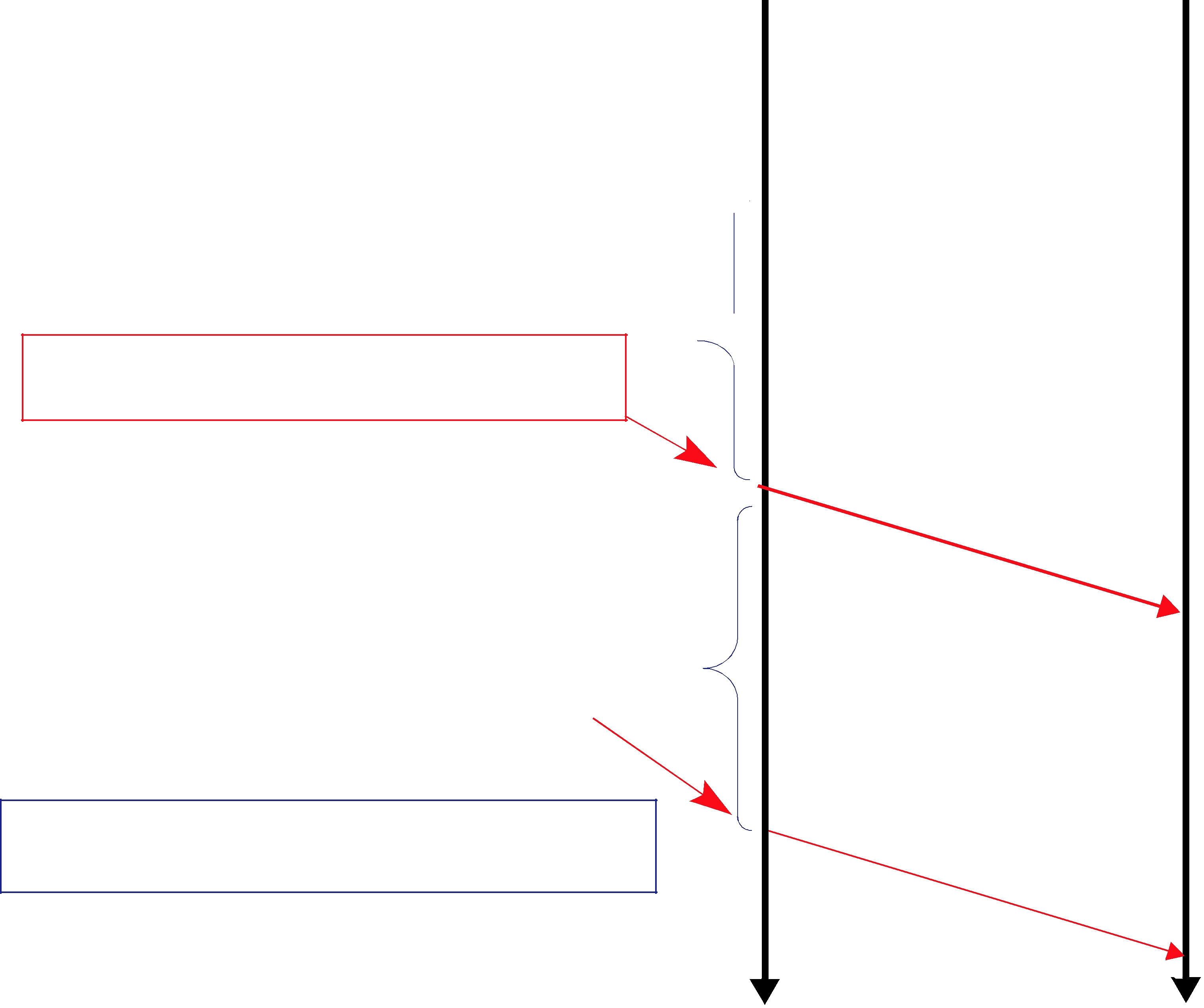
Figure 14.8 DataWriter with MANUAL_BY_PARTICIPANT Liveliness
Node A |
Node B |
Participant created
DomainParticipant::assert_liveliness()
(no liveliness message is sent)
DataWriter C created  with liveliness kind = MANUAL_BY_PARTICIPANT
with liveliness kind = MANUAL_BY_PARTICIPANT
➀

DomainParticipant::assert_liveliness() (causes Liveliness message to be sent later)
M |
A |
|
|
N |
|
Li |
U |
|
A |
||
v |
|
L |
|
eli |
|
|
ness m |
|
|
|
ess |
|
|
age |
Calling assert_liveliness(), write(), dispose(), or |
|
unregister_instance() on DataWriter C |
➀ |
(causes Liveliness message to be sent later) |
|
|
|
➀ DataWriter C’s
DDS_DataWriterQos.liveliness.lease_duration
M |
A |
|
|
|
N |
|
|
Li |
U |
|
|
A |
|
||
v |
|
L |
|
|
eli |
|
|
|
ness m |
|
|
|
|
ess |
|
|
|
age |
|
|
|
|
|
Once a MANUAL_BY_PARTICIPANT DataWriter is created, subsequent calls to assert_liveliness, write, dispose, or unregister_instance will trigger Liveliness messages, which update the liveliness status of all the participant’s DataWriters, and the participant itself.
As we saw in Figure 14.2 on page
When a new remote DomainParticipant is discovered and added to a participant’s database, Connext assumes that the remote DomainParticipant is implemented in the same way and therefore is creating the appropriate counterpart entities. Therefore, Connext will automatically add two remote discovery endpoint readers and two remote discovery endpoint writers for that remote DomainParticipant into the local database. Once that is done, there is now a match with the local discovery endpoint writers and readers, and publication DATAs and subscription DATAs can then be sent between the discovery endpoint readers/writers of the two
DomainParticipant.
When you create a DataWriter/DataReader for your user data, a publication/subscription DATA describing the newly created object is sent from the local discovery endpoint writer to the remote discovery endpoint readers of the remote DomainParticipants that are currently in the local database.
If your application changes any of the following QosPolicies for a local
❏TOPIC_DATA QosPolicy (Section 5.2.1)
❏GROUP_DATA QosPolicy (Section 6.4.4)
❏USER_DATA QosPolicy (Section 6.5.25)
❏USER_DATA QosPolicy (Section 6.5.25)
❏OWNERSHIP_STRENGTH QosPolicy (Section 6.5.16)
❏PARTITION QosPolicy (Section 6.4.5)
❏TIME_BASED_FILTER QosPolicy (Section 7.6.4)
❏LIFESPAN QoS Policy (Section 6.5.12)
What the above QosPolicies have in common is that they are all changeable and part of the built- in data (see Chapter 16:
Similarly, if the application deletes any
Discovery endpoint writers and readers have their HISTORY QosPolicy (Section 6.5.10) set to KEEP_LAST, and their DURABILITY QosPolicy (Section 6.5.7) set to TRANSIENT_LOCAL. Therefore, even if the remote DomainParticipant has not yet been discovered at the time the local user’s DataWriter/DataReader is created, the remote DomainParticipant will still be informed about the previously created DataWriter/DataReader. This is achieved by the HB and ACK/ NACK that are immediately sent by the
Endpoint discovery latency is determined by the following members of the DomainParticipant’s DISCOVERY_CONFIG QosPolicy (DDS Extension) (Section 8.5.3):
❏publication_writer
❏subscription_writer
❏publication_reader
❏subscription_reader
When a remote entity record is added, removed, or changed in the database, matching is performed with all the local entities. Only after there is a successful match on both ends can an application’s
For more information about reliable communication, see Chapter 10: Reliable Communications.
Figure 14.9 Endpoint Discovery Summary
Node A |
Node B |
|
DataWriter C created
➀
➀
Periodic HB not sent since A knows that B is
➀
Modify DataWriter C’s
UserData QoS
➀ 
pu |
|
|
|
|
b |
|
|
|
|
licat |
|
|
|
|
ion C |
|
|
|
|
|
D |
|
|
|
|
|
AT |
||
|
|
|
A |
|
|
|
|
Remote DataWriter C discovered, |
|
perio |
|
|
added to database |
|
|
|
|
|
|
dic H |
|
|
|
|
B ( |
|
|
|
|
|
F=0) |
K |
|
➁ |
|
|
|||
|
|
|
||
|
|
|
||
|
|
|
|
|
|
AC |
|
|
|
KN |
|
|
|
|
AC |
|
|
|
|
mo |
|
|
|
difi |
|
|
|
ed public |
|
|
|
ation C |
|
|
|
|
D |
|
|
|
ATA |
|
|
|
|
DataWriter C’s QoS modified, |
|
perio |
|
record in database modified |
|
|
|
|
|
dic H |
|
|
|
B ( |
|
|
|
F=0) |
|
|
|
|
|
K |
|
➁ |
|
|
|
||
|
|
|
|
|
|
AC |
|||
KN |
|
|
|
|
AC |
|
|
|
|
DataWriter C deleted |
|
del |
|
|
|
|
|
|
|
ete |
|
|
|
|
|
|
|
public |
|
|
|
||
|
|
|
|
ati |
|
|
|
|
|
|
|
|
on C |
|
|
|
|
|
|
|
|
D |
|
|
|
perio |
|
|
|
ATA |
|
|
|
dic H |
|
|
|
|
|
|
|
|
B ( |
|
|
|
|
|
|
|
|
F=0) |
|
|
|
|
|
|
|
K |
|
|
|
|
|
|
AC |
|
|
|
|
|
|
KN |
|
|
|
|
|
|
|
AC |
|
|
|
|
|
|
|
|
|
|
|
|
|
➀A’s DDS_DomainParticipantQos.discovery_config.
publication_writer.heartbeat_period
DataWriter C removed from database

 ➁
➁
➁wait random time between B’s [DDS_DomainParticipantQos. discovery_config. publication_reader.min_heartbeat_ response_delay] and [...max_heartbeat_response_delay]
Assume participants A and B have been discovered on both sides. A’s DiscoveryConfigQosPolicy.publication_writer.heartbeats_per_max_samples = 0, so no HB is piggybacked with the publication DATA. A HB with F=0 is a request for an ACK/NACK. The periodic and initial repeat participant DATAs are omitted from the diagram.
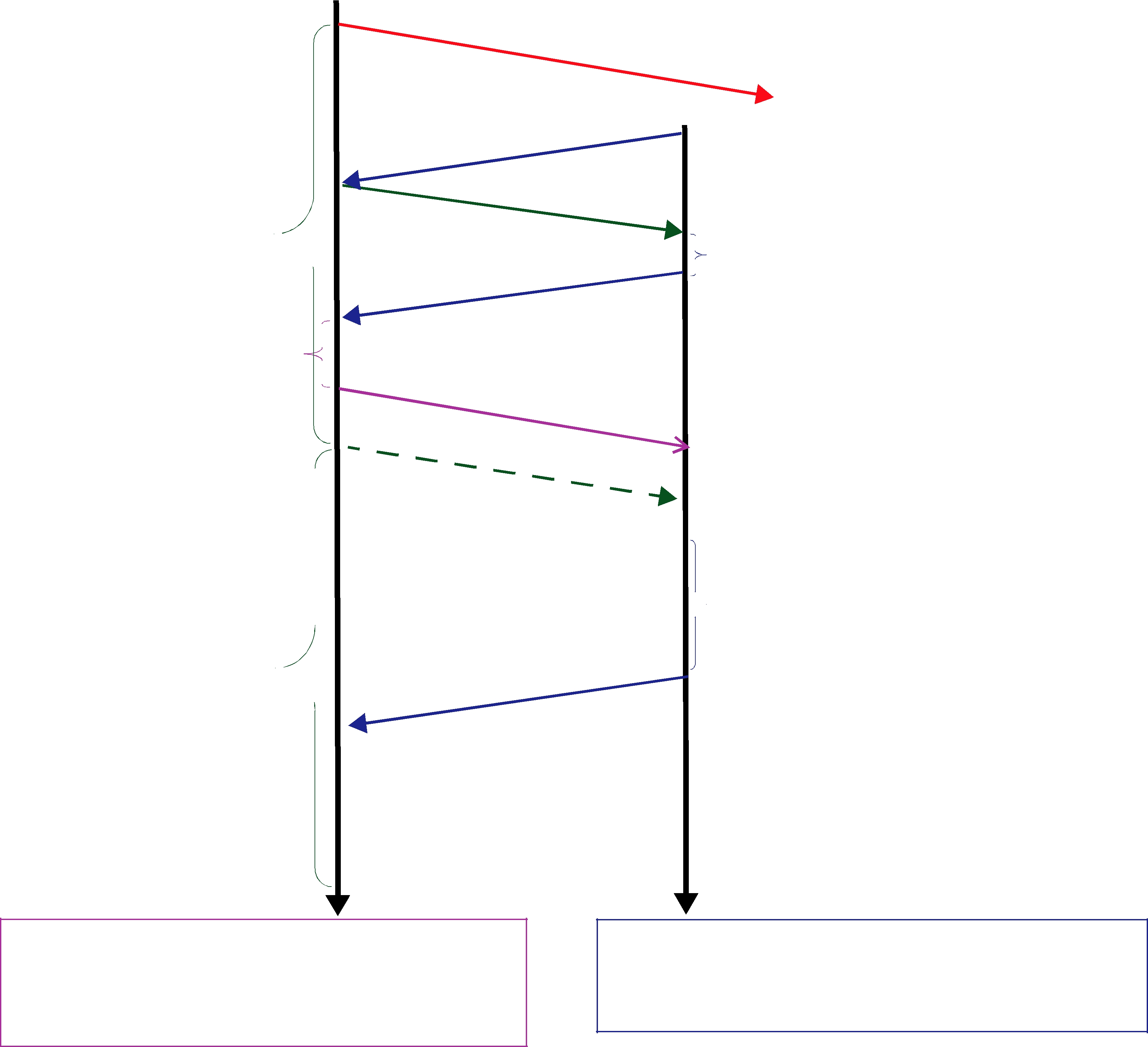
Figure 14.10 DataWriter Discovered by
Node A
Create DataWriter C
Send HB to see if the discovery publication reader on Node B is
➀ 
Public |
|
|
|
|
|
|
|
|
|
|
|
Node B |
|
|
||||
e |
nd |
ation |
C |
D |
|
|
|
|
|
|
|
|
|
|||||
point |
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
ATA se |
nt to disc |
|
|
|
|||||||||
parti |
cip |
|
|
readers |
of |
|
|
ov |
|
|
||||||||
|
|
a |
|
|
|
|
|
|
disc |
|
|
|
|
|||||
|
|
|
|
nts in |
d |
|
|
|
|
ov |
|
|
|
|
||||
|
|
|
|
|
|
|
at |
ab |
as |
er |
ed |
re |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
m |
ote |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
e |
|
|
|
Node B hasn’t been discovered by |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Node A yet, so it doesn’t receive |
|
|
|
|
|
|
|
|
|
|
ATA |
|
|
|
|
the publication DATA for C |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
nt |
B D |
|
|
|
|
|
|
|
|
|||
|
|
|
ipa |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
rtic |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
pa |
|
|
|
|
|
|
|
|
|
|
|
|
Participant B created |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
H |
|
|
|
|
|
B ( |
F=1) |
|
|
|
|
|
|
|
|
|
|
|
Latest DATA from C has |
|
|
K |
|
➁ not been received |
|
|
|
||
|
AC |
|
|
|
|
|
|
||
KN |
|
|
|
|
AC |
|
|
|
|
|
|
|
Public |
|
|
|
|
|
|
|
|
|||
➂ |
d |
isc |
|
ation |
C |
D |
|
|
|
|
||||
of |
|
overy |
e |
nd |
|
A se |
nt t |
o |
||||||
|
|
|
rem |
ote |
|
point r |
e |
|
||||||
|
|
|
|
|
|
|
ader |
|||||||
|
|
|
|
|
|
partici |
pa |
|||||||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
nt B |
|
||
|
|
|
perio |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
dic |
|
|
|
|
|
|
|
|
➀ Participant A’s |
|
|
|
|
|
|
HB ( |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
F= |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
0) |
|
|
|
|
[DDS_DomainParticipant |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Qos.discovery_config. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
publication_writer. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
heartbeat_period) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Remote DataWriter C finally discovered, added to database

 ➁
➁
➀ 
ACK
➂wait random time between A’s [DDS_DomainParticipantQos.discovery_config. publication_writer.min_nack_response_delay] and (...max_nack_response_delay]
➁wait random time between B’s [DDS_DomainParticipantQos.discovery_config. publication_reader.min_heartbeat_response_delay] and (...max_heartbeat_response_delay]
Writer C is created on Participant A before Participant A discovers Participant B. Assuming DiscoveryConfigQosPolicy.publication_writer.heartbeats_per_max_samples = 0, no HB is piggybacked with the publication DATA. Participant B has A in its peer list, but not vice versa. Accept_unknown_locators is true. On A, in response to receiving the new participant B DATA message, a participant A DATA message is sent to B. The discovery endpoint reader on A will also send an ACK/NACK to the discovery endpoint writer on B. (Initial repeat participant messages and periodic participant messages are omitted from this diagram for simplicity, see
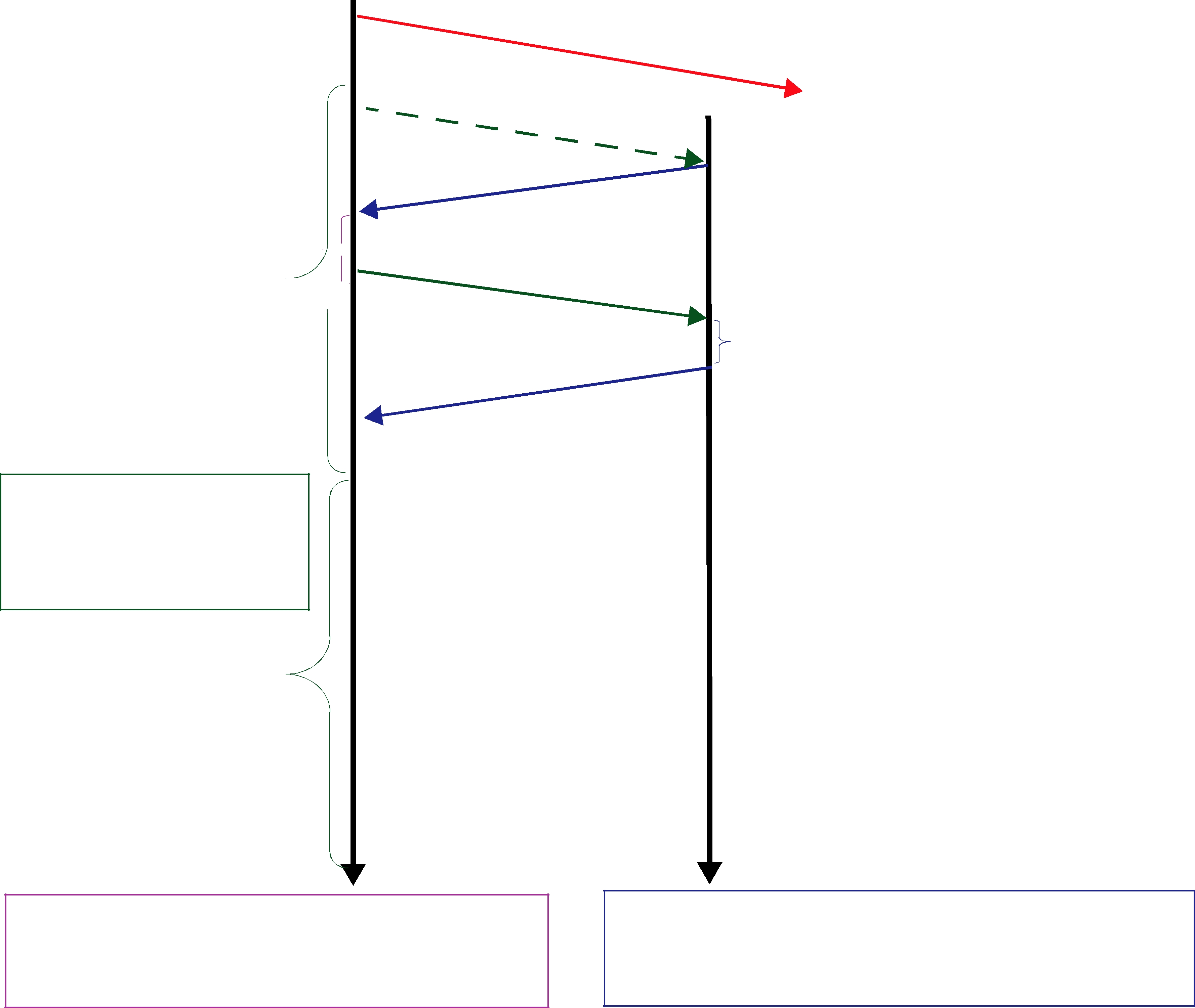
Figure 14.11 DataWriter Discovered by
Node A
Create DataWriter C
Public |
|
|
|||||
e |
nd |
p |
|
ation |
C |
D |
|
|
|
||||||
p |
|
oint re |
ad |
ATA |
|||
artici |
pa |
ers of |
|||||
|
|
||||||
|
|
|
|
nts |
|
|
|
|
Node B |
|
sent |
|
|
|
to disc |
|
dis |
ov |
|
co |
ery |
|
|
ver |
|
|
ed |
|
|
remote |
|
➂
 ➀
➀ 

➀ Participant A’s [DDS_DomainParticipant Qos.discovery_config. publication_writer. heartbeat_period)
perio |
|
|
|
|
|
dic A |
|
|
|
||
|
|
D |
|
|
|
|
|
|
ATA |
|
|
|
|
|
|
K |
|
|
|
|
AC |
|
|
|
KN |
|
|
||
AC |
|
|
|
|
|
C |
|
|
|
|
|
D |
|
|
|
|
|
AT |
|
|
|
|
|
|
A + H |
|
|||
|
|
|
|
B ( |
|
|
|
|
|
|
F=0) |
|
|
|
|
K |
|
|
|
AC |
|
||
KN |
|
|
|
||
AC |
|
|
|
|
|
Participant B created
A is discovered. ACKNACK sent immediately to discovery endpoint writer of the newly discovered remote participant
|
Remote DataWriter C discovered, |
➁ |
added to database |
|
➀
➂wait random time between A’s [DDS_DomainParticipantQos.discovery_config. publication_writer.min_nack_response_delay] and (...max_nack_response_delay]
➁wait random time between B’s [DDS_DomainParticipantQos.discovery_config. publication_reader.min_heartbeat_response_delay] and (...max_heartbeat_response_delay]
Writer C is created on Participant A before Participant A discovers Participant B. Assuming DiscoveryConfigQosPolicy.publication_writer.heartbeats_per_max_samples = 0, no HB is piggybacked with the publication DATA message. Participant A has B in its peer list, but not vice versa. Accept_unknown_locators is true. In response to receiving the new Participant A DATA message on node B, a participant B DATA message will be sent to A. The discovery endpoint writer on Node B will also send a HB to the discovery endpoint reader on Node A. These are omitted in the diagram for simplicity. (Initial repeat participant messages and periodic participant messages are omitted from this diagram, see
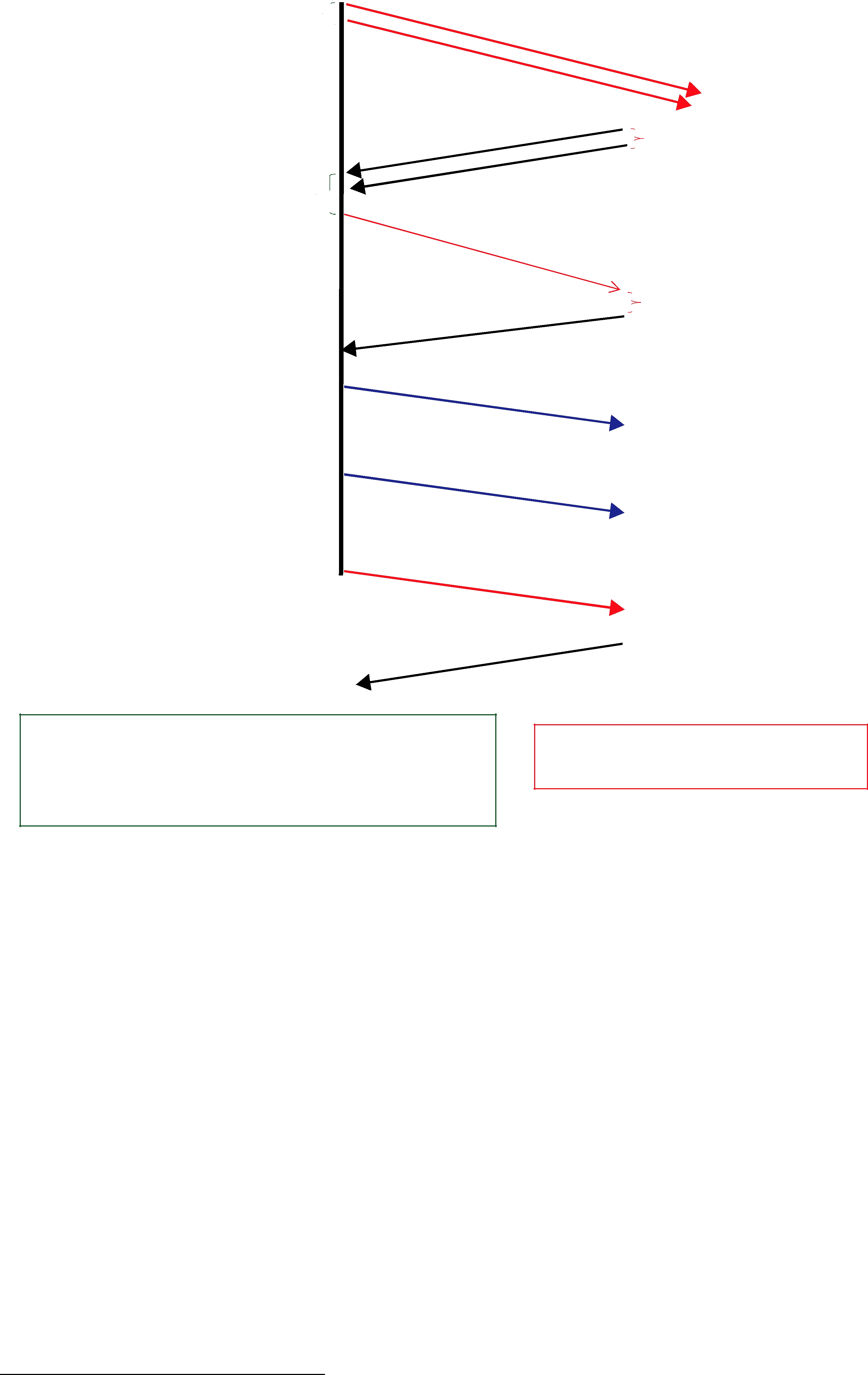
14.3.3Discovery Traffic Summary
Node A |
Node B |
|
Participant A created
➀

|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
artic |
|
|
|
|
||
|
|
|
|
|
|
ip |
|
|
|
|
|
|
|
|
|
|
|
ant |
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
init |
|
|
|
|
|
|
D |
|
||
ial |
|
|
|
|
|
AT |
||||
|
|
|
r |
|
|
|
|
|
A |
|
|
|
|
|
e |
|
|
|
|
|
|
p |
a |
rtic |
p |
e |
a |
t of |
|
|
|
|
ip |
|
|
|
|||||||
|
|
|
|
|
||||||
|
|
|
|
|
|
|
||||
|
|
|
|
ant |
|
|
|
|
||
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
Newly discovered Participant B added to database
➀ 
DataWriter C created
DataWriter C deleted
Participant A destroyed
|
|
|
|
|
|
|
nt |
B DATA |
|
|
|
|
Participant B created |
||
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ipa |
|
|
|
|
|
|
|
|
|||
|
|
rtic |
|
|
|
|
|
|
|
|
|
|
|
||
|
pa |
|
|
|
|
|
|
|
|
of |
|
|
|
➁ |
|
|
|
|
|
|
|
|
|
|
|
at |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
pe |
|
|
|
|
|
||
|
|
|
|
|
|
|
l re |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
itia |
|
|
|
|
A |
|
|
|
|
|
|
|
|
in |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
|
|
|
|
|
|
nt |
B D |
|
|
|
|
||
|
|
|
|
|
|
|
ipa |
|
|
|
|
|
|
|
|
|
|
|
|
|
rtic |
|
|
|
|
|
|
|
|
||
|
|
|
pa |
|
|
|
|
|
|
|
|
|
|
||
par |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ti |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ci |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pa |
nt |
A D |
|
|
|
|
|
|
|
Newly discovered Participant A |
|||
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
AT |
|
|
|
|
|
|
added to database |
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ATA |
|
|
|
|
|
|
➁ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
ant |
B D |
|
|
|
|
|
|
|
|
||||
ticip |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
par |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
public |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ation C |
D |
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
ATA |
|
|
|
|
|
|
Remote DataWriter C |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
discovered, added to database |
public |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ation C |
D |
|
|
|
|
|
|
|
Remote DataWriter C deleted, |
|||||
|
|
|
|
|
|
|
ATA ( |
del |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
ete) |
|
|
|
removed from database |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
partici |
|
|
|
|
|
|
|
|
|
|
|
|
|
Remote Participant A |
|
|
pant |
A |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
ATA (d |
|
|
|
|
|
removed from database |
||
|
|
|
|
|
|
|
|
|
elet |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
e) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
) |
|
|
Participant B destroyed |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
lete |
|||||
|
|
|
|
|
|
|
ATA (de |
|
|
|
|
|
|||
|
|
nt |
B D |
|
|
|
|
|
|
|
|
||||
|
ipa |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
rtic |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pa |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
➀wait random time (between min_initial_participant_announcement_period and max_initial_participant_announcement_period) for [initial_participant_announcements] = 1 (using values from A’s DiscoveryConfigQosPolicy)
➁same as ➀, but using participant B’s QoS
This diagram shows both phases of the discovery process. Participant A is created first, followed by Participant B. Each has the other in its peers list. After they have discovered each other, a DataWriter is created on Participant A. Periodic participant DATAs, HBs and ACK/NACKs are omitted from this diagram.
14.3.4
Each DomainParticipant needs to be uniquely identified in the domain and specify which other DomainParticipants it is interested in communicating with. The WIRE_PROTOCOL QosPolicy (DDS Extension) (Section 8.5.9) uniquely identifies a DomainParticipant in the domain. The DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2) specified the peer participants it is interested in communicating with.
There is a
For example, if the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2)’s participant_liveliness_assert_period and participant_liveliness_lease_duration fields are set
to small values, the discovery of stale remote DomainParticipants will occur faster, but more discovery traffic will be sent over the network. Setting the participant’s heartbeat_period1 to a
1.heartbeat_period is part of the DDS_RtpsReliableWriterProtocol_t structure used in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2)’s publication_writer and subscription_writer fields.

small value can cause
DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2) — specifies how other DomainPartici- pants in the network can communicate with this DomainParticipant, and which other DomainParticipants in the network this DomainParticipant is interested in communicating with. See also: Ports Used for Discovery (Section 14.5).
DISCOVERY_CONFIG QosPolicy (DDS Extension) (Section 8.5.3) — specifies the QoS of the dis- covery readers and writers (parameters that control the HB and ACK rates of discovery endpoint readers/writers, and periodic refreshing of participant DATA from discovery participant readers/writers). It also allow you to configure asynchronous writers in order to send data with a larger size than the transport message size.
DOMAIN_PARTICIPANT_RESOURCE_LIMITS QosPolicy (DDS Extension) (Section 8.5.4) — specifies the number of local and remote entities expected in the system.
WIRE_PROTOCOL QosPolicy (DDS Extension) (Section 8.5.9) — specifies the rtps_app_id and rtps_host_id that uniquely identify the participant in the domain.
The other important parameter is the domain ID: DomainParticipants can only discover each other if they belong to the same domain. The domain ID is a parameter passed to the create_participant() operation (see Section 8.3.1).
14.4Debugging Discovery
To understand the flow of messages during discovery, you can increase the verbosity of the messages logged by Connext so that you will see whenever a new entity is discovered, and whenever there is a match between a local entity and a remote entity.
This can be achieved with the logging API:
(NDDS_CONFIG_LOG_CATEGORY_ENTITIES, NDDS_CONFIG_LOG_VERBOSITY_STATUS_REMOTE);
Using the scenario in the summary diagram in Section 14.3.3, these are the messages as seen on DomainParticipant A:
[D0049|ENABLE]DISCPluginManager_onAfterLocalParticipantEnabled:announcing new local participant: 0XA0A01A1,0X5522,0X1,0X1C1 [D0049|ENABLE]DISCPluginManager_onAfterLocalParticipantEnabled:at {46c614d9,0C43B2DC}
•(The above messages mean: First participant A DATA sent out when participant A is enabled.)
DISCSimpleParticipantDiscoveryPluginReaderListener_onDataAvailable:discovered new participant: host=0x0A0A01A1, app=0x0000552B, instance=0x00000001 DISCSimpleParticipantDiscoveryPluginReaderListener_onDataAvailable:at {46c614dd,8FA13C1F} DISCParticipantDiscoveryPlugin_assertRemoteParticipant:plugin discovered/updated remote participant: 0XA0A01A1,0X552B,0X1,0X1C1 DISCParticipantDiscoveryPlugin_assertRemoteParticipant:at {46c614dd,8FACE677} DISCParticipantDiscoveryPlugin_assertRemoteParticipant:plugin accepted new remote participant: 0XA0A01A1,0X552B,0X1,0X1C1 DISCParticipantDiscoveryPlugin_assertRemoteParticipant:at {46c614dd,8FACE677}
• (The above messages mean: Received participant B DATA.)
DISCSimpleParticipantDiscoveryPlugin_remoteParticipantDiscovered:at {46c614dd,8FC02AF7}
•(The above messages mean: Resending participant A DATA to the newly discovered remote participant.)
PRESPsService_linkToLocalReader:assert remote 0XA0A01A1,0X552B,0X1,0X200C2, local 0x000200C7 in reliable reader service
PRESPsService_linkToLocalWriter:assert remote 0XA0A01A1,0X552B,0X1,0X200C7, local 0x000200C2 in reliable writer service
PRESPsService_linkToLocalWriter:assert remote 0XA0A01A1,0X552B,0X1,0X4C7, local 0x000004C2 in reliable writer service
PRESPsService_linkToLocalWriter:assert remote 0XA0A01A1,0X552B,0X1,0X3C7, local 0x000003C2 in reliable writer service
PRESPsService_linkToLocalReader:assert remote 0XA0A01A1,0X552B,0X1,0X4C2, local 0x000004C7 in reliable reader service
PRESPsService_linkToLocalReader:assert remote 0XA0A01A1,0X552B,0X1,0X3C2, local 0x000003C7 in reliable reader service
PRESPsService_linkToLocalReader:assert remote 0XA0A01A1,0X552B,0X1,0X100C2, local 0x000100C7 in best effort reader service
•(The above messages mean: Automatic matching of the discovery readers and writers. A
DISCSimpleParticipantDiscoveryPluginReaderListener_onDataAvailable:discovered mod- ified participant: host=0x0A0A01A1, app=0x0000552B, instance=0x00000001 DISCParticipantDiscoveryPlugin_assertRemoteParticipant:plugin discovered/updated remote participant: 0XA0A01A1,0X552B,0X1,0X1C1 DISCParticipantDiscoveryPlugin_assertRemoteParticipant:at {46c614dd,904D876C}
• (The above messages mean: Received participant B DATA.)
DISCPluginManager_onAfterLocalEndpointEnabled:announcing new local publication: 0XA0A01A1,0X5522,0X1,0X80000003 DISCPluginManager_onAfterLocalEndpointEnabled:at {46c614d9,1013B9F0}
DISCSimpleEndpointDiscoveryPluginPDFListener_onAfterLocalWriterEnabled:announcing new publication: 0XA0A01A1,0X5522,0X1,0X80000003 DISCSimpleEndpointDiscoveryPluginPDFListener_onAfterLocalWriterEnabled:at {46c614d9,101615EB}
• (The above messages mean: Publication C DATA has been sent.)
DISCSimpleEndpointDiscoveryPlugin_subscriptionReaderListenerOnDataAvailable:dis- covered subscription: 0XA0A01A1,0X552B,0X1,0X80000004 DISCSimpleEndpointDiscoveryPlugin_subscriptionReaderListenerOnDataAvailable:at {46c614dd,94FAEFEF}
DISCEndpointDiscoveryPlugin_assertRemoteEndpoint:plugin discovered/updated remote endpoint: 0XA0A01A1,0X552B,0X1,0X80000004 DISCEndpointDiscoveryPlugin_assertRemoteEndpoint:at {46c614dd,950203DF}
• (The above messages mean: Receiving subscription D DATA from Node B.)
PRESPsService_linkToLocalWriter:assert remote 0XA0A01A1,0X552B,0X1,0X80000004, local 0x80000003 in best effort writer service
•(The above message means:
[D0049|DELETE_CONTAINED]DISCPluginManager_onAfterLocalEndpointDeleted:announcing disposed local publication: 0XA0A01A1,0X5522,0X1,0X80000003 [D0049|DELETE_CONTAINED]DISCPluginManager_onAfterLocalEndpointDeleted:at {46c61501,288051C8} [D0049|DELETE_CONTAINED]DISCSimpleEndpointDiscoveryPluginPDFListener_onAfterLocalW riterDeleted:announcing disposed publication: 0XA0A01A1,0X5522,0X1,0X80000003 [D0049|DELETE_CONTAINED]DISCSimpleEndpointDiscoveryPluginPDFListener_onAfterLocalW riterDeleted:at {46c61501,28840E15}

• (The above messages mean: Publication C DATA(delete) has been sent.)
DISCPluginManager_onBeforeLocalParticipantDeleted:announcing before disposed local participant: 0XA0A01A1,0X5522,0X1,0X1C1 DISCPluginManager_onBeforeLocalParticipantDeleted:at {46c61501,28A11663}
• (The above messages mean: Participant A DATA(delete) has been sent.)
DISCParticipantDiscoveryPlugin_removeRemoteParticipantsByCookie:plugin removing 3 remote entities by cookie DISCParticipantDiscoveryPlugin_removeRemoteParticipantsByCookie:at {46c61501,28E38A7C} DISCParticipantDiscoveryPlugin_removeRemoteParticipantI:plugin discovered dis- posed remote participant: 0XA0A01A1,0X552B,0X1,0X1C1 DISCParticipantDiscoveryPlugin_removeRemoteParticipantI:at {46c61501,28E68E3D} DISCParticipantDiscoveryPlugin_removeRemoteParticipantI:remote entity removed from database: 0XA0A01A1,0X552B,0X1,0X1C1 DISCParticipantDiscoveryPlugin_removeRemoteParticipantI:at {46c61501,28E68E3D}
•(The above messages mean: Removing discovered entities from local database, before shutting down.)
As you can see, the messages are encoded, since they are primarily used by RTI support personnel.
For more information on the message logging API, see Controlling Messages from Connext (Section 21.2).
If you notice that a remote entity is not being discovered, check the QoS related to discovery (see Section 14.3.4).
If a remote entity is discovered, but does not match with a local entity as expected, check the QoS of both the remote and local entity.
14.5Ports Used for Discovery
There are two kinds of traffic in a Connext application: discovery (meta) traffic, and user traffic.
Note: The ports described in this section are used for incoming data. Connext uses ephemeral ports for outbound data.
Connext uses the RTPS wire protocol. The discovery protocols defined by RTPS rely on well- known ports to initiate discovery. These
The
In order for all Participants in a system to correctly discover each other, it is important that they all use the same port mapping expressions.
Table 14.2 WireProtocol QosPolicy’s rtps_well_known_ports (DDS_RtpsWellKnownPorts_t)
Type |
Field Name |
Description |
|
|
|
|
|
|
|
The base port offset. All mapped |
|
|
port_base |
offset by this value. Resulting ports must be within the |
|
|
|
range imposed by the underlying transport. |
|
|
|
|
|
|
domain_id_gain |
Tunable gain parameters. See Section 14.5.4. |
|
|
|
||
DDS_Long |
participant_id_gain |
||
|
|||
|
|
||
|
builtin_multicast_port_offset |
Additional offset for |
|
|
builtin_unicast_port_offset |
||
|
|
|
|
|
user_multicast_port_offset |
Additional offset for user traffic port. See Inbound Ports for |
|
|
user_unicast_port_offset |
||
|
|
|
In addition to the parameters listed in Table 14.2, the port formulas described below depend on:
❏The domain ID specified when the DomainParticipant is created (see Section 8.3.1). The domain ID ensures no port conflicts exist between Participants belonging to different domains. This also means that discovery traffic in one domain is not visible to
DomainParticipants in other domains.
❏The participant_id is a field in the WIRE_PROTOCOL QosPolicy (DDS Extension) (Section 8.5.9), see Section 8.5.9.1. The participant_id ensures that unique unicast port numbers are assigned to DomainParticipants belonging to the same domain on a given host.
Backwards Compatibility: Connext 4.5 supports the standard DDS Interoperability Wire Protocol based on the
Port Aliasing: When modifying the port mapping parameters, avoid port aliasing. This would result in undefined discovery behavior. The chosen parameter values will also determine the maximum possible number of domains in the system and the maximum number of participants per domain. Additionally, any resulting mapped port number must be within the range imposed by the underlying transport. For example, for UDPv4, this range is typically between 1024 and 65535.
14.5.1Inbound Ports for
The Wire Protocol QosPolicy’s rtps_well_known_ports.metatraffic_unicast_port determines the port used for receiving
metatraffic_unicast_port = port_base +
(domain_id_gain * Domain ID) + (participant_id_gain * participant_id) +
builtin_unicast_port_offset
Similarly, rtps_well_known_ports.metatraffic_multicast_port receiving
determines the port used for multicast group addresses are
metatraffic_multicast_port = port_base +
(domain_id_gain * Domain ID) + builtin_multicast_port_offset
Note: Multicast is only used for
14.5.2Inbound Ports for User Traffic
RTPS also defines the default multicast and unicast ports on which DataReaders and DataWriters receive user traffic. These default ports can be overridden using the DataReader’s TRANSPORT_MULTICAST QosPolicy (DDS Extension) (Section 7.6.5) and TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23), or the DataWriter’s TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23).
The WireProtocol QosPolicy’s rtps_well_known_ports.usertraffic_unicast_port determines the port used for receiving user data using unicast:
usertraffic_unicast_port = port_base +
(domain_id_gain * Domain ID) + (participant_id_gain * participant_id)+ user_unicast_port_offset
Similarly, rtps_well_known_ports.usertraffic_multicast_port determines the port used for receiving user data using multicast. The corresponding multicast group addresses can be configured using the TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23).
usertraffic_multicast_port = port_base +
(domain_id_gain * Domain ID) + user_multicast_port_offset
14.5.3Automatic Selection of participant_id and Port Reservation
The WIRE_PROTOCOL QosPolicy (DDS Extension) (Section 8.5.9) rtps_reserved_ports_mask field determines what type of ports are reserved when the DomainParticipant is enabled. See Choosing Participant IDs (Section 8.5.9.1).
14.5.4Tuning domain_id_gain and participant_id_gain
The domain_id_gain is used as a multiplier of the domain ID. Together with participant_id_gain (Section 14.5.4), these values determine the highest domain ID and participant_id allowed on this network.
In general, there are two ways to set up the domain_id_gain and participant_id_gain parameters.
❏If domain_id_gain > participant_id_gain, it results in a port mapping layout where all DomainParticipants in a domain occupy a consecutive range of domain_id_gain ports. Precisely, all ports occupied by the domain fall within:
(port_base + (domain_id_gain * Domain ID))
and:
(port_base + (domain_id_gain * (Domain ID + 1)) - 1)
In this case, the highest domain ID is limited only by the underlying transport's maximum port. The highest participant_id, however, must satisfy:
max_participant_id < (domain_id_gain / participant_id_gain)
❏On the contrary, if domain_id_gain <= participant_id_gain, it results in a port mapping layout where a given domain's DomainParticipant instances occupy ports spanned across the entire valid port range allowed by the underlying transport. For instance, it results in the following potential mapping:
Mapped Port |
Domain ID |
Participant ID |
|
|
|
|
|
|
|
|
|
|
1 |
2 |
|
|
|
||
|
0 |
||
|
|
||
|
|
|
|
higher port number |
1 |
1 |
|
|
|
||
|
0 |
||
|
|
||
|
|
|
|
|
1 |
0 |
|
|
|
||
lower port number |
0 |
||
|
|||
|
|
|
In this case, the highest participant_id maximum port. The highest domain_id,
is limited only by the underlying transport's however, must satisfy:
max_domain_id < (participant_id_gain / domain_id_gain)
The domain_id_gain also determines the range of the
domain_id_gain >
abs(builtin_multicast_port_offset - user_multicast_port_offset)
and
domain_id_gain >
abs(builtin_unicast_port_offset - user_unicast_port_offset)
Violating this may result in port aliasing and undefined discovery behavior.
The participant_id_gain also determines the range of builtin_unicast_port_offset and user_unicast_port_offset.
participant_id_gain >
abs(builtin_unicast_port_offset - user_unicast_port_offset)
In all cases, the resulting ports must be within the range imposed by the underlying transport.
Chapter 15 Transport Plugins
Connext has a
There are essentially three categories of transport plugins:
❏Builtin Transport Plugins Connext comes with a set of commonly used transport plugins. These ‘builtin’ plugins include UDPv4, UDPv6, and shared memory. So that Connext applications can work
❏Extension Transport Plugins RTI offers extension transports, including RTI Secure WAN Transport (see Chapter 24 and Chapter 25) and RTI TCP Transport (see Chapter 36).
❏
This chapter describes the following:
❏Builtin Transport Plugins (Section 15.1)
❏Extension Transport Plugins (Section 15.2)
❏The NDDSTransportSupport Class (Section 15.3)
❏Explicitly Creating Builtin Transport Plugin Instances (Section 15.4)
❏Setting Builtin Transport Properties of the Default Transport
❏Setting Builtin Transport Properties with the PropertyQosPolicy (Section 15.6)
❏Installing Additional Builtin Transport Plugins with register_transport() (Section 15.7)
❏Installing Additional Builtin Transport Plugins with PropertyQosPolicy (Section 15.8)

15.1Builtin Transport Plugins
There are two ways in which the builtin transport plugins may be registered:
❏Default builtin Transport Instances: Builtin transports that are turned "on" in the TRANSPORT_BUILTIN QosPolicy (DDS Extension) (Section 8.5.7) are implicitly registered when (a) the DomainParticipant is enabled, (b) the first DataWriter/DataReader is created, or (c) you look up a builtin DataReader (by calling lookup_datareader() on a
Subscriber), whichever happens first. The builtin transport plugins have default properties. If you want to change these properties, do so before1 the transports are registered.
❏Other Transport Instances: There are two ways to install
•Transport plugins may be explicitly registered by first creating an instance of the transport plugin (by calling NDDS_Transport_UDPv4_new(),
NDDS_Transport_UDPv6_new() or NDDS_Transport_Shmem_new(), see Section 15.4), then calling register_transport() (Section 15.7). (For example, suppose you want an extra instance of a transport.) (Not available for the Java or .NET API.)
•Additional builtin transport instances can also be installed through the PROPERTY QosPolicy (DDS Extension) (Section 6.5.17).
To configure the properties of the builtin transports:
❏Set properties by calling set_builtin_transport_property() (see Section 15.5) or
❏Specify predefined property strings in the DomainParticipant’s PropertyQosPolicy, as described in Section 15.6.
❏For other builtin transport instances:
•If the builtin transport plugin is created with NDDS_Transport_UDPv4_new(),
NDDS_Transport_UDPv6_new() or NDDS_Transport_Shmem_new(), properties can be specified during creation time. See Explicitly Creating Builtin Transport Plugin Instances (Section 15.4).
•If the additional builtin transport instances are installed through the PROPERTY QosPolicy (DDS Extension) (Section 6.5.17), the properties of the builtin transport plugins can also be specified through that same QosPolicy.
15.2Extension Transport Plugins
If you want to change the properties for an extension transport plugin, do so before1 the plugin is registered.
There are two ways to install an extension transport plugin:
❏Implicit Registration: Transports can be installed through the predefined strings in the DomainParticipant’s PropertyQosPolicy. Once the transport’s properties are specified in the PropertyQosPolicy, the transport will be implicitly registered when (a) the DomainParticipant is enabled, (b) the first DataWriter/DataReader is created, or (c) you look up a builtin DataReader (by calling lookup_datareader() on a Subscriber), whichever happens first.
1.Any transport property changes made after the plugin is registered will have no effect.

QosPolicies can also be configured from XML resources (files,
❏Explicit Registration: Transports may be explicitly registered by first creating an instance of the transport plugin (see Section 15.4) and then calling register_transport() (see Section 15.7).
15.3The NDDSTransportSupport Class
The register_transport() and set_builtin_transport_property() operations are part of the
NDDSTransportSupport class, which includes the operations listed in Table 15.1.
Table 15.1 Transport Support Operations
Operation |
Description |
Reference |
|
|
|
|
|
get_transport_plugin |
Retrieves a previously registered transport plugin. |
|
|
|
|
||
register_transport |
Registers a transport plugin for use with a |
||
DomainParticipant. |
|
||
|
|
||
|
|
|
|
get_builtin_transport_property |
Gets the properties used to create a builtin transport |
|
|
|
plugin. |
||
set_builtin_transport_property |
Sets the properties used to create a builtin transport |
||
|
|||
|
plugin. |
|
|
add_send_route |
Adds a route for outgoing messages. |
||
|
|
|
|
add_receive_route |
Adds a route for incoming messages. |
||
|
|
|
|
lookup_transport |
Looks up a transport plugin within a DomainParticipant. |
||
|
|
|
15.4Explicitly Creating Builtin Transport Plugin Instances
The builtin transports (UDPv4, UDPv6, and Shared Memory) are implicitly created by default (if they are enabled via the TRANSPORT_BUILTIN QosPolicy (DDS Extension) (Section 8.5.7)). Therefore, you only need to explicitly create a new instance if you want an extra instance (suppose you want two UDPv4 transports, one with special settings).
Transport plugins may be explicitly registered by first creating an instance of the transport plugin and then calling register_transport() (Section 15.7). (For example, suppose you want an extra instance of a transport.) (Not available for the Java API.)
To create an instance of a builtin transport plugin, use one of the following functions:
NDDS_Transport_Plugin* NDDS_Transport_UDPv4_new (
const struct NDDS_Transport_UDPv4_Property_t * property_in)
NDDS_Transport_Plugin* NDDS_Transport_UDPv4_new (
const struct NDDS_Transport_UDPv4_Property_t * property_in)
NDDS_Transport_Plugin* NDDS_Transport_Shmem_new (
const struct NDDS_Transport_Shmem_Property_t * property_in)
property_in Desired behavior of this transport. May be NULL for default properties.
For details on using these functions, please see the API Reference HTML documentation.

Your application may create and register multiple instances of these transport plugins with Connext. This may be done to partition the network interfaces across multiple domains. However, note that the underlying transport, the operating system's IP layer, is still a "singleton." For example, if a unicast transport has already bound to a port, and another unicast transport tries to bind to the same port, the second attempt will fail.
15.5Setting Builtin Transport Properties of the Default Transport
Perhaps you want to use one of the builtin transports, but need to modify the properties. (For default values, please see the API Reference HTML documentation.) Used together, the two operations below allow you to customize properties of the builtin transport when it is implicitly registered (see Section 15.1).
Note: Another way to change the properties is with the Property QosPolicy, see Section 15.6. Changing properties with the Property QosPolicy will overwrite the properties set by calling set_builtin_transport_property().
DDS_ReturnCode_t NDDSTransportSupport::get_builtin_transport_property (DDSDomainParticipant * participant_in,
DDS_TransportBuiltinKind builtin_transport_kind_in,
struct NDDS_Transport_Property_t &builtin_transport_property_inout)
DDS_ReturnCode_t NDDSTransportSupport::set_builtin_transport_property (DDSDomainParticipant * participant_in,
DDS_TransportBuiltinKind builtin_transport_kind_in, const struct NDDS_Transport_Property_t
&builtin_transport_property_in)
participant_in A valid
builtin_transport_kind_in The builtin transport kind for which to specify the properties.
builtin_transport_property_inout (Used by the “get” operation only.) The storage area where the retrieved property will be output. The specific type required by the builtin_transport_kind_in must be used.
builtin_transport_property_in (Used that will be used to the create the builtin_transport_kind_in
by the “set” operation only.) The new transport property the builtin transport plugin. The specific type required by must be used.
In this example, we want to use the builtin UDPv4 transport, but with modified properties.
/* Before reaching this point, create a disabled DomainParticipant */ struct NDDS_Transport_UDPv4_Property_t property =
NDDS_TRANSPORT_UDPV4_PROPERTY_DEFAULT;
if (NDDSTransportSupport::get_builtin_transport_property( participant, DDS_TRANSPORTBUILTIN_UDPv4, (struct NDDS_Transport_Property_t&)property) !=
DDS_RETCODE_OK) {
printf("**Error: get builtin transport property\n");
}
/* Make your desired changes here */
/* For example, to increase the UDPv4 max msg size to 64K: */ property.parent.message_size_max = 65535; property.recv_socket_buffer_size = 65535;

property.send_socket_buffer_size = 65535;
if (NDDSTransportSupport::set_builtin_transport_property( participant, DDS_TRANSPORTBUILTIN_UDPv4,
(struct NDDS_Transport_Property_t&)property) != DDS_RETCODE_OK) {
printf("***Error: set builtin transport property\n");
}
/* Enable the participant to turn on communications with other participants in the domain using the new properties for the automatically registered builtin transport plugins.*/
if
}
Note: Builtin transport property changes will have no effect after the builtin transport has been registered. The builtin transports are implicitly registered when (a) the DomainParticipant is enabled, (b) the first DataWriter/DataReader is created, or (c) you lookup a builtin DataReader, whichever happens first.
Note: If message_size_max is increased from the default for any of the
15.6Setting Builtin Transport Properties with the PropertyQosPolicy
The PROPERTY QosPolicy (DDS Extension) (Section 6.5.17) allows you to set name/value pairs of data and attach them to an entity, such as a DomainParticipant.
To assign properties, use the add_property() operation:
DDS_ReturnCode_t DDSPropertyQosPolicyHelper::add_property (DDS_PropertyQosPolicy policy,
const char * name, const char * value, DDS_Boolean propagate)
For more information on add_property() and the other operations in the DDSPropertyQosPolicyHelper class, please see Table 6.56, “PropertyQoSPolicyHelper Operations,” on page
The ‘name’ part of the name/value pairs is a predefined string. The property names for the builtin transports are described in these tables:
❏Table 15.2, “Properties for the Builtin UDPv4 Transport,” on page
❏Table 15.3, “Properties for Builtin UDPv6 Transport,” on page
❏Table 15.4, “Properties for Builtin
❏“Notes Regarding Loopback and Shared Memory” (Section 15.6.1 on page
❏“Setting the Maximum
❏“Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ Address Lists” (Section 15.6.3 on page 15- 18)
Note: Changing properties with the PROPERTY QosPolicy (DDS Extension) (Section 6.5.17) will overwrite any properties set by calling set_builtin_transport_property().
Table 15.2 Properties for the Builtin UDPv4 Transport
Property Name |
|
|
(prefix with |
Property Value Description |
|
‘dds.transport.UDPv4.builtin.’) |
|
|
|
|
|
|
|
|
|
Number of bits in a |
|
|
be between 0 and 128. |
|
parent.address_bit_count |
For example, for an address range of |
|
|
be set to 8. For the range of addresses used by IPv4 (4 bytes), it should be |
|
|
set to 32. |
|
|
|
|
|
A bitmap that defines various properties of the transport to the Connext |
|
|
core. |
|
parent.properties_bitmap |
Currently, the only property supported is whether or not the transport |
|
|
plugin will always loan a buffer when Connext tries to receive a message |
|
|
using the plugin. This is in support of a |
|
|
|
|
|
Specifies the maximum number of buffers that Connext can pass to the |
|
|
send() method of a transport plugin. |
|
|
The transport plugin send() API supports a |
|
|
the send() call can take several discontiguous buffers, assemble and send |
|
|
them in a single message. This enables Connext to send a message from |
|
|
parts obtained from different sources without first having to copy the parts |
|
|
into a single contiguous buffer. |
|
parent. |
However, most transports that support a |
|
gather_send_buffer_count_max |
upper limit on the number of buffers that can be gathered and sent. Setting |
|
|
this value will prevent Connext from trying to gather too many buffers into |
|
|
a send call for the transport plugin. |
|
|
Connext requires all |
|
|
send of least a minimum number of buffers. This minimum number is |
|
|
NDDS_TRANSPORT_PROPERTY_GATHER_SEND_BUFFER_COUNT_MIN. |
|
|
See Setting the Maximum |
|
|
||
|
|
|
|
The maximum size of a message in bytes that can be sent or received by |
|
|
the transport plugin. |
|
parent.message_size_max |
This value must be set before the transport plugin is registered, so that |
|
Connext can properly use the plugin. |
||
|
||
|
If you set this higher than the default, then the DomainParticipant’s |
|
|
ReceiverPoolQosPolicy’s buffer_size should also be changed. |
|
|
|
|
|
A list of strings, each identifying a range of interface addresses or an |
|
|
interface name. Interfaces must be specified as |
|
|
with each comma delimiting an interface. |
|
|
For example, the following are acceptable strings: |
|
|
192.168.1.1 |
|
|
192.168.1.* |
|
|
192.168.* |
|
|
192.* |
|
parent.allow_interfaces_list |
ether0 |
|
|
If the list is |
|
|
parent.deny_interfaces_list list. The DomainParticipant will use the |
|
|
resulting list of interfaces to inform its remote participant(s) about which |
|
|
unicast addresses may be used to contact the DomainParticipant. |
|
|
The resulting list restricts reception to a particular set of interfaces for |
|
|
unicast UDP. Multicast output will still be sent and may be received over |
|
|
the interfaces in the list (if multicast is supported on the platform). |
|
|
You must manage the memory of the list. The memory may be freed after |
|
|
the DomainParticipant is deleted. |
|
|
|
Table 15.2 Properties for the Builtin UDPv4 Transport
Property Name |
|
|
(prefix with |
Property Value Description |
|
‘dds.transport.UDPv4.builtin.’) |
|
|
|
|
|
|
|
|
|
A list of strings, each identifying a range of interface addresses or an |
|
|
interface name. If the list is |
|
|
Interfaces must be specified as |
|
|
comma delimiting an interface. |
|
|
For example, the following are acceptable strings: |
|
|
192.168.1.1 |
|
|
192.168.1.* |
|
|
192.168.* |
|
parent.deny_interfaces_list |
192.* |
|
|
ether0 |
|
|
This "black" list is applied after the parent.allow_interfaces_list list and |
|
|
filters out the interfaces that should not be used for receiving data. |
|
|
The resulting list restricts reception to a particular set of interfaces for |
|
|
unicast UDP. Multicast output will still be sent and may be received over |
|
|
the interfaces in the list (if multicast is supported on the platform). |
|
|
You must manage the memory of the list. The memory may be freed after |
|
|
the DomainParticipant is deleted. |
|
|
|
|
|
A list of strings, each identifying a range of interface addresses or an |
|
|
interface name. If the list is |
|
|
these interfaces. If the list is empty, allow the use of all the allowed |
|
|
interfaces. |
|
|
Interfaces must be specified as |
|
|
comma delimiting an interface. |
|
|
This list |
|
parent. |
applying the parent.allow_interfaces_list "white" list and the |
|
allow_multicast_interfaces_list |
parent.deny_interfaces_list "black" list. From that resulting list, parent. |
|
|
deny_multicast_interfaces_list is applied. Multicast output will be sent |
|
|
and may be received over the interfaces in the resulting list (if multicast is |
|
|
supported on the platform). |
|
|
If this list is empty, all the allowed interfaces may potentially be used for |
|
|
multicast. |
|
|
You must manage the memory of the list. The memory may be freed after |
|
|
the DomainParticipant is deleted. |
|
|
|
|
|
A list of strings, each identifying a range of interface addresses or an |
|
|
interface name. If the list is |
|
|
multicast. |
|
|
Interfaces should be specified as |
|
parent. |
comma delimiting an interface. |
|
This "black" list is applied after the parent. allow_multicast_interfaces_list |
||
deny_multicast_interfaces_list |
||
list and filters out the interfaces that should not be used for multicast. The |
||
|
||
|
final resulting list will be those interfaces |
|
|
will be used for multicast sends. |
|
|
You must manage the memory of the list. The memory may be freed after |
|
|
the DomainParticipant is deleted. |
|
|
|
Table 15.2 Properties for the Builtin UDPv4 Transport
Property Name |
|
|
|
(prefix with |
|
Property Value Description |
|
‘dds.transport.UDPv4.builtin.’) |
|
|
|
|
|
||
|
|
||
|
Size in bytes of the send buffer of a socket used for sending. On most |
||
|
operating systems, setsockopt() will be called to set the SENDBUF to the |
||
|
value of this parameter. |
||
|
This value must be greater than or equal to the property, |
||
send_socket_buffer_size |
|||
|
The maximum value is operating |
||
|
If |
NDDS_TRANSPORT_UDPV4_SOCKET_BUFFER_SIZE_OS_DEFAULT, |
|
|
then setsockopt() (or equivalent) will not be called to size the send buffer |
||
|
of the socket. |
||
|
|
||
|
Size in bytes of the receive buffer of a socket used for receiving. |
||
|
On most operating systems, setsockopt() will be called to set the |
||
|
RECVBUF to the value of this parameter. |
||
|
This value must be greater than or equal to the property, |
||
recv_socket_buffer_size |
parent.message_size_max. The maximum value is operating system- |
||
dependent. |
|||
|
|||
|
Default: NDDS_TRANSPORT_UDPV4_MESSAGE_SIZE_MAX_DEFAULT. |
||
|
If NDDS_TRANSPORT_UDPV4_SOCKET_BUFFER_SIZE_OS_DEFAULT, then |
||
|
setsockopt() (or equivalent) will not be called to size the receive buffer of |
||
|
the socket. |
||
|
|
||
|
Allows the transport plugin to use unicast UDP for sending and receiving. |
||
|
By default, it will be turned on. Also by default, it will use all the allowed |
||
unicast_enabled |
network interfaces that it finds up and running when the plugin is |
||
|
instanced. |
||
|
Can be 1 (enabled) or 0 (disabled). |
||
|
|
||
|
Allows the transport plugin to use multicast for sending and receiving. |
||
|
You can turn multicast on or off for this plugin. The default is that |
||
multicast_enabled |
multicast is on and the plugin will use the all network interfaces allowed |
||
|
for multicast that it finds up and running when the plugin is instanced. |
||
|
Can be 1 (enabled) or 0 (disabled). |
||
|
|
||
|
Value for the |
||
multicast_ttl |
plugin. This is used to set the TTL of multicast packets sent by this |
||
|
transport plugin. |
||
|
|
||
|
Prevents the transport plugin from putting multicast packets onto the |
||
|
loopback interface. |
||
|
If disabled, then when sending multicast packets, do not put a copy on the |
||
|
loopback interface. This will prevent other applications on the same node |
||
multicast_loopback_disabled |
(including itself) from receiving those packets. |
||
This is set to 0 by default. So multicast loopback is enabled. Turning off |
|||
|
|||
|
multicast loopback (set to 1) may result in minor performance gains when |
||
|
using multicast. |
||
|
Note: Windows CE does not support multicast loopback. This field is |
||
|
ignored for Windows CE targets. |
||
|
|
|
|
Table 15.2 Properties for the Builtin UDPv4 Transport
Property Name |
|
|
|
|
|
|
|
(prefix with |
|
Property Value Description |
|
|
|||
‘dds.transport.UDPv4.builtin.’) |
|
|
|
|
|
|
|
|
|
||||||
|
|
||||||
|
Prevents the transport plugin from using the IP loopback interface. Three |
||||||
|
values are allowed: |
|
|
|
|
||
|
0: Forces local traffic to be sent over loopback, even if a more efficient |
||||||
|
transport (such as shared memory) is installed (in which case traffic will be |
||||||
|
sent over both transports). |
|
|
|
|
||
ignore_loopback_interface |
1: Disables local traffic via this plugin. The IP loopback interface will not |
||||||
be used, even if no NICs are discovered. This is useful when you want |
|||||||
|
applications running on the same node to use a more efficient transport |
||||||
|
(such as shared memory) instead of the IP loopback. |
|
|
||||
|
|||||||
|
shared memory transport plugin is available for local traffic, the effective |
||||||
|
value is 1 (i.e., disable UPV4 local traffic). Otherwise, the effective value is |
||||||
|
0, i.e., use UDPv4 for local traffic also. |
|
|
|
|||
|
|
||||||
|
This property is only supported on Windows platforms with statically |
||||||
|
configused IP addresses. |
|
|
|
|
||
|
It allows/disallows the use of interfaces that are not reported as UP (by the |
||||||
|
operating system) in the UDPv4 transport. Two values are allowed: |
||||||
|
0: Allow interfaces that are reported as DOWN. |
|
|
|
|||
|
Setting this value to 0 supports communication scenarios in which |
||||||
|
interfaces are enabled after the participant is created. Once the interfaces |
||||||
ignore_nonup_interfaces |
are enabled, discovery will not occur until the participant sends the next |
||||||
periodic |
announcement |
(controlled |
by |
the |
parameter |
||
|
|||||||
|
participant_qos.discovery_config.participant_liveliness_ |
|
|||||
|
assert_period). |
|
|
|
|
||
|
To reduce discovery time, you may want to decrease the value of |
||||||
|
participant_liveliness_assert_period. |
|
|
|
|||
|
For the above scenario, there is one caveat: |
||||||
|
static IP assigned. |
|
|
|
|
||
|
1 (default): Do not allow interfaces that are reported as DOWN. |
|
|||||
|
|
||||||
|
If ignore_nonup_interfaces is 0, the UDPv4 transport creates a new thread |
||||||
interface_poll_period |
to query the status of the interfaces. The interface_poll_period specifies |
||||||
the polling period in milliseconds for performing this query. |
|
||||||
|
|
||||||
|
This property’s value is ignored if ignore_nonup_interfaces is 1. |
|
|||||
|
|
||||||
|
Controls whether or not to reuse receive resources. Setting this to 0 |
||||||
reuse_multicast_receive_resource |
(FALSE) prevents multicast crosstalk by uniquely configuring a port and |
||||||
creating a receive thread for each multicast group address. |
|
||||||
|
|
||||||
|
Affects Linux systems only; ignored for |
|
|||||
|
|
|
|
|
|
|
|

Table 15.2 Properties for the Builtin UDPv4 Transport
Property Name
(prefix with Property Value Description ‘dds.transport.UDPv4.builtin.’)
|
Prevents the transport plugin from using a network interface that is not |
|||
|
reported as RUNNING by the operating system. |
|
|
|
|
The transport checks the flags reported by the operating system for each |
|||
|
network interface upon initialization. An interface which is not reported as |
|||
|
UP will not be used. This property allows the same check to be extended to |
|||
|
the IFF_RUNNING flag implemented by some operating systems. The |
|||
|
RUNNING flag is defined to mean that "all resources are allocated", and |
|||
ignore_nonrunning_interfaces |
may be off if there is no link detected, e.g., the network cable is unplugged. |
|||
Two values are allowed: |
|
|
||
|
|
|
||
|
0: Do not check the RUNNING flag when enumerating interfaces, just |
|||
|
make sure the interface is UP. |
|
|
|
|
1: Check the flag when enumerating interfaces, and ignore those that are |
|||
|
not reported as RUNNING. This can be used on some operating systems |
|||
|
to cause the transport to ignore interfaces that are enabled but not |
|||
|
connected to the network. |
|
|
|
|
|
|
|
|
|
Prevents the transport plugin from doing a zero copy. |
|
|
|
|
By default, this plugin will use the zero copy on OSs that offer it. While |
|||
|
this is good for performance, it may sometime tax the OS resources in a |
|||
|
manner that cannot be overcome by the application. |
|
|
|
|
The best example is if the hardware/device driver lends the buffer to the |
|||
no_zero_copy |
application itself. If the application does not return the loaned buffers soon |
|||
enough, the node may error or malfunction. In case you cannot |
||||
|
||||
|
reconfigure the hardware, device driver, or the OS to allow the |
|||
|
feature to work for your application, you may have no choice but to turn |
|||
|
off |
|
|
|
|
By default this is set to 0, so Connext will use the |
|||
|
by the OS. |
|
|
|
|
|
|||
|
Controls the blocking behavior of send sockets. CHANGING THIS |
|||
|
FROM THE DEFAULT CAN CAUSE SIGNIFICANT PERFORMANCE |
|||
|
PROBLEMS. Currently two values are defined: |
|
|
|
send_blocking |
NDDS_TRANSPORT_UDPV4_BLOCKING_ALWAYS: |
Sockets |
are |
|
blocking (default socket options for Operating System). |
|
|
||
|
|
|
||
|
NDDS_TRANSPORT_UDPV4_BLOCKING_NEVER: Sockets are modified |
|||
|
to make them |
|||
|
may cause significant performance problems. |
|
|
|
|
|
|||
|
Mask for the transport priority field. This is used in conjunction with |
|||
|
transport_priority_mapping_low and transport_priority_mapping_high |
|||
|
to define the mapping from the TRANSPORT_PRIORITY QosPolicy |
|||
|
(Section 6.5.21) to the IPv4 TOS field. Defines a contiguous region of bits in |
|||
|
the |
|||
transport_priority_mask |
IPv4 TOS field on an outgoing socket. |
|
|
|
|
For example, the value 0x0000ff00 causes bits |
|||
|
mapping. The value will be scaled from the mask range (0x0000 - 0xff00 in |
|||
|
this case) to the range specified by low and high. |
|
|
|
|
If the mask is set to zero, then the transport will not set IPv4 TOS for send |
|||
|
sockets. |
|
|
|
Table 15.2 Properties for the Builtin UDPv4 Transport
|
Property Name |
|
|
|
(prefix with |
Property Value Description |
|
|
‘dds.transport.UDPv4.builtin.’) |
|
|
|
|
|
|
|
|
|
|
|
transport_priority_mapping_low |
Sets the low and high values of the output range to IPv4 TOS. |
|
|
|
These values are used in conjunction with transport_priority_mask to |
|
|
|
|
|
|
|
define the mapping from the TRANSPORT_PRIORITY QosPolicy (Section |
|
|
transport_priority_mapping_high |
6.5.21) to the IPv4 TOS field. Defines the low and high values of the output |
|
|
range for scaling. |
|
|
|
|
|
|
|
|
Note that IPv4 TOS is generally an |
|
|
|
|
|
|
|
Controls whether or not to reuse receive resources. Setting this to 0 |
|
|
reuse_multicast_receive_resource |
(FALSE) prevents multicast crosstalk by uniquely configuring a port and |
|
|
creating a receive thread for each multicast group address. |
|
|
|
|
|
|
|
|
Affects Linux systems only; ignored for |
|
|
|
|
|
|
|
Maximum size in bytes of protocol overhead, including headers. |
|
|
|
This value is the maximum size, in bytes, of |
|
|
|
Normally, the overhead accounts for UDP and IP headers. The default |
|
|
protocol_overhead_max |
value is set to accommodate the most common UDP/IP header size. |
|
|
Note that when parent.message_size_max plus this overhead is larger than |
|
|
|
|
|
|
|
|
the UDPv4 maximum message size (65535 bytes), the middleware will |
|
|
|
automatically reduce the effective message_size_max to 65535 minus this |
|
|
|
overhead. |
|
|
|
|
|
Table 15.3 Properties for Builtin UDPv6 Transport |
|||
|
|
|
|
|
Property Name (prefix with |
Description |
|
|
‘dds.transport.UDPv6.builtin.’) |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Number of bits in a |
|
|
|
be between 0 and 128. |
|
|
parent.address_bit_count |
For example, for an address range of |
|
|
|
be set to 8. For the range of addresses used by IPv4 (4 bytes), it should be set |
|
|
|
to 32. |
|
|
|
|
|
|
|
A bitmap that defines various properties of the transport to the Connext |
|
|
|
core. |
|
|
parent.properties_bitmap |
Currently, the only property supported is whether or not the transport |
|
|
|
plugin will always loan a buffer when Connext tries to receive a message |
|
|
|
using the plugin. This is in support of a |
|
|
|
|
|
|
|
Specifies the maximum number of buffers that Connext can pass to the |
|
|
|
send() method of a transport plugin. |
|
|
|
The transport plugin send() API supports a |
|
|
|
send() call can take several discontiguous buffers, assemble and send them |
|
|
|
in a single message. This enables Connext to send a message from parts |
|
|
|
obtained from different sources without first having to copy the parts into a |
|
|
parent.gather_send_buffer_ |
single contiguous buffer. |
|
|
count_max |
However, most transports that support a |
|
|
|
upper limit on the number of buffers that can be gathered and sent. Setting |
|
|
|
this value will prevent Connext from trying to gather too many buffers into a |
|
|
|
send call for the transport plugin. |
|
|
|
Connext requires all |
|
|
|
send of least a minimum number of buffers. This minimum number is |
|
|
|
NDDS_TRANSPORT_PROPERTY_GATHER_SEND_BUFFER_COUNT_MIN. |
|
|
|
|
|
Table 15.3 Properties for Builtin UDPv6 Transport
Property Name (prefix with |
|
|
Description |
|
|
|
||
‘dds.transport.UDPv6.builtin.’) |
|
|
|
|
|
|||
|
|
|
|
|
|
|
||
|
|
|||||||
|
|
|||||||
|
The maximum size of a message in bytes that can be sent or received by the |
|||||||
|
transport plugin. |
|
|
|
|
|
||
|
This value must be set before the transport plugin is registered, so that |
|||||||
parent.message_size_max |
Connext can properly use the plugin. |
|
|
|
|
|||
|
If you set this higher than the default, then the DomainParticipant’s |
|||||||
|
ReceiverPoolQosPolicy’s buffer_size should also be changed. |
|
||||||
|
|
|
|
|
|
|||
|
|
|||||||
|
A list of strings, each identifying a range of interface addresses or an |
|||||||
|
interface name. |
|
|
|
|
|
||
|
Interfaces must be specified as |
|||||||
|
delimiting an interface. See “Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ |
|||||||
|
|
|
|
|||||
|
If the list is |
|||||||
parent.allow_interfaces_list |
parent.deny_interfaces_list list. The DomainParticipant will use the resulting |
|||||||
list of interfaces to inform its remote participant(s) about which unicast |
||||||||
|
||||||||
|
addresses may be used to contact the DomainParticipant. |
|
|
|||||
|
The resulting list restricts reception to a particular set of interfaces for unicast |
|||||||
|
UDP. Multicast output will still be sent and may be received over the |
|||||||
|
interfaces in the list (if multicast is supported on the platform). |
|
||||||
|
You must manage the memory of the list. The memory may be freed after |
|||||||
|
the DomainParticipant is deleted. |
|
|
|
|
|||
|
|
|||||||
|
A list of strings, each identifying a range of interface addresses or an |
|||||||
|
interface name. If the list is |
|||||||
|
Interfaces must be specified as |
|||||||
|
delimiting an interface. See “Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ |
|||||||
|
|
|
|
|||||
parent.deny_interfaces_list |
This |
"black" list is applied |
after the |
list and |
||||
filters out the interfaces that should not be used. |
|
|
|
|||||
|
|
|
|
|||||
|
The resulting list restricts reception to a particular set of interfaces for unicast |
|||||||
|
UDP. Multicast output will still be sent and may be received over the |
|||||||
|
interfaces in the list (if multicast is supported on the platform). |
|
||||||
|
You must manage the memory of the list. The memory may be freed after |
|||||||
|
the DomainParticipant is deleted. |
|
|
|
|
|||
|
|
|||||||
|
A list of strings, each identifying a range of interface addresses or an |
|||||||
|
interface name. If the list is |
|||||||
|
interfaces; otherwise allow the use of all the allowed interfaces. |
|
||||||
|
Interfaces must be specified as |
|||||||
|
delimiting an interface. See “Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ |
|||||||
|
|
|
|
|||||
|
This |
list |
||||||
parent. |
applying the parent.allow_interfaces_list "white" list and the |
|||||||
allow_multicast_interfaces_list |
"black" |
list. |
Finally, |
the |
||||
|
deny_multicast_interfaces_list is applied. Multicast output will be sent and |
|||||||
|
may be received over the interfaces in the resulting list (if multicast is |
|||||||
|
supported on the platform). |
|
|
|
|
|
||
|
If this list is empty, all the allowed interfaces may potentially be used for |
|||||||
|
multicast. |
|
|
|
|
|
||
|
You must manage the memory of the list. The memory may be freed after |
|||||||
|
the DomainParticipant is deleted. |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
Table 15.3 Properties for Builtin UDPv6 Transport
Property Name (prefix with |
|
Description |
|
‘dds.transport.UDPv6.builtin.’) |
|
||
|
|
||
|
|
||
|
|
||
|
A list of strings, each identifying a range of interface addresses or an |
||
|
interface name. If the list is |
||
|
multicast. |
||
|
Interfaces must be specified as |
||
|
delimiting an interface. See “Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ |
||
parent. |
|||
deny_multicast_interfaces_list |
This "black" list is applied after the parent. allow_multicast_interfaces_list |
||
|
list and filters out the interfaces that should not be used for multicast. |
||
|
Multicast output will be sent and may be received over the interfaces in the |
||
|
resulting list (if multicast is supported on the platform). |
||
|
You must manage the memory of the list. The memory may be freed after |
||
|
the DomainParticipant is deleted. |
||
|
|
||
|
Size in bytes of the send buffer of a socket used for sending. |
||
|
On most operating systems, setsockopt() will be called to set the SENDBUF |
||
|
to the value of this parameter. |
||
send_socket_buffer_size |
This value must be greater than or equal to parent.message_size_max. The |
||
maximum value is operating |
|||
|
|||
|
If |
NDDS_TRANSPORT_UDPV6_SOCKET_BUFFER_SIZE_OS_DEFAULT, |
|
|
then setsockopt() (or equivalent) will not be called to size the send buffer of |
||
|
the socket. |
||
|
|
||
|
Size in bytes of the receive buffer of a socket used for receiving. |
||
|
On most operating systems, setsockopt() will be called to set the RECVBUF |
||
|
to the value of this parameter. |
||
recv_socket_buffer_size |
This value must be greater than or equal to parent.message_size_max. The |
||
maximum value is operating |
|||
|
|||
|
If |
||
|
then setsockopt() (or equivalent) will not be called to size the receive buffer |
||
|
of the socket. |
||
|
|
||
|
Allows the transport plugin to use unicast UDP for sending and receiving. |
||
|
By default, it will be turned on (1). Also by default, it will use all the |
||
unicast_enabled |
allowed network interfaces that it finds up and running when the plugin is |
||
|
instanced. |
||
|
Can be 1 (enabled) or 0 (disabled). |
||
|
|
||
|
Allows the transport plugin to use multicast for sending and receiving. |
||
|
You can turn multicast UDP on or off for this plugin. By default, it will be |
||
multicast_enabled |
turned on (1). Also by default, it will use the all network interfaces allowed |
||
|
for multicast that it finds up and running when the plugin is instanced. |
||
|
Can be 1 (enabled) or 0 (disabled). |
||
|
|
||
|
Value for the |
||
multicast_ttl |
plugin. |
||
|
This is used to set the TTL of multicast packets sent by this transport plugin |
||
|
|
||
|
Prevents the transport plugin from putting multicast packets onto the |
||
|
loopback interface. |
||
|
If disabled, then when sending multicast packets, Connext will not put a |
||
|
copy on the loopback interface. This will prevent applications on the same |
||
multicast_loopback_disabled |
node (including itself) from receiving those packets. |
||
This is set to 0 by default, meaning multicast loopback is enabled. Disabling |
|||
|
|||
|
multicast loopback off (setting this value to 1) may result in minor |
||
|
performance gains when using multicast. |
||
|
Note: Windows CE does not support multicast loopback. This field is |
||
|
ignored for Windows CE targets. |
||
|
|
|
|

Table 15.3 Properties for Builtin UDPv6 Transport
Property Name (prefix with
Description
‘dds.transport.UDPv6.builtin.’)
|
Prevents the transport plugin from using the IP loopback interface. Three |
|
|
values are allowed: |
|
|
0: Enable local traffic via this plugin. This plugin will only use and report |
|
|
the IP loopback interface if there are no other network interfaces (NICs) up |
|
|
on the system. |
|
ignore_loopback_interface |
1: Disable local traffic via this plugin. Do not use the IP loopback interface |
|
even if no NICs are discovered. This is useful when you want applications |
||
|
running on the same node to use a more efficient plugin like Shared |
|
|
Memory instead of the IP loopback. |
|
|
||
|
memory transport plugin is available for local traffic, the effective value is 1 |
|
|
(i.e., disable UDPv4 local traffic). Otherwise, the effective value is 0, i.e., use |
|
|
UDPv4 for local traffic also. |
|
|
|
|
|
Prevents the transport plugin from using a network interface that is not |
|
|
reported as RUNNING by the operating system. |
|
|
The transport checks the flags reported by the operating system for each |
|
|
network interface upon initialization. An interface which is not reported as |
|
|
UP will not be used. This property allows the same check to be extended to |
|
|
the IFF_RUNNING flag implemented by some operating systems. The |
|
|
RUNNING flag is defined to mean that "all resources are allocated", and |
|
ignore_nonrunning_interfaces |
may be off if there is no link detected, e.g., the network cable is unplugged. |
|
|
Two values are allowed: |
|
|
0: Do not check the RUNNING flag when enumerating interfaces, just make |
|
|
sure the interface is UP. |
|
|
1: Check the flag when enumerating interfaces, and ignore those that are not |
|
|
reported as RUNNING. This can be used on some operating systems to |
|
|
cause the transport to ignore interfaces that are enabled but not connected |
|
|
to the network. |
|
|
|
|
|
Prevents the transport plugin from doing a zero copy. |
|
|
By default, this plugin will use the zero copy on OSs that offer it. While this |
|
|
is good for performance, it may sometime tax the OS resources in a manner |
|
|
that cannot be overcome by the application. |
|
no_zero_copy |
The best example is if the hardware/device driver lends the buffer to the |
|
application itself. If the application does not return the loaned buffers soon |
||
|
enough, the node may error or malfunction. In case you cannot reconfigure |
|
|
the H/W, device driver, or the OS to allow the |
|
|
your application, you may have no choice but to turn off |
|
|
By default this is set to 0, so Connext will use the |
|
|
the OS. |
|
|
|
|
|
Controls the blocking behavior of send sockets. CHANGING THIS FROM |
|
|
THE DEFAULT CAN CAUSE SIGNIFICANT PERFORMANCE |
|
|
PROBLEMS. Currently two values are defined: |
|
send_blocking |
NDDS_TRANSPORT_UDPV4_BLOCKING_ALWAYS: Sockets are blocking |
|
(default socket options for Operating System). |
||
|
||
|
NDDS_TRANSPORT_UDPV4_BLOCKING_NEVER: Sockets are modified |
|
|
to make them |
|
|
may cause significant performance problems. |
|
|
|
|
|
Specifies whether the UDPv6 transport will process IPv4 addresses. |
|
enable_v4mapped |
Set this to 1 to turn on processing of IPv4 addresses. Note that this may |
|
make it incompatible with use of the UDPv4 transport within the same |
||
|
||
|
domain participant. |

Table 15.3 Properties for Builtin UDPv6 Transport
Property Name (prefix with
Description
‘dds.transport.UDPv6.builtin.’)
|
Sets a mask for use of transport priority field. |
|
If transport priority mapping is supported on the platforma, this mask is |
|
used in conjunction with transport_priority_mapping_low and |
|
transport_priority_mapping_high to define the mapping from the DDS |
|
transport priority TRANSPORT_PRIORITY QosPolicy (Section 6.5.21) to the |
|
IPv6 TCLASS field. |
transport_priority_mask |
Defines a contiguous region of bits in the |
|
is used to generate values for the IPv6 TCLASS field on an outgoing socket. |
|
For example, the value 0x0000ff00 causes bits |
|
mapping. The value will be scaled from the mask range (0x0000 - 0xff00 in |
|
this case) to the range specified by low and high. |
|
If the mask is set to zero, then the transport will not set IPv6 TCLASS for |
|
send sockets. |
|
|
transport_priority_mapping_low |
Sets the low and high values of the output range to IPv6 TCLASS. |
|
These values are used in conjunction with transport_priority_mask to |
|
|
transport_priority_mapping_high |
define the mapping from DDS transport priority to the IPv6 TCLASS field. |
Defines the low and high values of the output range for scaling. |
|
|
Note that IPv6 TCLASS is generally an |
a. Please refer to the Platform Notes to find out if the transport priority is supported on a specific platform.
Table 15.4 Properties for Builtin
Property Name |
|
(prefix with |
Property Value Description |
‘dds.transport.shmem.builtin.’) |
|
|
|
|
|
|
Number of bits in a |
|
be between 0 and 128. |
parent.address_bit_count |
For example, for an address range of |
|
be set to 8. For the range of addresses used by IPv4 (4 bytes), it should be |
|
set to 32. |
|
|
|
A bitmap that defines various properties of the transport to the Connext |
|
core. |
parent.properties_bitmap |
Currently, the only property supported is whether or not the transport |
|
plugin will always loan a buffer when Connext tries to receive a message |
|
using the plugin. This is in support of a |
|
|
|
Specifies the maximum number of buffers that Connext can pass to the |
|
send() method of a transport plugin. |
|
The transport plugin send() API supports a |
|
send() call can take several discontiguous buffers, assemble and send them |
|
in a single message. This enables Connext to send a message from parts |
|
obtained from different sources without first having to copy the parts into |
parent.gather_send_buffer_ |
a single contiguous buffer. |
count_max |
However, most transports that support a |
|
upper limit on the number of buffers that can be gathered and sent. Setting |
|
this value will prevent Connext from trying to gather too many buffers into |
|
a send call for the transport plugin. |
|
Connext requires all |
|
send of least a minimum number of buffers. This minimum is |
|
NDDS_TRANSPORT_PROPERTY_GATHER_SEND_BUFFER_COUNT_MIN. |
|
|
Table 15.4 Properties for Builtin
Property Name |
|
|
(prefix with |
Property Value Description |
|
‘dds.transport.shmem.builtin.’) |
|
|
|
|
|
|
|
|
|
The maximum size of a message in bytes that can be sent or received by the |
|
|
transport plugin. |
|
|
This value must be set before the transport plugin is registered, so that |
|
parent.message_size_max |
Connext can properly use the plugin. |
|
|
If you set this higher than the default, then the DomainParticipant’s |
|
|
ReceiverPoolQosPolicy’s buffer_size should also be changed. |
|
|
||
|
|
|
parent.allow_interfaces_list |
|
|
|
|
|
parent.deny_interfaces_list |
|
|
|
|
|
parent. |
Not applicable to the |
|
allow_multicast_interfaces_list |
|
|
|
|
|
parent. |
|
|
deny_multicast_interfaces_list |
|
|
|
|
|
|
Number of messages that can be buffered in the receive queue. This is the |
|
|
maximum number of messages that can be buffered in a RecvResource of |
|
|
the Transport Plugin. This does not guarantee that the |
|
received_message_count_max |
will actually be able to buffer received_message_count_max messages of |
|
|
the maximum size set in parent.message_size_max. |
|
|
The total number of bytes that can be buffered for a RecvResource is |
|
|
actually controlled by receive_buffer_size. |
|
|
|
|
|
The total number of bytes that can be buffered in the receive queue. |
|
|
This number controls how much memory is allocated by the plugin for the |
|
|
receive queue (on a per RecvResource basis). The actual number of bytes |
|
|
allocated is: |
|
|
size = receive_buffer_size + message_size_max + |
|
|
received_message_count_max * fixedOverhead |
|
|
where fixedOverhead is some small number of bytes used by the queue data |
|
|
structure. |
|
|
If receive_buffer_size < |
|
|
message_size_max * received_message_count_max, then the transport |
|
|
plugin will not be able to store received_message_count_max messages of |
|
|
size message_size_max. |
|
|
If receive_buffer_size > |
|
|
message_size_max * received_message_count_max, then there will be |
|
receive_buffer_size |
memory allocated that cannot be used by the plugin and thus wasted. |
|
To optimize memory usage, specify a receive queue size less than that |
||
|
||
|
required to hold the maximum number of messages which are all of the |
|
|
maximum size. |
|
|
In most situations, the average message size may be far less than the |
|
|
maximum message size. So for example, if the maximum message size is |
|
|
64K bytes, and you configure the plugin to buffer at least 10 messages, then |
|
|
640K bytes of memory would be needed if all messages were 64K bytes. |
|
|
Should this be desired, then receive_buffer_size should be set to 640K |
|
|
bytes. |
|
|
However, if the average message size is only 10K bytes, then you could set |
|
|
the receive_buffer_size to 100K bytes. This allows you to optimize the |
|
|
memory usage of the plugin for the average case and yet allow the plugin |
|
|
to handle the extreme case. |
|
|
The queue will always be able to hold 1 message of message_size_max |
|
|
bytes, regardless of the value of receive_buffer_size. |
|
|
|
15.6.1Notes Regarding Loopback and Shared Memory
By default, Connext uses shared memory to communicate with other DomainParticipants on the same node, and disables local traffic over the UDPv4 or UPDv6 loopback interface. Thus, by default, a Connext application with shared memory enabled will not communicate with other applications on the same node that don’t have shared memory enabled.
For example, suppose you have three Connext applications on the same node. Shared memory is enabled on Applications A and B, but disabled on Application C. In this scenario, A and B will communicate with each other, but they will not communicate with C.
You can change this behavior by setting the "ignore_loopback_interface" field of the UDPv4 transport properties to 0 on Applications A and B. This will force DomainParticipants with shared memory enabled to also communicate over UDPv4 or UDPv6 loopback (and thus find Application C without using shared memory). Alternatively, you can disable shared memory on A and B via the TransportBuiltinQosPolicy.
15.6.2Setting the Maximum
To minimize memory copies, Connext uses the "gather send" API that may be available on the transport.
Some operating systems limit the number of gather buffers that can be given to the
To match this limitation, Connext sets the UDPv4 and UDPv6 transport
❏On VxWorks 5.5 operating systems, gather_send_buffer_count_max can be set as high as 63.
❏On Windows and INTEGRITY operating systems, gather_send_buffer_count_max can be set as high as 128.
❏On most other operating systems, gather_send_buffer_count_max can be set as high as 16.
If you are using an OS that allows more than 16 gather buffers for a sendmsg() call, you may increase the UDPv4 or UDPv6 transport
For example, if your OS imposes a limit of 64 gather buffers, you may increase the gather_send_buffer_count_max up to 64. However, if your OS's
By changing gather_send_buffer_count_max, you can increase performance in the following situations:
❏When a DataWriter is sending multiple packets to a DataReader either because the DataReader is a
❏If your application has more than five or six DataWriters or DataReaders in a participant. (In this case, the change will make the discovery process more efficient.)
❏When using an asynchronous DataWriter, samples are sent asynchronously by a separate thread. Samples may not be sent immediately, but may be queued instead, depending on the settings of the associated FlowController. If multiple samples in the queue must be sent to the same destination, they will be coalesced into as few network packets as

possible. The number of samples that can be put in a single message is directly proportional to gather_send_buffer_count_max. Therefore, by maximizing gather_send_buffer_count_max, you can minimize the number of packets on the wire.
15.6.3Formatting Rules for IPv6 ‘Allow’ and ‘Deny’ Address Lists
This section describes how to format the strings in the properties that create “allow” and “deny” lists:
❏dds.transport.UDPv6.builtin.parent.allow_interfaces_list
❏dds.transport.UDPv6.builtin.parent.deny_interfaces_list
❏dds.transport.UDPv6.builtin.parent. allow_multicast_interfaces_list
❏dds.transport.UDPv6.builtin.parent. deny_multicast_interfaces_list
These properties may contain a list of strings, each identifying a range of interface addresses or an interface name. Interfaces should be specified as
The strings can be addresses and patterns in IPv6 notation. They are
They may contain a wildcard '*' and can expand up to 4 digits in a block. The wildcard must be either leading or trailing (cannot be in the middle of the string). Multiple wildcards can be specified in a single filter, but only one wildcard can be specified per block (between colons). Table 15.5 shows some examples.
Table 15.5 Examples of IPv6 Address Filters
Example Filter |
Equivalent Filters |
Matches |
|
|
|
|
|
|
*:*:*:*:*:*:*:* |
|
Any IPv6 interface |
|
|
|
FE80::*:* |
fe80::*:*, |
|
|
|
|
|
Fe80:0:0::*:* |
|
|
|
|
|
Fe80:0:0:0:0:0:*:* |
FE80:0000:0000:0000:0000:0000:xxxx:xxxx |
|
|
|
FE80:aBC::202:2*:*:*2 |
|
FE80:0ABC:0000:0000:0202:2xxx:xxxx:xxx2 |
|
|
|
15.7Installing Additional Builtin Transport Plugins with register_transport()
After you create an instance of a transport plugin (see Section 15.4) , you have to register it.
The builtin transports (UDPv4, UDPv6, and Shared Memory) are implicitly registered by default (if they are enabled via the TRANSPORT_BUILTIN QosPolicy (DDS Extension) (Section 8.5.7)). Therefore, you only need to explicitly register a builtin transport if you want an extra instance of it (suppose you want two UDPv4 transports, one with special settings).
The register_transport() operation registers a transport plugin for use with a DomainParticipant and assigns it a network address. (Note: this operation is only available in the APIs other than Java or .NET. If you are using Java or .NET, use the Property QosPolicy to install additional transport plugins.)
NDDS_Transport_Handle_t NDDSTransportSupport::register_transport (DDSDomainParticipant * participant_in,
NDDS_Transport_Plugin * transport_in,
const DDS_StringSeq & aliases_in,
const NDDS_Transport_Address_t & network_address_in)
participant_in A
transport_in A
DomainParticipant.
aliases_in A
network_address_in The network address at which to register this transport plugin. The least significant transport_in.property.address_bit_count will be truncated. The remaining bits are the network address of the transport plugin. See Transport Network Addresses (Section 15.7.3).
Note: You must ensure that the transport plugin instance is only used by one DomainParticipant at a time. See Section 15.7.1.
Upon success, a valid
Note that a transport plugin's class name is automatically registered as an implicit alias for the plugin. Thus, a class name can be used to refer to all the transport plugin instances of that class.
The C and C++ APIs also have a operation to retrieve a registered transport plugin, get_transport_plugin().
NDDS_Transport_Plugin* get_transport_plugin(
DDSDomainParticipant* participant_in, const char* alias_in);
15.7.1Transport Lifecycles
If you create and register a transport plugin with a DomainParticipant, you are responsible for deleting it by calling its destructor. Builtin transport plugins are automatically managed by Connext if they are implicitly registered through the TransportBuiltinQosPolicy.
A transport plugin instance cannot be registered with more than one DomainParticipant at a time. This requirement is necessary to guarantee the
Thus, if the same physical transport resources are to be used with multiple DomainParticipants in the same address space, the transport plugin should be written in such a way so that it can be instantiated multiple
15.7.2Transport Aliases
In order to use a transport plugin instance in a Connext application, it must be registered with a
DomainParticipant using the register_transport() operation (Section 15.7). register_transport() takes a pointer to the transport plugin instance, and in addition allows you to specify a sequence of "alias" strings to symbolically refer to the transport plugin. The same alias strings can be used to register more than one transport plugin.

Multiple transport plugins can be registered with a DomainParticipant. An alias symbolically refers to one or more transport plugins registered with the DomainParticipant.
A transport plugin's class name is automatically used as an implicit alias. It can be used to refer to all the transport plugin instance of that class.
You can use aliases to refer to transport plugins in order to specify:
❏Transport plugins to use for discovery (see enabled_transports in DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2)), and for DataWriters and DataReaders (see TRANSPORT_SELECTION QosPolicy (DDS Extension) (Section 6.5.22)).
❏Multicast addresses on which to receive discovery messages (see multicast_receive_addresses in DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2)), and the multicast addresses and ports on which to receive user data (DDS_DataReaderQos::multicast).
❏Unicast ports used for user data (see TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23)) on both DataWriters and DataReaders.
❏Transport plugins used to parse an address string in a locator.
A DomainParticipant (and its contained entities) will start using a transport plugin after the DomainParticipant is enabled (see Enabling Entities (Section 4.1.2)). An entity will use all the transport plugins that match the specified transport QoS policy. All transport plugins are treated uniformly, regardless of how they were created or registered; there is no notion of some transports being more "special" that others.
15.7.3Transport Network Addresses
The address bits not used by the transport plugin for its internal addressing constitute its network address bits.
In order for Connext to properly route the messages, each unicast interface in the domain must have a unique address.
You specify the network address when installing a transport plugin via the register_transport() operation (Section 15.7). Choose the network address for a transport plugin so that the resulting fully qualified
If two instances of a transport plugin are registered with a DomainParticipant, they need different network addresses so that their unicast interfaces will have unique, fully qualified
While it is possible to create multiple transports with the same network address (this can be useful for certain situations), this requires special entity configuration for most transports to avoid clashes in resource use (e.g., sockets for UDPv4 transport).
15.8Installing Additional Builtin Transport Plugins with PropertyQosPolicy
Similar to default builtin transport instances, additional builtin transport instances can also be configured through PROPERTY QosPolicy (DDS Extension) (Section 6.5.17).
To install additional instances of builtin transport, the Properties listed in Table 15.6 are required.
Table 15.6 Properties for Dynamically Loading and Registering Additional Builtin Transport Plugins
Property Name |
|
Description |
|
|
|
|
|
||||
|
|
||||
dds.transport.load_plugins |
|||||
|
specified. |
|
|
|
|
|
|
||||
|
Indicates the additional builtin transport instances to be installed, and must |
||||
|
be in one of the following form, where <STRING> can be any string other |
||||
|
than “builtin”: |
|
|
||
|
dds.transport.shmem.<STRING> |
|
|
||
<TRANSPORT_PREFIX> |
dds.transport.UDPv4.<STRING> |
|
|
||
|
dds.transport.UDPv6.<STRING> |
|
|
||
|
In the following examples in this table, <TRANSPORT_PREFIX> is used to |
||||
|
indicate one element of this string that is used as a prefix in the property |
||||
|
names for all the settings that are related to the plugin. |
|
|||
|
|
|
|
|
|
|
Optional. |
|
|
|
|
|
Aliases used to register the transport to the DomainParticipant. Refer to the |
||||
<TRANSPORT_PREFIX>. |
aliases_in |
parameter in register_transport() (see Installing |
|||
Builtin Transport Plugins with register_transport() (Section 15.7)). Aliases |
|||||
aliases |
|||||
should be specified as a comma separated string, with each comma |
|||||
|
|||||
|
delimiting an alias. If it is not specified, <TRANSPORT_PREFIX> is used as |
||||
|
the default alias for the plugin. |
|
|
||
|
|
|
|
|
|
|
Optional. |
|
|
|
|
|
Network address used to register the transport to the DomainParticipant. |
||||
<TRANSPORT_PREFIX>. |
Refer to |
network_address_in parameter in |
register_transport() (see |
||
network_address |
|||||
(Section 15.7)). If it is not specified, the network_address_out output |
|||||
|
|||||
|
parameter from NDDS_Transport_create_plugin is used. The default value |
||||
|
is a zeroed out network address. |
|
|
||
|
|
|
|
|
|
|
Optional. |
|
|
|
|
|
Property for creating the transport plugin. More than one |
||||
|
<TRANSPORT_PREFIX>.<property_name> can be specified. See Table 15.2 |
||||
<TRANSPORT_PREFIX>. |
on page |
||||
can be used to configure the additional builtin transport instances. The only |
|||||
<property_name> |
|||||
difference is that the property name will be prefixed by |
|||||
|
|||||
|
dds.transport.<builitn_transport_name>.<instance_name>, |
where |
|||
|
<instance_name> is configured through the dds.transport.load_plugins |
||||
|
property instead of dds.transport.<builtin_transport_name>.builtin. |
||||
|
|
|
|
|
|
15.9Other Transport Support Operations
15.9.1Adding a Send Route
By default, a transport plugin will send outgoing messages using the network address range at which the plugin was registered.
The add_send_route() operation allows you to control the routing of outgoing messages, so that a transport plugin will only send messages to certain ranges of destination addresses.
Before using this operation, the DomainParticipant to which the transport is registered must be disabled.
DDS_ReturnCode_t NDDSTransportSupport::add_send_route
(const NDDS_Transport_Handle_t & transport_handle_in, const NDDS_Transport_Address_t & address_range_in, DDS_Long address_range_bit_count_in)
transport_handle_in A valid
address_range_in The outgoing address range for which to use this transport plugin.
address_range_bit_count_in The number of most significant bits used to specify the address range.
It returns one of the standard return codes or DDS_RETCODE_PRECONDITION_NOT_MET.
The method can be called multiple times for a transport plugin, with different address ranges. You can set up a routing table to restrict the use of a transport plugin to send messages to selected addresses ranges.
Outgoing Address Range 1 |
Transport Plugin |
|
|
|
|
. |
|
. |
. |
. |
|
. |
|
. |
|
|
|
Outgoing Address Range K |
Transport Plugin |
|
|
|
|
15.9.2Adding a Receive Route
By default, a transport plugin will receive incoming messages using the network address range at which the plugin was registered.
The add_receive_route() operation allows you to configure a transport plugin so that it will only receive messages on certain ranges of addresses.
Before using this operation, the DomainParticipant to which the transport is registered must be disabled.
DDS_ReturnCode_t NDDSTransportSupport::add_receive_route (const NDDS_Transport_Handle_t & transport_handle_in,
const NDDS_Transport_Address_t & address_range_in, DDS_Long address_range_bit_count_in)
transport_handle_in A valid
address_range_in The incoming address range for which to use this transport plugin.
address_range_bit_count_in The number of most significant bits used to specify the address range.
It returns one of the standard return codes or DDS_RETCODE_PRECONDITION_NOT_MET.
The method can be called multiple times for a transport plugin, with different address ranges.
Transport Plugin |
<— |
Incoming Address Range 1 |
|
|
|
. |
|
. |
. |
<— |
. |
. |
|
. |
|
|
|
Transport Plugin |
<— |
Incoming Address Range M |
|
|
|
You can set up a routing table to restrict the use of a transport plugin to receive messages from selected ranges. For example, you may restrict a transport plugin to:
❏Receive messages from a certain multicast address range.
❏Receive messages only on certain unicast interfaces (when multiple unicast interfaces are available on the transport plugin).
15.9.3Looking Up a Transport Plugin
If you need to get the handle associated with a transport plugin that is registered with a
DomainParticipant, use the lookup_transport() operation.
NDDS_Transport_Handle_t NDDSTransportSupport::lookup_transport (DDSDomainParticipant * participant_in,
DDS_StringSeq & aliases_out, NDDS_Transport_Address_t & network_address_out, NDDS_Transport_Plugin * transport_in )
participant_in A
aliases_out A sequence of strings where the aliases used to refer to the transport plugin symbolically will be returned. NULL if not interested.
network_address_out The network address at which to register the transport plugin will be returned here. NULL if not interested.
transport_in A
DomainParticipant.
If successful, this operation returns a valid

Chapter 16
This chapter discusses how to use
Connext must discover and keep track of remote entities, such as new participants in the domain. This information may also be important to the application itself, which may want to react to this discovery or access it on demand. To support these needs, Connext provides
The discovery information is accessed just as if it is normal application data. This allows the application to know (either via listeners or by polling) when there are any changes in those values. Note that only entities that belong to a different DomainParticipant are being discovered and can be accessed through the
16.1Listeners for
❏The
❏
This approach prevents callbacks to the

16.2
To conserve memory,
Table 16.1 through Table 16.4 describe the
Table 16.1 Participant
Type |
Field |
Description |
|
|
|
||
|
|
|
|
||||
|
|
|
|
||||
DDS_BuiltinTopicKey |
key |
Key to distinguish the discovered DomainParticipant |
|
||||
|
|
|
|||||
|
|
Data that can be set when the related DomainParticipant is |
|||||
DDS_UserDataQosPolicy |
user_data |
created (via the USER_DATA QosPolicy (Section 6.5.25)) |
|||||
and that the application may use as it wishes (e.g., to |
|||||||
|
|
||||||
|
|
perform some security checking). |
|
|
|
||
|
|
|
|||||
|
|
Pairs of names/values to be stored with the |
|||||
DDS_PropertyQosPolicy |
property |
DomainParticipant. See PROPERTY QosPolicy |
|||||
Extension) (Section 6.5.17). The usage is |
strictly |
||||||
|
|
||||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
DDS_ProtocolVersion_t |
rtps_protocol_ |
Version number of the RTPS wire protocol used. |
|
|
|||
version |
|
|
|||||
|
|
|
|
|
|
||
|
|
|
|
||||
DDS_VendorId_t |
rtps_vendor_id |
ID of vendor implementing the RTPS wire protocol. |
|
||||
|
|
|
|
|
|
||
|
dds_builtin_ |
Bitmap set by the discovery plugins. |
|
|
|
||
DDS_UnsignedLong |
Each bit in this field indicates a |
||||||
endpoints |
|||||||
|
for discovery. |
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|||||
|
|
If the TransportUnicastQosPolicy is not specified when a |
|||||
|
|
DataWriter/DataReader is created, the unicast_locators in |
|||||
|
|
the corresponding Publication/Subscription |
|||||
|
default_unicast_ |
data will be empty. When |
the unicast_locators |
in |
the |
||
DDS_LocatorSeq |
Publication/SubscriptionBuiltinTopicData is |
empty, |
the |
||||
locators |
|||||||
|
default_unicast_locators in the corresponding Participant |
||||||
|
|
||||||
|
|
Builtin Topic Data is assumed. |
|
|
|
||
|
|
If default_unicast_locators is empty, it defaults to |
|||||
|
|
DomainParticipantQos.default_unicast. |
|
|
|
||
|
|
|
|
|
|
||
DDS_ProductVersion_t |
product_version |
The current |
version |
of |
|||
Connext. |
|
|
|
|
|||
|
|
|
|
|
|
||
|
|
|
|||||
|
|
Name and role_name assigned to the DomainParticipant. |
|||||
DDS_EntityNameQosPolicy |
participant_name |
||||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
Table 16.5 lists the QoS of the
data. These are provided for your reference only; they cannot be changed.
Note: The DDS_TopicBuiltinTopicData
Table 16.2 Publication
Type |
Field |
|
Description |
|
|
||
|
|
|
|||||
|
|
|
|||||
DDS_BuiltinTopicKey_t |
key |
Key to distinguish the discovered DataWriter |
|||||
|
|
|
|
||||
DDS_BuiltinTopicKey_t |
participant_key |
Key to distinguish the participant to |
which the |
||||
discovered DataWriter belongs |
|
|
|
||||
|
|
|
|
|
|||
|
|
|
|
|
|||
DDS_String |
topic_name |
Topic name of the discovered DataWriter |
|
|
|||
|
|
|
|
||||
DDS_String |
type_name |
Type name attached to the topic of the |
discovered |
||||
DataWriter |
|
|
|
|
|||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
DDS_DurabilityQosPolicy |
durability |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_DurabilityService- |
durability_service |
|
|
|
|
|
|
QosPolicy |
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
DDS_DeadlineQosPolicy |
deadline |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_DestinationOrder- |
destination_order |
|
|
|
|
|
|
QosPolicy |
QosPolicies of the discovered DataWriter |
|
|
||||
|
|
|
|||||
DDS_LatencyBudget- |
latency_budget |
|
|
|
|
|
|
QosPolicy |
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
DDS_LivelinessQosPolicy |
liveliness |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_ReliabilityQosPolicy |
reliability |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_LifespanQosPolicy |
lifespan |
|
|
|
|
|
|
|
|
|
|||||
|
|
Data that can be set when the DataWriter is created (via |
|||||
DDS_UserDataQosPolicy |
user_data |
the USER_DATA QosPolicy (Section 6.5.25)) and that |
|||||
|
|
the application may use as it wishes. |
|
|
|||
|
|
|
|
|
|
|
|
DDS_OwnershipQosPolicy |
ownership |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_OwnershipStrength- |
ownership_strength |
|
|
|
|
|
|
QosPolicy |
|
|
|
|
|
||
|
QosPolicies of the discovered DataWriter |
|
|
||||
|
|
|
|
||||
DDS_DestinationOrder- |
destination_order |
|
|
||||
|
|
|
|
|
|||
QosPolicy |
|
|
|
|
|
||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
DDS_PresentationQosPolicy |
presentation |
|
|
|
|
|
|
|
|
|
|||||
|
|
Name of the partition, set in the PARTITION |
|||||
DDS_PartitionQosPolicy |
partition |
QosPolicy (Section 6.4.5) for the publisher to which the |
|||||
|
|
discovered DataWriter belongs |
|
|
|
||
|
|
|
|||||
|
|
Data that can be set when the Topic (with which the |
|||||
DDS_TopicDataQosPolicy |
topic_data |
discovered DataWriter is associated) is created (via the |
|||||
TOPIC_DATA QosPolicy (Section 5.2.1)) and that the |
|||||||
|
|
||||||
|
|
application may use as it wishes. |
|
|
|||
|
|
|
|||||
|
|
Data that can be set when the Publisher to which the |
|||||
DDS_GroupDataQosPolicy |
group_data |
discovered DataWriter belongs is created |
(via the |
||||
GROUP_DATA QosPolicy (Section 6.4.4)) and that the |
|||||||
|
|
||||||
|
|
application may use as it wishes. |
|
|
|||
|
|
|
|
||||
DDS_TypeObject * |
type |
Describes the type of the remote DataReader. |
|
||||
See the API Reference HTML documentation. |
|||||||
|
|
||||||
|
|
|
|||||
|
|
Type code information about this Topic. See Using |
|||||
DDS_TypeCode * |
type_code |
||||||
|
|
|
|
|
|
||
|
|
|
|
|
|||
DDS_BuiltinTopicKey_t |
publisher_key |
The key of the |
Publisher to |
which the DataWriter |
|||
belongs. |
|
|
|
|
|||
|
|
|
|
|
|
||
|
|
|
|||||
|
|
Properties (pairs of names/values) assigned to the |
|||||
DDS_PropertyQosPolicy |
property |
corresponding |
DataWriter. |
Usage |
is |
strictly |
|
|
|||||||
|
|
|
|||||
|
|
|
|
||||
|
|
|
|
|
|
|
|
Table 16.2 Publication
|
Type |
Field |
|
|
|
Description |
|
|
|
||
|
|
|
|
|
|||||||
|
|
|
|
|
|||||||
|
|
|
|
If the TransportUnicastQosPolicy is not specified when |
|||||||
|
|
|
|
a DataWriter/DataReader is created, the unicast_locators |
|||||||
|
|
|
|
in the corresponding Publication/Subscription |
|||||||
|
DDS_LocatorSeq |
unicast_locators |
topic data will be empty. When the unicast_locators in |
||||||||
|
the |
Publication/SubscriptionBuiltinTopicData |
is |
||||||||
|
|
|
|
||||||||
|
|
|
|
empty, |
the |
default_unicast_locators |
in |
the |
|||
|
|
|
|
corresponding Participant Builtin Topic Data is |
|||||||
|
|
|
|
assumed. |
|
|
|
|
|
||
|
|
|
|
|
|||||||
|
|
|
|
Virtual GUID for the corresponding DataWriter. For |
|||||||
|
DDS_GUID_t |
virtual_guid |
more information, see Durability and Persistence |
||||||||
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_ProtocolVersion_t |
rtps_protocol_ |
Version number of the RTPS wire protocol in use. |
|
|||||||
|
version |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
DDS_VendorId_t |
rtps_vendor_id |
ID |
of |
the vendor implementing the |
RTPS |
wire |
||||
|
protocol. |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
DDS_Product_Version_t |
product_version |
value. For |
RTI, this is |
the |
current |
|||||
|
version of Connext. |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|||||||
|
|
|
|
When the MULTI_CHANNEL QosPolicy (DDS |
|||||||
|
|
|
|
Extension) (Section 6.5.14) is used on the discovered |
|||||||
|
|
|
|
DataWriter, the locator_filter contains the sequence of |
|||||||
|
|
|
|
LocatorFilters in that policy. |
|
|
|
|
|||
|
DDS_LocatorFilterQosPolicy |
locator_filter |
There is one LocatorFilter per DataWriter channel. A |
||||||||
|
|
|
|
channel is defined by a filter expression and a |
|||||||
|
|
|
|
sequence of multicast locators. |
|
|
|
||||
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||||
|
|
disable_positive_ |
Vendor |
specific parameter. Determines |
whether |
||||||
|
DDS_Boolean |
matching |
DataReaders |
send |
|
positive |
|||||
|
acks |
|
|||||||||
|
|
acknowledgements for reliability. |
|
|
|
||||||
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|||||||
|
|
|
|
Name and role_name assigned to the DataWriter. See |
|||||||
|
DDS_EntityNameQosPolicy |
publication_name |
|||||||||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
Table 16.3 Subscription |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Type |
Field |
|
|
|
|
Description |
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|||||
|
DDS_BuiltinTopicKey_t |
key |
|
Key to distinguish the discovered DataReader. |
|
|
|||||
|
|
|
|
|
|
|
|
|
|||
|
DDS_BuiltinTopicKey_t |
participant_key |
|
Key |
to |
distinguish the participant to |
which |
the |
|||
|
|
discovered DataReader belongs. |
|
|
|
||||||
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
||||
|
char * |
topic_name |
|
Topic name of the discovered DataReader. |
|
|
|
||||
|
|
|
|
|
|
|
|
||||
|
char * |
type_name |
|
Type |
name attached to the |
Topic of the |
discovered |
||||
|
|
DataReader. |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_DurabilityQosPolicy |
durability |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_DeadlineQosPolicy |
deadline |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_LatencyBudget- |
latency_budget |
|
|
|
|
|
|
|
|
|
|
QosPolicy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
QosPolicies of the discovered DataReader |
|
|
|
||||
|
DDS_LivelinessQosPolicy |
liveliness |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_ReliabilityQosPolicy |
reliability |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_OwnershipQosPolicy |
ownership |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DDS_ |
destination_order |
|
|
|
|
|
|
|
|
|
|
DestinationOrderQosPolicy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 16.3 Subscription
Type |
Field |
Description |
|
|
|
|
|
|
|
|
|
|
|
Data that can be set when the DataReader is created (via |
|
DDS_UserDataQosPolicy |
user_data |
the USER_DATA QosPolicy (Section 6.5.25)) and that |
|
|
|
the application may use as it wishes. |
|
|
|
|
|
DDS_ |
time_based_filter |
|
|
TimeBasedFilterQosPolicy |
QosPolicies of the discovered DataReader |
||
|
|||
DDS_PresentationQosPolicy |
presentation |
|
|
|
|
|
|
|
|
Name of the partition, set in the PARTITION QosPolicy |
|
DDS_PartitionQosPolicy |
partition |
(Section 6.4.5) for the Subscriber to which the discovered |
|
|
|
DataReader belongs. |
|
|
|
|
|
|
|
Data that can be set when the Topic to which the |
|
DDS_TopicDataQosPolicy |
topic_data |
discovered DataReader belongs is created (via the |
|
TOPIC_DATA QosPolicy (Section 5.2.1)) and that the |
|||
|
|
||
|
|
application may use as it wishes. |
|
|
|
|
|
|
|
Data that can be set when the Publisher to which the |
|
DDS_GroupDataQosPolicy |
group_data |
discovered DataReader belongs is created (via the |
|
GROUP_DATA QosPolicy (Section 6.4.4)) and that the |
|||
|
|
||
|
|
application may use as it wishes. |
|
|
|
|
|
DDS_TypeObject * |
type |
Describes the type of the remote DataReader. |
|
See the API Reference HTML documentation. |
|||
|
|
||
|
|
|
|
|
|
Indicates the |
|
|
|
remote DataReader. |
|
DDS_TypeConsistencyEnforc |
type_consistency |
||
ementQosPolicy |
QosPolicy (Section 7.6.6) and the Core Libraries and |
||
|
|||
|
|
Utilities Getting Started Guide Addendum for Extensible |
|
|
|
Types |
|
|
|
|
|
|
|
Type code information about this Topic. See Using |
|
DDS_TypeCode * |
type_code |
||
|
|
||
|
|
|
|
DDS_BuiltinTopicKey_t |
subscriber_key |
Key of the Subscriber to which the DataReader belongs. |
|
|
|
|
|
|
|
Properties (pairs of names/values) assigned to the |
|
DDS_PropertyQosPolicy |
property |
corresponding DataReader. Usage is strictly application- |
|
dependent. See PROPERTY QosPolicy (DDS Extension) |
|||
|
|
||
|
|
||
|
|
|
|
|
|
If the TransportUnicastQosPolicy is not specified when |
|
|
|
a DataWriter/DataReader is created, the unicast_locators |
|
|
|
in the corresponding Publication/Subscription builtin |
|
DDS_LocatorSeq |
unicast_locators |
topic data will be empty. When the unicast_locators in |
|
|
|
the Publication/SubscriptionBuiltinTopicData is empty, |
|
|
|
the default_unicast_locators in the corresponding |
|
|
|
Participant Builtin Topic Data is assumed. |
|
|
|
|
|
DDS_LocatorSeq |
multicast_locators |
Custom multicast locators that the endpoint can specify. |
|
|
|
|
|
DDS_ContentFilter- |
content_filter_ |
Provides all the required information to enable content |
|
Property_t |
property |
filtering on the writer side. |
|
|
|
|
|
|
|
Virtual GUID for the corresponding DataReader. For |
|
DDS_GUID_t |
virtual_guid |
more information, see Durability and Persistence Based |
|
|
|
||
|
|
|
|
DDS_ProtocolVersion_t |
rtps_protocol_ |
Version number of the RTPS wire protocol in use. |
|
version |
|||
|
|
||
|
|
|
|
DDS_VendorId_t |
rtps_vendor_id |
ID of the vendor implementing the RTPS wire protocol. |
|
|
|
|
|
DDS_Product_Version_t |
product_version |
||
sion of Connext. |
|||
|
|
||
|
|
|
Table 16.3 Subscription
Type |
Field |
Description |
|
|
|
|
|
|
|
|
|
|
disable_positive_ |
Vendor specific parameter. Determines whether match- |
|
DDS_Boolean |
ing DataReaders send positive acknowledgements for |
||
acks |
|||
|
reliability. |
||
|
|
||
|
|
|
|
|
|
Name and role_name assigned to the DataReader. See |
|
DDS_EntityNameQosPolicy |
subscription_name |
||
|
|
||
|
|
|
Table 16.4 Topic
|
Type |
|
Field |
Description |
|
|
|
|
|
|
DDS_BuiltinTopicKey_t |
key |
Key to distinguish the discovered Topic |
|
|
|
|
|
|
|
DDS_String |
|
name |
Topic name |
|
|
|
|
|
|
DDS_String |
|
type_name |
type name attached to the Topic |
|
|
|
|
|
|
DDS_DurabilityQosPolicy |
durability |
|
|
|
|
|
|
|
|
DDS_DurabilityServiceQosPolicy |
durability_service |
|
|
|
|
|
|
|
|
DDS_DeadlineQosPolicy |
deadline |
|
|
|
|
|
|
|
|
DDS_LatencyBudgetQosPolicy |
latency_budget |
|
|
|
|
|
|
|
|
DDS_LivelinessQosPolicy |
liveliness |
|
|
|
|
|
|
|
|
DDS_ReliabilityQosPolicy |
reliability |
|
|
|
|
|
|
QosPolicy of the discovered Topic |
|
DDS_TransportPriorityQosPolicy |
transport_priority |
||
|
|
|
|
|
|
DDS_LifespanQosPolicy |
lifespan |
|
|
|
|
|
|
|
|
DDS_DestinationOrderQosPolicy |
destination_ |
|
|
|
order |
|
||
|
|
|
|
|
|
DDS_HistoryQosPolicy |
history |
|
|
|
|
|
|
|
|
DDS_ResourceLimitsQosPolicy |
resource_limits |
|
|
|
|
|
|
|
|
DDS_OwnershipQosPolicy |
ownership |
|
|
|
|
|
|
|
|
|
|
|
Data that can be set when the Topic to which the dis- |
|
DDS_TopicDataQosPolicy |
topic_data |
covered DataReader belongs is created (via the |
|
|
TOPIC_DATA QosPolicy (Section 5.2.1)) and that |
|||
|
|
|
|
|
|
|
|
|
the application may use as it wishes. |
|
|
|
|
|
Table 16.5 QoS of |
|
|||
|
|
|
|
|
|
QosPolicy |
|
|
Value |
|
|
|
|
|
|
|
|
|
|
|
Deadline |
period = infinite |
|
|
|
|
|
||
|
DestinationOrder |
kind = BY_RECEPTION_TIMESTAMP_DESTINATIONORDER_QOS |
||
|
|
|
||
|
Durability |
kind = TRANSIENT_LOCAL_DURABILITY_QOS |
||
|
|
|
||
|
EntityFactory |
autoenable_created_entities = TRUE |
||
|
|
|
|
|
|
GroupData |
value = empty sequence |
|
|
|
|
|
||
|
History |
kind = KEEP_LAST_HISTORY_QOS |
||
|
depth = 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LatencyBudget |
duration = 0 |
|
|
|
|
|
||
|
Liveliness |
kind = AUTOMATIC_LIVELINESS_QOS |
||
|
lease_duration = infinite |
|
||
|
|
|
||
|
|
|
||
|
Ownership |
kind = SHARED_OWNERSHIP_QOS |
||
|
|
|
|
|
|
Ownership Strength |
value = 0 |
|
|
|
|
|
|
|
Table 16.5 QoS of
QosPolicy |
Value |
|
|
|
|
|
|
|
|
access_scope = TOPIC_PRESENTATION_QOS |
|
Presentation |
coherent_access = FALSE |
|
|
ordered_access = FALSE |
|
|
|
|
Partition |
name = empty sequence |
|
|
|
|
ReaderDataLifecycle |
autopurge_nowriter_samples_delay = infinite |
|
|
|
|
Reliability |
kind = RELIABLE_RELIABILITY_QOS |
|
max_blocking_time is irrelevant for the DataReader |
||
|
||
|
|
|
|
Depends on setting of DomainParticipantResourceLimitsQosPolicy and Discovery- |
|
|
ConfigQosPolicy in DomainParticipantQos: |
|
|
max_samples = domainParticipantQos.discovery_config. |
|
ResourceLimits |
[participant/publication/subscription]_reader_resource_limits.max_samples |
|
|
max_instances = domainParticipantQos.resource_limits. |
|
|
[remote_writer/reader/participant]_allocation.max_count |
|
|
max_samples_per_instance = 1 |
|
|
|
|
TimeBasedFilter |
minimum_separation = 0 |
|
|
|
|
TopicData |
value = empty sequence |
|
|
|
|
UserData |
value = empty sequence |
|
|
|
and therefore a DataReader for DDS_TopicBuiltinTopicData will not receive any data. Instead, DDS_TopicBuiltinTopicData data is included in the information carried by the
16.2.1LOCATOR_FILTER QoS Policy (DDS Extension)
The LocatorFilter QoS Policy is only applicable to the
Table 16.6 DDS_LocatorFilterQosPolicy
|
Type |
Field Name |
Description |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A sequence of locator filters, described in Table 16.7 on page |
|
|
DDS_LocatorFilterSeq |
locator_filters |
There is one locator filter per DataWriter channel. If the length of the |
|
|
|
|
sequence is zero, the DataWriter is not using |
|
|
|
|
|
|
|
|
|
Name of the filter class used to describe the locator filter expressions. |
|
|
char * |
filter_name |
The following two values are supported: |
|
|
DDS_SQLFILTER_NAME |
|
||
|
|
|
|
|
|
|
|
DDS_STRINGMATCHFILTER_NAME |
|
|
|
|
|
|
Table 16.7 DDS_LocatorFilter_t |
|
|
|
|
|
|
|
|
|
|
Type |
Field Name |
Description |
|
|
|
|
|
|
|
DDS_LocatorSeq |
locators |
A sequence of multicast address locators for the locator filter. See |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
A logical expression used to determine if the data will be published |
|
|
|
filter_express |
in the channel associated with this |
locator filter. See “SQL Filter |
|
char * |
|||
|
|
ion |
Expression Notation” on page |
|
|
|
|
||
|
|
|
sion syntax. |
|
|
|
|
|
|
Table 16.8 DDS_Locator_t
Type |
Field Name |
Description |
|
|
|
|
|
|
|
|
If the locator kind is DDS_LOCATOR_KIND_UDPv4a, the address |
|
|
contains an IPv4 address. The leading 12 octets of the address must |
|
|
be zero. The last 4 octets store the IPv4 address. |
DDS_Long |
kind |
If the locator kind is DDS_LOCATOR_KIND_UDPv6a, the address |
|
|
contains an IPv6 address. IPv6 addresses typically use a shorthand |
|
|
hexadecimal notation that maps |
|
|
address. |
|
|
|
DDS_Octet[16] |
address |
The locator address. |
|
|
|
DDS_UnsignedLong |
port |
The locator port number. |
|
|
|
a.In C#, the locator kinds for UDPv4 and UDPv6 addresses are Locator_t.LOCATOR_KIND_UDPv4 and Locator_t.LOCATOR_KIND_UDPv6.
16.3Accessing the
Getting the
// Lookup
// ... error
}
// Register listener to
new MyPublicationBuiltinTopicDataListener(); if
DDS_DATA_AVAILABLE_STATUS) != DDS_RETCODE_OK) {
// ... error
}
// enable domain participant
if
}
For example, you can call the DomainParticipant’s get_builtin_subscriber() operation, which will provide you with a
16.4Restricting
The ignore_participant() operation allows an application to ignore all communication from a specific DomainParticipant. Or for even finer control you can use the ignore_publication(), ignore_subscription(), and ignore_topic() operations. These operations are described below.
DDS_ReturnCode_t ignore_participant (const DDS_InstanceHandle_t &handle)
DDS_ReturnCode_t ignore_publication (const DDS_InstanceHandle_t &handle)
DDS_ReturnCode_t ignore_subscription (const DDS_InstanceHandle_t &handle) DDS_ReturnCode_t ignore_topic (const DDS_InstanceHandle_t &handle)
The entity to ignore is identified by the handle argument. It may be a local or remote entity. For ignore_publication(), the handle will be that of a local DataWriter or a discovered remote DataWriter. For ignore_subscription(), that handle will be that of a local DataReader or a discovered remote DataReader.
The safest approach for ignoring an entity is to call the ignore operation within the Listener callback of the
If the above is not possible and a remote entity is to be ignored after the communication channel has been established, the remote entity will still be removed from the database of the local application as if it never existed. However, since the remote application is not aware that the entity is being ignored, it may potentially be expecting to receive messages or continuing to send messages. Depending on the QoS of the remote entity, this may affect the behavior of the remote application and may potentially stop the remote application from communicating with other entities.
You can use this operation in conjunction with the ParticipantBuiltinTopicData to implement access control. You can pass application data associated with a DomainParticipant in the USER_DATA QosPolicy (Section 6.5.25). This application data is propagated as a field in the
Ignore operations, in conjunction with the
See also: Chapter 14: Discovery.
16.4.1Ignoring Specific Remote DomainParticipants
The ignore_participant() operation is used to instruct Connext to locally ignore a remote
DomainParticipant. It causes Connext to locally behave as if the remote DomainParticipant does not exist.
DDS_ReturnCode_t ignore_participant (const DDS_InstanceHandle_t & handle)
After invoking this operation, Connext will locally ignore any Topic, publication, or subscription that originates on that DomainParticipant. (If you only want to ignore specific publications or subscriptions, see Section 16.4.2 instead.) Figure 16.1, “Ignoring Participants,” on page
Caution: There is no way to reverse this operation. You can add to the peer list,
16.4.2Ignoring Publications and Subscriptions
You can instruct Connext to locally ignore a publication or subscription. A publication/ subscription is defined by the association of a Topic name, user data and partition set on the Publisher/Subscriber. After this call, any data written related to associated DataWriter/DataReader will be ignored.
The entity to ignore is identified by the handle argument. For ignore_publication(), the handle will be that of a DataWriter. For ignore_subscription(), that handle will be that of a DataReader.
Figure 16.1 Ignoring Participants
class MyParticipantBuiltinTopicDataListener : public DDSDataReaderListener {
public:
virtual void on_data_available(DDSDataReader *reader); // ......
};
void MyParticipantBuiltinTopicdataListener::on_data_available( DDSDataReader *reader) {
DDSParticipantBuiltinTopicDataDataReader *builtinTopicDataReader = DDSParticipantBuiltinTopicDataDataReader *) reader;
DDS_ParticipantBuiltinTopicDataSeq data_seq; DDS_SampleInfoSeq info_seq;
int = 0;
if
}
for (i = 0; i < data_seq.length(); ++i) { if (info_seq[i].valid_data) {
// check user_data for access control if (data_seq[i].user_data[0] != 0x9) {
if (
// ... error
}
}
}
}
if
// ... error
}
}
This operation can be used to ignore local and remote entities:
❏For local entities, you can obtain the handle argument by calling the get_instance_handle() operation for that particular entity.
❏For remote entities, you can obtain the handle argument from the DDS_SampleInfo structure retrieved when reading data samples available for the entity’s
DataReader.
DDS_ReturnCode_t ignore_publication (const DDS_InstanceHandle_t & handle) DDS_ReturnCode_t ignore_subscription (const DDS_InstanceHandle_t & handle)
Caution: There is no way to reverse these operations.
Figure 16.2, “Ignoring Publications,” on page
16.4.3Ignoring Topics
The ignore_topic() operation instructs Connext to locally ignore a Topic. This means it will locally ignore any publication or subscription to the Topic.
DDS_ReturnCode_t ignore_topic (const DDS_InstanceHandle_t & handle)
Caution: There is no way to reverse this operation.
Figure 16.2 Ignoring Publications
class MyPublicationBuiltinTopicDataListener : public DDSDataReaderL- istener {
public:
virtual void on_data_available(DDSDataReader *reader); // ......
};
void MyPublicationBuiltinTopicdataListener::on_data_available( DDSDataReader *reader) {
DDSPublicationBuiltinTopicDataReader *builtinTopicDataReader = (DDS_PublicationBuiltinTopicDataReader *)reader;
DDS_PublicationBuiltinTopicDataSeq data_seq; DDS_SampleInfoSeq info_seq;
int = 0;
if
!= DDS_RETCODE_OK) { // ... error
}
for (i = 0; i < data_seq.length(); ++i) { if (info_seq[i].valid_data) {
// check user_data for access control if (data_seq[i].user_data[0] != 0x9) {
if
!= DDS_RETCODE_OK) { // ... error
}
}
}
}
if
// ... error
}
}
If you know that your application will never publish or subscribe to data under certain topics, you can use this operation to save local resources.
The Topic to ignore is identified by the handle argument. This handle is the one that appears in the DDS_SampleInfo retrieved when reading the data samples from the
Chapter 17 Configuring QoS with XML
Connext entities are configured by means of QosPolicies. The QoS may be set programmatically in one of the following ways:
❏Directly when the entity is created as an additional argument to the create_<entity>() operation.
❏Directly via the set_qos() operation on the entity.
❏Indirectly as a default QoS on the factory for the entity (set_default_<entity>_qos() operations on Publisher, Subscriber, DomainParticipant, DomainParticipantFactory)
Entities can also be configured from an XML file or XML string. With this feature, you can change QoS configurations simply by changing the XML file or
❏Example XML File (Section 17.1)
❏How to Load
❏How to Use
❏XML File Syntax (Section 17.4)
❏Using Environment Variables in XML (Section 17.5)
❏XML String Syntax (Section 17.6)
❏How the XML is Validated (Section 17.7)
❏Configuring QoS with XML (Section 17.8)

17.1Example XML File
The QoS configuration of a Entity can be loaded from an XML file or string. Let's look at a very basic configuration file, just to get an idea of its contents. You will learn the meaning of each line as you read the rest of this chapter:
<?xml version="1.0"
<dds version = 5.0.0> <qos_library name="RTILibrary">
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history> </datawriter_qos>
<datawriter_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datawriter_qos> <datareader_qos>
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datareader_qos>
</qos_profile> </qos_library>
</dds>
See $NDDSHOME/resource/qos_profiles_5.0.x1/xml/NDDS_QOS_PROFILES.example.xml for another example; this file contains the default QoS values for all entity kinds.
17.2How to Load
If specified,
The following list presents the various approaches, listed by load order:
•$NDDSHOME/resource/qos_profiles_5.0.x/xml/NDDS_QOS_PROFILES.xml
This file is loaded automatically if it exists (not the default) and ignore_resource_profile in the PROFILE QosPolicy (DDS Extension) (Section 8.4.2) is FALSE (the default). NDDS_QOS_PROFILES.xml does not exist by default. However, NDDS_QOS_PROFILES.example.xml is shipped with the host bundle of
1.x stands for the version number of the current release.
the product; you can copy it to NDDS_QOS_PROFILES.xml and modify it for your own use. The file contains the default QoS values that will be used for all entity kinds. (First to be loaded)
•URL Groups in NDDS_QOS_PROFILES
URL groups (see URL Groups (Section 17.11)) separated by semicolons referenced by the environment variable NDDS_QOS_PROFILES are loaded automatically if they exist and ignore_environment_profile in PROFILE QosPolicy (DDS Extension) (Section 8.4.2) is FALSE (the default).
•<working directory>/USER_QOS_PROFILES.xml
This file is loaded automatically if it exists and ignore_user_profile in PROFILE QosPolicy (DDS Extension) (Section 8.4.2) is FALSE (the default).
•URL groups in url_profile
URL groups (see URL Groups (Section 17.11)) referenced by url_profile (in PROFILE QosPolicy (DDS Extension) (Section 8.4.2)) will be loaded automatically if specified.
•XML strings in string_profile
The sequence of XML strings referenced by string_profile (in PROFILE QosPolicy (DDS Extension) (Section 8.4.2)) will be loaded automatically if specified. (Last to be loaded)
You may use a combination of the above approaches.
The location of the XML documents (only files and strings are supported) is specified using URL (Uniform Resource Locator) format. For example:
❏File Specification: file:///usr/local/default_dds.xml
❏String Specification: str://"<dds><qos_library>…</qos_library></dds>"
If you omit the URL schema name, Connext will assume a file name. For example:
❏ File Specification: /usr/local/default_dds.xml
Duplicate QoS profiles are not allowed. Connext will report an error message in these scenarios. To overwrite a QoS profile, use QoS Profile Inheritance (Section 17.9.2).
17.2.1Loading, Reloading and Unloading Profiles
You do not have to explicitly call load_profiles(). QoS profiles are loaded when any of these DomainParticipantFactory operations are called:
❏create_participant() (see Section 8.3.1)
❏create_participant_with_profile() (see Section 8.3.1)
❏get_<entity>_qos_from_profile() (where <entity> is participant, topic, publisher, subscriber, datawriter, or datareader) (see Section 8.2.5)
❏get_<entity>_qos_from_profile_w_topic_name() (where <entity> is topic, datawriter, or datareader) (see Section 8.2.5)
❏get_default_participant_qos() (see Section 8.2.2)
❏get_qos_profile_libraries() (See Section 17.10.1)
❏get_qos_profiles() (See Section 17.9.5)
❏load_profiles()
❏set_default_participant_qos_with_profile() (see Section 8.2.2)
❏set_default_library() (see Section 6.2.4.3)
❏set_default_profile() (see Section 6.2.4.3)
QoS profiles are reloaded when either of these DomainParticipantFactory operations are called:

❏reload_profiles()
❏set_qos() (see Section 4.1.7)
It is important to distinguish between loading and reloading:
❏Loading only happens when there are no previously loaded profiles. This could be when the profiles are loaded the first time or after a call to unload_profiles().
❏Reloading replaces all previously loaded profiles. Reloading a profile does not change the QoS of entities that have already been created with previously loaded profiles.
The DomainParticipantFactory also has an unload_profiles() operation that frees the resources associated with the XML QoS profiles.
DDS_ReturnCode_t unload_profiles()
17.3How to Use
You can use the operations listed in Table 17.1 to refer and use QoS profiles (see Section 17.9) described in XML files and XML strings.
Table 17.1 Operations for Working with QoS Profiles
Working With ... |
Reference |
||
|
|
|
|
|
|
|
|
DataReaders |
set_qos_with_profile |
||
|
|
|
|
DataWriters |
set_qos_with_profile |
||
|
|
|
|
|
create_datareader_with_profile |
||
|
|
|
|
|
create_datawriter_with_profile |
||
|
|
|
|
|
create_publisher_with_profile |
||
|
|
|
|
|
create_subscriber_with_profile |
||
|
|
|
|
|
create_topic_with_profile |
||
|
|
|
|
|
get_default_library |
|
|
|
|
|
|
|
get_default_profile |
||
|
|
|
|
DomainParticipants |
get_default_profile_library |
|
|
|
|
||
set_default_datareader_qos_with_profile |
|||
|
|||
|
|
||
|
set_default_datawriter_qos_with_profile |
||
|
|
||
|
|
|
|
|
set_default_library |
||
|
|
||
|
set_default_profile |
||
|
|
||
|
|
|
|
|
set_default_publisher_qos_with_profile |
|
|
|
|
|
|
|
set_default_subscriber_qos_with_profile |
||
|
|
|
|
|
set_default_topic_qos_with_profile |
|
|
|
|
|
|
|
set_qos_with_profile |
||
|
|
|

Table 17.1 Operations for Working with QoS Profiles
Working With ... |
Reference |
||
|
|
|
|
|
create_participant_with_profile |
||
|
|
|
|
|
get_datareader_qos_from_profile |
|
|
|
|
|
|
|
get_datawriter_qos_from_profile |
||
|
|
||
|
get_datawriter_qos_from_profile_w_topic_name |
||
|
|
||
|
|
|
|
|
get_datareader_qos_from_profile_w_topic_name |
|
|
|
|
|
|
|
get_default_library |
|
|
|
|
|
|
|
get_default_profile |
||
|
|
|
|
|
get_default_profile_library |
|
|
|
|
|
|
|
get_participant_qos_from_profile |
|
|
|
|
|
|
|
get_publisher_qos_from_profile |
|
|
DomainParticipantFactory |
|
|
|
get_subscriber_qos_from_profile |
|||
|
|
|
|
|
get_topic_qos_from_profile |
|
|
|
|
|
|
|
get_topic_qos_from_profile_w_topic_name |
|
|
|
|
|
|
|
get_qos_profiles |
||
|
|
|
|
|
get_qos_profile_libraries |
||
|
|
|
|
|
load_profiles |
||
|
|
||
|
reload_profiles |
||
|
|
||
|
|
|
|
|
set_default_participant_qos_with_profile |
||
|
|
|
|
|
set_default_library |
||
|
|
||
|
set_default_profile |
||
|
|
||
|
|
|
|
|
unload_profiles |
||
|
|
|
|
|
create_datawriter_with_profile |
||
|
|
|
|
|
get_default_library |
|
|
|
|
|
|
|
get_default_profile |
||
|
|
|
|
Publishers |
get_default_profile_library |
|
|
|
|
||
set_default_datawriter_qos_with_profile |
|||
|
|||
|
|
|
|
|
set_default_library |
||
|
|
||
|
set_default_profile |
||
|
|
||
|
|
|
|
|
set_qos_with_profile |
||
|
|
|
|
|
create_datareader_with_profile |
||
|
|
|
|
|
get_default_library |
|
|
|
|
|
|
|
get_default_profile |
||
|
|
|
|
Subscribers |
get_default_profile_library |
|
|
|
|
||
set_default_datawriter_qos_with_profile |
|||
|
|||
|
|
|
|
|
set_default_library |
||
|
|
||
|
set_default_profile |
||
|
|
||
|
|
|
|
|
set_qos_with_profile |
||
|
|
|
|
Topics |
set_qos_with_profile |
||
|
|
|
17.4XML File Syntax
The XML configuration file must follow these syntax rules:

❏The syntax is XML and the character encoding is
❏Opening tags are enclosed in <>; closing tags are enclosed in </>.
❏A tag value is a
For example, " <tag> value </tag>" is the same as "<tag>value</tag>".
❏All values are
❏Comments are enclosed as follows:
❏The root tag of the configuration file must be <dds> and end with </dds>.
❏The primitive types for tag values are specified in Table 17.2.
Table 17.2 Supported Tag Values
Type |
|
|
|
Format |
|
Notes |
|
|
|
|
|
|
|
|
|
|
yesa, |
1, |
true, |
BOOLEAN_TRUEa |
or |
|
|
DDS_Boolean |
DDS_BOOLEAN_TRUEa: these all mean TRUE |
|
Not |
||||
noa, |
0, |
false, |
BOOLEAN_FALSEa |
or |
|||
|
|
||||||
|
DDS_BOOLEAN_FALSEa: these all mean FALSE |
|
|||||
|
A string. Legal values are those listed in the API |
Must be specified as a string. |
|||||
DDS_Enum |
Reference HTML documentation for the Ca |
or |
(Do not use numeric values.) |
||||
|
Java API. |
|
|
|
|
||
|
|
|
|||||
DDS_Long |
or 0x80000000 to 0x7fffffffa |
|
A |
||||
or LENGTH_UNLIMITED |
|
||||||
|
|
|
|||||
|
or DDS_LENGTH_UNLIMITEDa |
|
|
||||
|
0 to 4294967296 |
|
|
|
|||
DDS_UnsignedLong |
or |
|
|
|
|
A |
|
|
0 to 0xffffffffa |
|
|
|
|
||
String |
|
All leading and trailing spaces |
|||||
|
are ignored between two tags |
||||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
a.These values will not be considered valid if you use the distributed XSD document to do validation at
17.5Using Environment Variables in XML
The text within an XML tag can refer to environment variable. To do so, use the following notation:
$(MY_VARIABLE)
For example:
<element>
<name>The name is $(MY_NAME)</name> <value>The value is $(MY_VALUE)</value>
</element>
When the Connext XML parser parses the previous tags it will replace the references to environment variables with their actual values.
1. Leading and trailing spaces in enumeration fields will not be considered valid if you use the distributed XSD document to do validation at
17.6XML String Syntax
XML profiles can be described using strings. This configuration is useful for architectures without a file system.
There are two different ways to configure Entities via XML strings:
❏String URLs are prefixed by the URI schema str:// and enclosed in double quotes. For example:
str://"<dds><qos_library>...</qos_library></dds>"
The string URLs can be specified in the environment variable NDDS_QOS_PROFILES as well as in the field url_profile in PROFILE QosPolicy (DDS Extension) (Section 8.4.2). Each string URL must contain a whole XML document.
❏The string_profile field in the PROFILE QosPolicy (DDS Extension) (Section 8.4.2) allows you to split an XML document into multiple strings. For example:
const char * MyXML[4] =
{
"<dds>",
"<qos_library name=\"MyLibrary\">", "</qos_library>",
"</dds>"
}; factoryQos.profile.string_profile.from_array(MyXML,4);
Only one XML document can be specified with the string_profile field.
17.7How the XML is Validated
17.7.1Validation at
Connext validates the input XML files using a builtin Document Type Definition (DTD).
You can find a copy of the builtin DTD in $(NDDSHOME)/resource/qos_profiles_5.0.x1/ schema/rti_dds_qos_profiles.dtd. (This is only a copy of what the Connext core uses. Changing this file has no effect unless you specify its path with the <!DOCTYPE> tag, described below.)
You can overwrite the builtin DTD by using the XML tag, <!DOCTYPE>. For example, the following indicates that Connext must use a DTD file from a user’s directory to perform validation:
<!DOCTYPE dds SYSTEM "/local/joe/rti/dds/mydds.dtd">
❏The DTD path can be absolute, or relative to the application's current working directory.
❏If the specified file does not exist, you will see the following error:
RTIXMLDtdParser_parse:!open DTD file
❏If you do not specify the DOCTYPE tag in the XML file, the builtin DTD is used.
❏The XML files used by Connext can be versioned using the attribute version in the <dds> tag. For example:
<dds version="5.0.x">
...
1.x stands for the version number of the current release.

</dds>
Although the attribute version is not required during the validation process, it helps to detect DTD incompatibility scenarios by providing better error messages.
For example, if an application using Connext 5.0.x tries to load an XML file from Connext 4.5z and there is some incompatibility in the XML content, the following parsing error will be printed:
ATTENTION: The version declared in this file (4.5z) is different from the version of Connext (5.0.x). If these versions are not compatible, that incompatibility could be the cause of this error.
17.7.2XML File Validation During Editing
Connext provides DTD and XSD files that describe the format of the XML content. We recommend including a reference to one of these documents in the XML file that contains the QoS
The DTD and XSD definitions of the XML elements are in $(NDDSHOME)/resource/qos_profiles_5.0.x/schema/rti_dds_qos_profiles.dtd and $(NDDSHOME)/resource/qos_profiles_5.0.x/schema/rti_dds_qos_profiles.xsd, respectively (in ‘5.0.x’, x stands for the version number of the current release).
To include a reference to the XSD document in your XML file, use the attribute xsi:noNamespaceSchemaLocation in the <dds> tag. For example:
<?xml version="1.0"
<dds
"<NDDSHOME1>/resource/qos_profiles_5.0.x/schema/rti_dds_qos_profiles.xsd">
...
</dds>
To include a reference to the DTD document in your XML file use the <!DOCTYPE> tag. For example:
<?xml version="1.0"
"<NDDSHOME1>/resource/qos_profiles_5.0.x/schema/rti_dds_qos_profiles.dtd"> <dds>
...
</dds>
We recommend including a reference to the XSD file in the XML documents because it provides stricter validation and better
17.8Configuring QoS with XML
To configure the QoS for an Entity using XML, use the following tags:
❏<participant_factory_qos>
Note: The only QoS policies that can be configured for the DomainParticipantFactory are <entity_factory> and <logging>.
❏<participant_qos>
❏<publisher_qos>
1.Replace <NDDSHOME> with the installation directory of Connext.
❏<subscriber_qos>
❏<topic_qos>
❏<datawriter_qos> or <writer_qos> (writer_qos is valid only with DTD validation)
❏<datareader_qos> or <reader_qos> (reader_qos is valid only with DTD validation)
Each QoS can be identified by a name. The QoS can inherit its values from other QoSs described in the XML file. For example:
<datawriter_qos name="DerivedWriterQos" base_name="Lib::BaseWriterQos"> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
</datawriter_qos>
In the above example, the datawriter_qos named 'DerivedWriterQos' inherits the values from 'BaseWriterQos' in the library 'Lib'. The HistoryQosPolicy kind is set to KEEP_ALL_HISTORY_QOS.
Each XML tag with an associated name can be uniquely identified by its fully qualified name in C++ style.
The writer, reader and topic QoSs can also contain an attribute called topic_filter that will be used to associate a set of topics to a specific QoS when that QoS is part of a QoS profile. See Topic Filters (Section 17.9.3) and QoS Profiles (Section 17.9).
17.8.1QosPolicies
The fields in a QosPolicy are described in XML using a
struct DDS_Duration_t { DDS_Long sec; DDS_UnsignedLong nanosec;
}
struct DDS_ReliabilityQosPolicy { DDS_ReliabilityQosPolicyKind kind; DDS_Duration_t max_blocking_time;
}
The equivalent representation in XML is as follows:
<reliability>
<kind></kind> <max_blocking_time>
<sec></sec>
<nanosec></nanosec> </max_blocking_time>
</reliability>
17.8.2Sequences
In general, sequences in QosPolicies are described with the following XML format:
<a_sequence_member_name> <element>...</element> <element>...</element>
...
</a_sequence_member_name>
Each element of the sequence is enclosed in an <element> tag. For example:
<property>

<value>
<element>
<name>my name</name> <value>my value</value>
</element>
<element>
<name>my name2</name> <value>my value2</value>
</element>
</value>
</property>
A sequence without elements represents a sequence of length 0. For example:
<discovery>
</discovery>
For sequences that may have a default initialization that is not empty (such as the initial_peers field in the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2)), using the above construct would result in an empty list and not the default value. So to simply show a sequence for the sake of completeness, but not change its default value, comment it out, as follows:
<discovery>
</discovery>
As a general rule, sequences defined in a derived1 QoS will replace the corresponding sequences in the base QoS. For example, consider the following:
<qos_profile name="MyBaseProfile">
<participant_qos> <discovery>
<initial_peers>
<element>192.168.1.1</element>
<element>192.168.1.2</element>
</initial_peers> </discovery>
</participant> </qos_profile>
<qos_profile name="MyDerivedProfile" base_name="MyBaseProfile">
<participant_qos> <discovery>
<initial_peers>
<element>192.168.1.3</element>
</initial_peers> </discovery>
</participant> </qos_profile>
The initial peers sequence defined above in the participant QoS of MyDerivedProfile will contain a single element with a value 192.168.1.3. The elements 192.168.1.1 and 192.168.1.2 will not be inherited. However, there is one exception to this behavior. The <property> tag provides an attribute called inherit that allows you to choose the inheritance behavior for the sequence defined within the tag.
The <property> tag provides an attribute called inherit that allows you to choose the inheritance behavior for the sequence defined within the tag.
1. The concepts of derived and base QoS are described in QoS Profile Inheritance (Section 17.9.2).
By default, the value of the attribute inherit is true. Therefore, the <property> tag defined within a derived QoS profile will inherit its elements from the <property> tag defined within a base QoS profile.
In the following example, the property sequence defined in the participant QoS of MyDerivedProfile will contain two properties:
❏dds.transport.UDPv4.builtin.send_socket_buffer_size will be inherited from the base profile and have the value 524288.
❏dds.transport.UDPv4.builtin.recv_socket_buffer_size will overwrite the value defined in the base QoS profile with 1048576.
<qos_profile name="MyBaseProfile">
<participant_qos>
<property>
<value>
<element>
<name>dds.transport.UDPv4.builtin.send_socket_buffer_size</name> <value>524288</value>
</element>
<element>
<name>dds.transport.UDPv4.builtin.recv_socket_buffer_size</name> <value>2097152</value>
</element>
</value>
</discovery>
</property> </qos_profile>
<qos_profile name="MyDerivedProfile" base_name="MyBaseProfile">
<participant_qos>
<property>
<value>
<element>
<name>dds.transport.UDPv4.builtin.recv_socket_buffer_size</name> <value>1048576</value>
</element>
</value>
</discovery>
</property> </qos_profile>
To discard all the properties defined in the base QoS profile, set inherit to false.
In the following example, the property sequence defined in the participant QoS of MyDerivedProfile will contain a single property named dds.transport.UDPv4.builtin.recv_socket_buffer_size, with a value of 1048576. The property dds.transport.UDPv4.builtin.send_socket_buffer_size will not be inherited.
<qos_profile name="MyBaseProfile">
<participant_qos> <property>
<value>
<element>
<name>dds.transport.UDPv4.builtin.send_socket_buffer_size</name> <value>524288</value>
</element>
<element>
<name>dds.transport.UDPv4.builtin.recv_socket_buffer_size</name> <value>2097152</value>
</element>
</value>
</discovery>
</property> </qos_profile>
<qos_profile name="MyDerivedProfile" base_name="MyBaseProfile">
<participant_qos>
<property inherit="false">
<value>
<element>
<name>dds.transport.UDPv4.builtin.recv_socket_buffer_size</name> <value>1048576</value>
</element>
</value>
</discovery>
</property> </qos_profile>
17.8.3Arrays
In general, the arrays contained in the QosPolicies are described with the following XML format:
<an_array_member_name> <element>...</element> <element>...</element>
...
</an_array_member_name>
Each element of the array is enclosed in an <element> tag.
As a special case, arrays of octets are represented with a single XML tag enclosing an array of decimal/hexadecimal values between 0..255 separated with commas.
For example:
<reader_qos>
...
<protocol> <virtual_guid>
<value>1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16</value> </virtual_guid>
</protocol> </reader_qos>
17.8.4Enumeration Values
Enumeration values are represented using their C or Java string representation. For example:
<history> <kind>DDS_KEEP_ALL_HISTORY_QOS</kind>
</history>
or
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
When the XSD document is used for validation during editing (see Section 17.7.2), only the Java representation is valid.
17.8.5Time Values (Durations)
You can use the following special values for fields that require seconds or nanoseconds:
❏DURATION_INFINITE_SEC or DDS_DURATION_INFINITE_SEC,

❏DURATION_ZERO_SEC or DDS_DURATION_ZERO_SEC,
❏DURATION_INFINITE_NSEC or DDS_DURATION_INFINITE_NSEC
❏DURATION_ZERO_NSEC or DDS_DURATION_ZERO_NSEC
For example:
<deadline>
<period> <sec>DURATION_INFINITE_SEC</sec>
<nanosec>DURATION_INFINITE_NSEC</nanosec> </period>
</deadline>
When the XSD document is used for validation during editing (see Section 17.7.2), only the values without the DDS prefix are considered valid.
17.8.6Transport Properties
You can configure transport plugins using the DomainParticipant’s PROPERTY QosPolicy (DDS Extension) (Section 6.5.17).
❏Properties for the builtin transports are described in Setting Builtin Transport Properties with the PropertyQosPolicy (Section 15.6).
❏Properties for other transport plugins such as RTI TCP Transport1are described in their respective chapters in this manual.
For example:
<participant_qos> <property> <value>
<element>
<name>dds.transport.UDPv4.builtin.parent.message_size_max
</name>
<value>65536</value>
</element>
<element> <name>dds.transport.UDPv4.builtin.send_socket_buffer_size </name>
<value>131072</value>
</element>
<element> <name>dds.transport.UDPv4.builtin.recv_socket_buffer_size </name>
<value>262144</value>
</element>
</value>
</property> </participant_qos>
17.8.7Thread Settings
See Table 19.1, “XML Tags for ThreadSettings_t,” on page
1. RTI TCP Transport is included with Connext, but is not enabled by default.

17.9QoS Profiles
A QoS profile groups a set of related QoS, usually one per entity, identified by a name. For example:
<qos_profile name="StrictReliableCommunicationProfile"> <datawriter_qos>
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datawriter_qos>
<datareader_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datareader_qos>
</qos_profile>
Duplicate QoS profiles are not allowed. To overwrite a QoS profile, use QoS Profile Inheritance (Section 17.9.2).
There are functions that allow you to create Entities using profiles, such as create_participant_with_profile() (Section 8.3.1), create_topic_with_profile() (Section 5.1.1), etc.
If you create an entity using a profile without a QoS definition or an inherited QoS definition (see QoS Profile Inheritance (Section 17.9.2)) for that class of entity, Connext uses the default QoS.
Example 1:
<qos_profile name="BatchStrictReliableCommunicationProfile" base_name="StrictReliableCommunicationProfile"> <datawriter_qos>
<batch>
<enable>true</enable>
</batch> </datawriter_qos>
</qos_profile>
The DataReader QoS value in the profile BatchStrictReliableCommunicationProfile is inherited from the profile StrictReliableCommunicationProfile.
Example 2:
<qos_profile name="BatchProfile"> <datawriter_qos>
<batch>
<enable>true</enable>
</batch> </datawriter_qos>
</qos_profile>
The DataReader QoS value in the profile BatchProfile is the default Connext QoS.
17.9.1QoS Profiles with a Single QoS
The definition of an individual QoS outside a profile is a shortcut for defining a QoS profile with a single QoS. For example:
<datawriter_qos name="KeepAllWriter"> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
</datawriter_qos>
is equivalent to:
<qos_profile name="KeepAllWriter"> <datawriter_qos>
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history> </datawriter_qos>
</qos_profile>
17.9.2QoS Profile Inheritance
An individual QoS or profile can inherit values from other QoSs or profiles described in the XML file by using the attribute, base_name.
Inheriting from other XML Files: A QoS or QoS Profile may inherit values from other QoSs or QoS Profiles described in different XML files. A QoS or profile can only inherit from other QoS policies or profiles that have already been loaded. The order in which XML resources are loaded is described in Section 17.2.
The following examples show how to inherit from other profiles:
Example 1:
<qos_library name=”Library”> <qos_profile name="BaseProfile">
<datawriter_qos>
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
<qos_profile name="DerivedProfile" base_name="BaseProfile"> <datawriter_qos>
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
</qos_library>
The writer_qos and reader_qos in DerivedProfile inherit their values from the corresponding QoS in BaseProfile.
Example 2:
<qos_library name=”Library”> <datareader_qos name="BaseProfile">
...
</datareader_qos>
<datareader_qos name="DerivedProfile" base_name="BaseProfile">
...
</datareader_qos> </qos_library>
The datareader_qos in DerivedProfile inherits its values from the datareader_qos of BaseProfile. In this example, the datareader_qos definition is a shortcut for a profile definition with a single QoS (see Section 17.9.1).
Example 3:
<qos_library name=”Library”> <qos_profile name="Profile1">
<datawriter_qos name="BaseWriterQoS">
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
<qos_profile name="Profile2">
<datawriter_qos name="DerivedWriterQos" base_name="Profile1::BaseWriterQos">
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
</qos_library>
The datawriter_qos in Profile2 inherits its values from the datawriter_qos in Profile1. The datareader_qos in Profile2 will not inherit the values from the corresponding QoS in Profile1.
Example 4:
<qos_library name=”Library”>
<qos_profile name="Profile1">
<datawriter_qos>
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
<qos_profile name="Profile2"> <datawriter_qos name="BaseWriterQoS">
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
<qos_profile name="Profile3" base_name="Profile1">
<datawriter_qos name="DerivedWriterQos" base_name="Profile2::BaseWriterQos">
...
</datawriter_qos> <datareader_qos>
...
</datareader_qos> </qos_profile>
</qos_library></qos_library>
The datawriter_qos in Profile3 inherits its values from the datawriter_qos in Profile2. The datareader_qos in Profile3 inherits its values from the datareader_qos in Profile1.
Example 5:
<qos_library name=”Library”> <datareader_qos name="BaseProfile">
...
</datareader_qos>
<profile name="DerivedProfile" base_name="BaseProfile"> <datareader_qos>
...
</datareader_qos>
</profile> </qos_library>
The datareader_qos in DerivedProfile inherits its values from the datareader_qos in BaseProfile.
17.9.3Topic Filters
A QoS profile may contain several writer, reader and topic QoSs. Connext will select a QoS based on the evaluation of a filter expression on the topic name. The filter expression is specified as an attribute in the XML QoS definition. For example:
<qos_profile name="StrictReliableCommunicationProfile">
<datawriter_qos topic_filter="A*">
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datawriter_qos>
<datawriter_qos topic_filter="B*">
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> <resource_limits>
<max_samples>128</max_samples> <max_samples_per_instance>128 </max_samples_per_instance> <initial_samples>128</initial_samples> <max_instances>1</max_instances> <initial_instances>1</initial_instances>
</resource_limits> </datawriter_qos>
…
</qos_profile>
If topic_filter is not specified in a QoS, Connext will assume the filter '*'. The QoSs with an explicit topic_filter attribute definition will be evaluated in order; they have precedence over a QoS without a topic_filter expression.
The topic_filter attribute is only used with the following APIs:
DomainParticipantFactory:
❏get_<entity>_qos_from_profile_w_topic_name() (where <entity> may be topic, datareader, or datareader; see Section 8.2.5)
DomainParticipant:
❏create_datawriter_with_profile() (see Creating DataWriters (Section 6.3.1))
❏create_datareader_with_profile() (see Creating DataReaders (Section 7.3.1)
❏create_topic_with_profile() (see Creating Topics (Section 5.1.1))
Publisher:
❏create_datawriter_with_profile() (see Creating DataWriters (Section 6.3.1)) Subscriber:
❏create_datareader_with_profile() (see Creating DataReaders (Section 7.3.1))
Topic:
❏set_qos_with_profile() (see Setting Topic QosPolicies (Section 5.1.3)) DataWriter:
❏set_qos_with_profile() (see Changing QoS Settings After the Publisher Has Been Created (Section 6.2.4.2))
DataReader:
❏ set_qos_with_profile() (see Setting DataReader QosPolicies (Section 7.3.8))
Other APIs will ignore QoSs with a topic_filter value different than "*". A QoS Profile with QoSs using topic_filter can also inherits from other QoS Profiles. In this case, inheritance will consider the value of the topic_filter expression.
Example 1:
<qos_library name=”Library”> <qos_profile name="BaseProfile">
<datawriter_qos>
...
</datawriter_qos>
<datawriter_qos topic_filter="T1*">
...
</datawriter_qos>
<datawriter_qos topic_filter="T2*">
...
</datawriter_qos> </qos_profile>
<qos_profile name="DerivedProfile" base_name="BaseProfile"> <datawriter_qos topic_filter="T11">
...
</datawriter_qos>
<datawriter_qos topic_filter="T21">
...
</datawriter_qos>
<datawriter_qos topic_filter="T31">
...
</datawriter_qos> </qos_profile>
</qos_library>
The datawriter_qos with topic_filter T11 in DerivedProfile will inherit its values from the datawriter_qos with topic_filter T1* in BaseProfile. The datawriter_qos with topic_filter T21 in DerivedProfile will inherit its values from the datawriter_qos with topic_filter T2* in BaseProfile. The datawriter_qos with topic_filter T31 in DerivedProfile will inherit its values from the datawriter_qos without topic_filter in BaseProfile.
Example 2:
<qos_library name=”Library”> <qos_profile name="BaseProfile">
<datawriter_qos topic_filter="T1*">
...
</datawriter_qos>
<datawriter_qos name="T2DataWriterQoS" topic_filter="T2*">
...
</datawriter_qos> </qos_profile>
<qos_profile name="DerivedProfile" base_name="BaseProfile"> <datawriter_qos topic_filter="T11"
base_name="BaseProfile::T2DataWriterQoS">
...
</datawriter_qos>
<datawriter_qos topic_filter="T21">
...
</datawriter_qos> </qos_profile>
</qos_library>
Although the topic_filter expressions do not match, the datawriter_qos with topic_filter T11 in DerivedProfile will inherit its values from the datawriter_qos with topic_filter T2* in BaseProfile. topic_filter is not used with inheritance from QoS to QoS. The datawriter_qos with topic_filter T21 in DerivedProfile will inherit its values from the datawriter_qos with topic_filter T2* in BaseProfile.
Example 3:
<qos_library name=”Library”>
<datawriter_qos name="BaseQos" topic_filter="T1">
...
</datawriter_qos>
<datawriter_qos name="DerivedQos" base_name="BaseQos" topic_filter="T2">
...
</datawriter_qos> </qos_library>
In the case of a single QoS profile, although the topic_filter expressions do not match, the datawriter_qos named DerivedQos with topic_filter T2 will inherit its values from the datawriter_qos named BaseQos with topic_filter T1.
17.9.4Overwriting Default QoS Values
There are two ways to overwrite the default QoS used for new entities with values from a profile: programmatically and with an XML attribute.
❏You can overwrite the default QoS programmatically with set_default_<entity>_qos_with_profile() (where <entity> is participant, topic, publisher, subscriber, datawriter, or datareader)
❏You can overwrite the default QoS using the XML attribute is_default_qos with the
<qos_profile> tag
❏Only for the DomainParticipantFactory: You can overwrite the default QoS using the XML attribute is_default_participant_factory_profile. This attribute has precedence over is_default_qos if both are set.
In the following example, the DataWriter and DataReader default QoS will be overwritten with the values specified in a profile named ‘StrictReliableCommunicationProfile’:

<qos_profile name="StrictReliableCommunicationProfile" is_default_qos="true">
<datawriter_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datawriter_qos> <datareader_qos>
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datareader_qos>
</qos_profile>
If multiple profiles are configured to overwrite the default QoS, only the last one parsed applies.
Example:
In this example, the profile used to configure the default QoSs will be
StrictReliableCommunicationProfile.
<qos_profile name="BestEffortCommunicationProfile" is_default_qos="true">
...
</qos_profile>
<qos_profile name="StrictReliableCommunicationProfile" is_default_qos="true">
...
</qos_profile>
17.9.5Get Qos Profiles
To get a list of loaded QoS profiles, call the DomainParticipantFactory’s get_qos_profiles() operation, which returns the names of all profiles within a specified QoS library. Either the input QoS library name must be specified or the default profile library must have been set prior to calling this function.
DDS_ReturnCode_t get_qos_profiles (struct DDS_StringSeq *profile_names, const char *library_name)
17.10 QoS Libraries
A QoS Library is a named set of QoS profiles.
One configuration file may have several QoS libraries, each one defining its own QoS profiles. All QoS libraries must be declared within <dds> and </dds> tags. For example:
<dds>
<qos_library name="RTILibrary">
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history> </datawriter_qos>

<qos_profile name="StrictReliableCommunicationProfile">
<datawriter_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datawriter_qos> <datareader_qos>
<history> <kind>KEEP_ALL_HISTORY_QOS</kind>
</history>
<reliability> <kind>RELIABLE_RELIABILITY_QOS</kind>
</reliability> </datareader_qos>
</qos_profile>
</qos_library> </dds>
A QoS library can be reopened within the same configuration file or across different configuration files. For example:
<dds>
<qos_library name="RTILibrary">
...
</qos_library>
...
<qos_library name="RTILibrary">
...
</qos_library> </dds>
17.10.1 Get Qos Profile Libraries
To get a list of available QoS libraries, call the DomainParticipantFactory’s get_qos_profile_libraries() operation, which returns the names of all QoS libraries that have been loaded by Connext.
DDS_ReturnCode_t get_qos_profile_libraries (struct DDS_StringSeq *profile_names)
17.11 URL Groups
To provide redundancy and fault tolerance, you can specify multiple locations for a single XML document via URL groups. The syntax of a URL group is:
[URL1 | URL2 | URL2 | ... | URLn]
For example:
[file:///usr/local/default_dds.xml | file:///usr/local/alternative_default_dds.xml]
Only one of the elements in the group will be loaded by Connext, starting from the left.
Brackets are not required for groups with a single URL.
The NDDS_QOS_PROFILES environment variable contains a set of URL groups separated by semicolons. For example, on Linux and Solaris systems:

setenv NDDS_QOS_PROFILES [file:///usr/local/default_dds.xml|file:///usr/local/ alternative_default_dds.xml];[str://"<dds><qos_library name="MyQosLibrary"></ qos_library></dds>"]
The url_profile field in the PROFILE QosPolicy (DDS Extension) (Section 8.4.2) will contain a sequence of URL groups.
17.12 Configuring Logging Via XML
Logging can be configured via XML using the DomainParticipantFactory’s LoggingQosPolicy. See Section 21.2.2 for additional details.

Chapter 18
In Connext, producers publish data to a Topic, identified by a topic name; consumers subscribe to a Topic and optionally to specific content by means of a
A Market Data Example:
A producer can publish data on the Topic "MarketData" which can be defined as a structured record containing fields that identify the exchange (e.g., "NYSE" or "NASDAQ"), the stock symbol (e.g., "APPL" or "JPM"), volume, bid and ask prices, etc.
Similarly, a consumer may want to subscribe to data on the "MarketData" Topic, but only if the exchange is "NYSE" or the symbol starts with the letter "M." Or the consumer may want all the data from the "NYSE" whose volume exceeds a certain threshold, or may want MarketData for a specific stock symbol, regardless of the exchange, and so on.
The middleware’s efficient implementation of
Traditionally, middleware products use four approaches to implement content filtering:
❏
❏

❏
❏Network
RTI supports the
❏RTI automatically uses the
❏To use the more scalable
18.1What is a
A
To determine which multicast addresses will be used to send the data, the middleware evaluates a set of filters that are configured for the DataWriter. Each filter "guards" a
The problem is that the most efficient way to deliver data to multiple applications is to use multicast so that a data value is only sent once on the network for any number of subscribers to the data. However, using multicast, an application will receive all of the data sent and not just the data in which it is interested, thus extra CPU time is wasted to throw away unwanted data. With this QoS, you can analyze the
Note: Your system can gain more of the benefits of using multiple multicast groups if your network uses Layer 2 Ethernet switches. Layer 2 switches can be configured to only route multicast packets to those ports that have added membership to specific multicast groups.
Figure 18.1
Figure 18.2
Using those switches will ensure that only the multicast packets used by applications on a node are routed to the node; all others are

18.2How to Configure a
To configure a
Each channel consists of filter criterion to apply to the data and a set of multicast destinations (transport, address, port) that will be used for sending data that matches the filter. You can think of this sequence of channels as a table like the one shown below:
If the Data Matches this Filter... |
Send the Data to these Multicast Destinations |
|
|
Symbol MATCH |
UDPv4:225.0.0.1:9000 |
|
|
Symbol MATCH |
UDPv4:225.0.0.2:9001 |
|
|
Symbol MATCH |
UDPv4:225.0.0.3:9002; 225.0.0.4:9003; |
|
|
The example C++ code in Figure 18.3 on page 4 shows how to configure the channels.
Figure 18.3 Using the MULTI_CHANNEL QosPolicy
//initialize writer_qos with default values
//Initialize MULTI_CHANNEL Qos Policy
//Assign the filter name
//Possible options: DDS_STRINGMATCHFILTER_NAME, DDS_SQLFILTER_NAME writer_qos.multi_channel.filter_name = (char*) DDS_STRINGMATCHFILTER_NAME;
//Create two channels
writer_qos.multi_channel.channels.ensure_length(2,2);
// First channel writer_qos.multi_channel.channels[0].filter_expression =
DDS_String_dup("Symbol MATCH
DDS_String_dup("239.255.1.1");
// Second channel writer_qos.multi_channel.channels[1].multicast_settings.ensure_length(1,1); writer_qos.multi_channel.channels[1].multicast_settings[0].receive_port = 8800; writer_qos.multi_channel.channels[1].multicast_settings[0].receive_address =
DDS_String_dup("239.255.1.2"); writer_qos.multi_channel.channels[1].filter_expression =
DDS_String_dup("Symbol MATCH
// Create writer
writer =
topic, writer_qos, NULL, DDS_STATUS_MASK_NONE);
The MULTI_CHANNEL QosPolicy is propagated along with discovery traffic. The value of this policy is available in the builtin topic for the publication (see the locator_filter field in Table 16.2, “Publication
18.2.1Limitations
When considering use of a
❏A DataWriter that uses the MULTI_CHANNEL QosPolicy will ignore multicast and unicast addresses specified on the reader side through the TRANSPORT_MULTICAST QosPolicy (DDS Extension) (Section 7.6.5) and TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23). The DataWriter will not publish samples on these locators.
❏
❏
❏
❏
❏To guarantee reliable delivery, a DataReader's PRESENTATION QosPolicy (Section 6.4.6) must be set to
18.3
No special changes are required in a subscribing application to get data from a
DataWriter.
If you want the DataReader to subscribe to only a subset of the channels, use a ContentFilteredTopic, as described in Section 5.4. For example:
// Create a content filtered topic
contentFilter = participant->create_contentfilteredtopic_with_filter( "FilteredTopic",
topic,
"symbol MATCH 'NYE/BAC,NASDAQ/MSFT,NASDAQ/GOOG", parameters,
DDS_STRINGMATCHFILTER_NAME);
// Create a DataReader that uses the content filtered topic reader =
contentFilter, DDS_DATAREADER_QOS_DEFAULT, NULL,0);
From there, Connext takes care of all the necessary steps:
❏The DataReader automatically discovers all the
❏When the DataReader discovers a
❏When the
With all this information, Connext automatically determines which channels are of "interest" to the DataReader.
A DataReader is interested in a channel if and only if the set of data values for which the channel guard filter evaluates to TRUE intersects the set of data values for which the DataReader's content filter evaluates to TRUE. If a DataReader does not use a content filter, then it is interested in all the channels.
Figure 18.4 Filter Intersection
In this scenario, the DataReader is interested in Channel1 and Channel2, but not Channel3.
Market Data Example, continued:
If the channel guard filter for Channel 1 is 'Symbol MATCH
That is, it will transfer data on 'APPL', "GOOG', and 'IBM', but not on 'MSFT', 'ORCL', or 'YHOO'. Channel 1 will be of interest to DataReaders whose content filter includes at least one stock whose symbol starts with a letter in the A to K range.
A DataReader that specifies a content filter such as "Symbol MATCH 'IBM, YHOO' " will be interested in Channel1.
A DataReader that specifies a content filter such as "Symbol MATCH
A DataReader that specifies a content filter such as "Symbol MATCH
18.4Where Does the Filtering Occur?
If
❏Filtering at the DataWriter (Section 18.4.1)
❏Filtering at the DataReader (Section 18.4.2)
❏Filtering on the Network Hardware (Section 18.4.3)
18.4.1Filtering at the DataWriter
Each time data is written, the DataWriter evaluates each of the channel guard filters to determine which channels will transmit the data. This filtering occurs on the DataWriter.

Filtering on the DataWriter side is scalable because the number of filter evaluations depends only on the number of channels, not on the number of DataReaders. Usually, the number of channels is smaller than the number of possible DataReaders.
As explained in Section 18.7, if the channel guard filters are configured to only look at the "key" fields in the data, the channel filtering becomes a very efficient lookup operation.
18.4.2Filtering at the DataReader
The DataReader will listen on the multicast addresses that correspond to the channels of interest (see Section 18.3). When a channel is 'of interest', it means that it is possible for the channel to transmit data that meets the content filter of the DataReader, however the channel may also transmit data that does not pass the DataReader's content filter. Therefore, the DataReader has to filter all incoming data on that channel to determine if it passes its content filter.
Market Data Example, continued:
Channel 1, identified by guard filter "Symbol MATCH
A DataReader with content filter "Symbol MATCH 'GOOG'" will listen on Channel1.
In addition to 'GOOG', the DataReader will also receive samples corresponding to stock symbols such as 'MSFT' and 'APPL'. The DataReader must filter these samples out.
As explained in Section 18.7, if the DataReader’s content filters are configured to only look at the "key" fields in the data, the DataReader filtering becomes a very efficient lookup operation.
18.4.3Filtering on the Network Hardware
DataReaders will only listen to multicast addresses that correspond to the channels of interest. The multicast traffic generated in other channels will be filtered out by the network hardware (routers, switches).
Layer 3 routers will only forward multicast traffic to the actual destination ports. However, by default, layer 2 switches treat multicast traffic as broadcast traffic. To take advantage of network filtering with layer 2 devices, they must be configured with IGMP snooping enabled (see Section 18.7.1).
18.5Fault Tolerance and Redundancy
To achieve fault tolerance and redundancy, configure the DataWriter’s MULTI_CHANNEL QosPolicy (DDS Extension) (Section 6.5.14) to publish a sample over multiple channels or over different multicast addresses within a single channel. Figure 18.5 shows how to use overlapping channels.
If a sample is published to multiple multicast addresses, a DataReader may receive multiple copies of the sample. By default, duplicates are discarded by the DataReader and not provided to the application. To change this default behavior, use the Durable Reader State property, dds.data_reader.state.filter_redundant_samples (see Section 12.4.4).

Figure 18.5 Using the MULTI_CHANNEL QosPolicy with Overlapping Channels
//initialize writer_qos with default values
//Initialize MULTI_CHANNEL Qos Policy
//Assign the filter name
//Possible options: DDS_STRINGMATCHFILTER_NAME and DDS_SQLFILTER_NAME writer_qos.multi_channel.filter_name = (char*) DDS_STRINGMATCHFILTER_NAME;
//Create two channels
writer_qos.multi_channel.channels.ensure_length(2,2);
// First channel writer_qos.multi_channel.channels[0].filter_expression =
DDS_String_dup("Symbol MATCH
DDS_String_dup("239.255.1.1");
// Second channel writer_qos.multi_channel.channels[1].multicast_settings.ensure_length(1,1); writer_qos.multi_channel.channels[1].multicast_settings[0].receive_port = 8800; writer_qos.multi_channel.channels[1].multicast_settings[0].receive_address =
DDS_String_dup("239.255.1.2"); writer_qos.multi_channel.channels[1].filter_expression =
DDS_String_dup("Symbol MATCH
//Symbols starting with
//Create writer
writer =
topic, writer_qos, NULL, DDS_STATUS_MASK_NONE);
18.6Reliability with
18.6.1Reliable Delivery
Reliable delivery is only guaranteed when the access_scope in the Subscriber's PRESENTATION QosPolicy (Section 6.4.6) is set to DDS_INSTANCE_PRESENTATION_QOS (default value) and the filters in the DataWriter's MULTI_CHANNEL QosPolicy (DDS Extension) (Section 6.5.14)) are
Market Data Example, continued:
Given the following IDL description for our MarketData topic type:
Struct MarketData { string<255> Symbol; //@key double Price;
}
A guard filter "Symbol MATCH 'APPL'" is
A guard filter "Symbol MATCH 'APPL' and Price < 100" is not
If any of the guard filters are based on
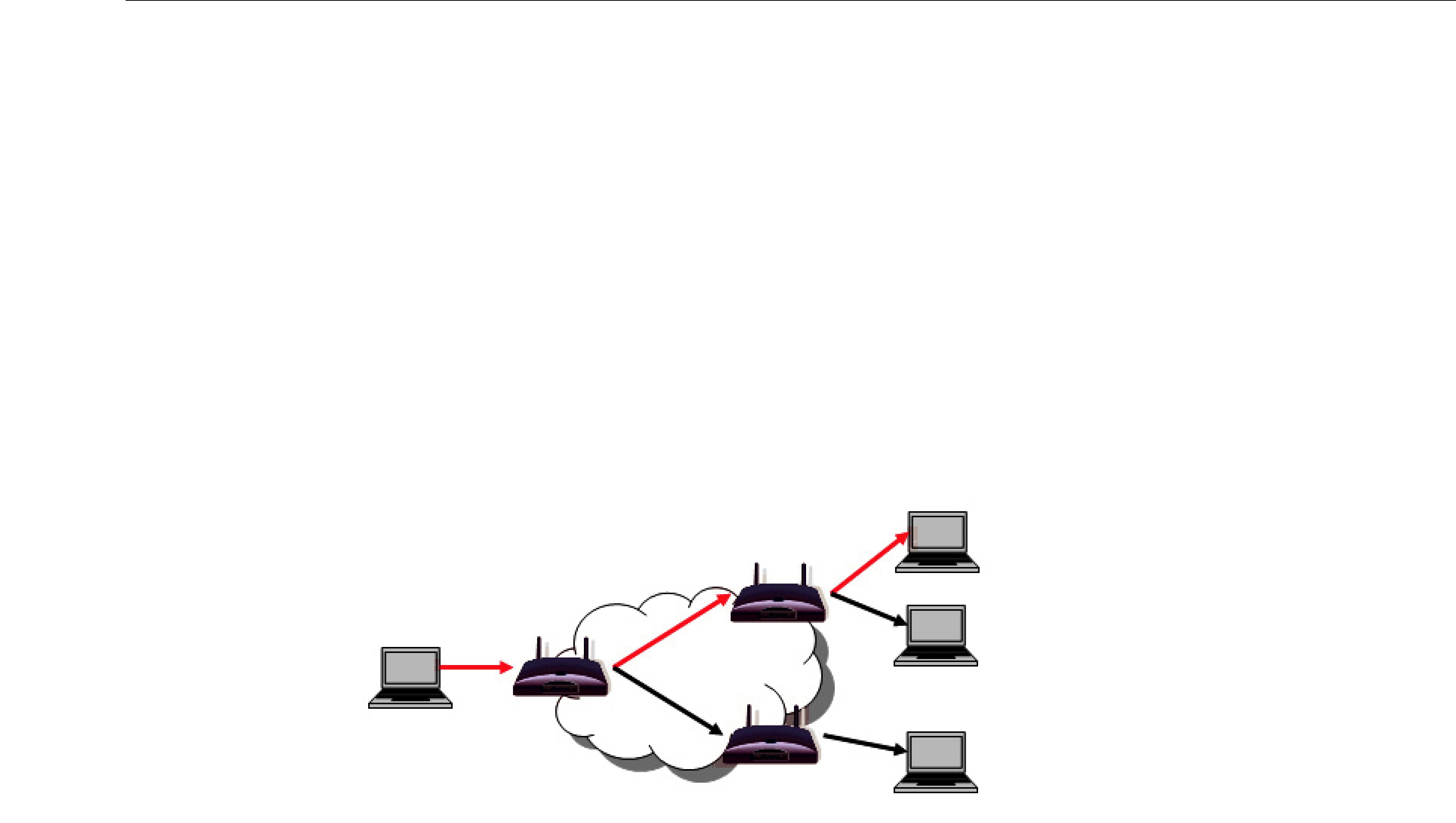
18.6.2Reliable Protocol Considerations
Reliability is maintained on a
❏low_watermark and high_watermark: The low watermark and high watermark control the queue levels (in number of samples) that determine when to switch between regular and fast heartbeat rates (see Section 6.5.3.1). With
Important: With
❏heartbeats_per_max_samples: This field defines the number of heartbeats per send queue. For
Important: With
samples even if batching is enabled. This behavior differs from the one without multi- channel DataWriters (where heartbeats_per_max_samples refers to batches, Section 6.5.3).
With batching and
18.7Performance Considerations
18.7.1
By default, multicast traffic is treated as broadcast traffic by layer 2 switches. To avoid flooding the network with broadcast traffic and take full advantage of network filtering, the layer 2 switches should be configured to use IGMP snooping. Refer to your switch’s manual for specific instructions.
When IGMP snooping is enabled, a switch can route a multicast packet to just those ports that subscribe to it, as seen in Figure 18.6.
Figure 18.6 IGMP Snooping

18.7.2DataWriter and DataReader Filtering
Where Does the Filtering Occur? (Section 18.4) describes the three places where filtering can occur with
Market Data Example, continued:
The filter expressions in the Market Data example are based on the value of the field, Symbol. To make filter operations on this field more efficient, declare Symbol as a key. For example:
struct {
string<MAX_SYMBOL_SIZE> Symbol; //@key
}
You can also improve performance by increasing the number of buckets associated with the hash table. To do so, use the instance_hash_buckets field in the RESOURCE_LIMITS QosPolicy (Section 6.5.20) on both the writer and reader sides. A higher number of buckets will provide better performance, but requires more resources.

Chapter 19 Connext Threading Model
This chapter describes the internal threads that Connext uses for sending and receiving data, maintaining internal state, and calling user code when events occur such as the arrival of new data samples. It may be important for you to understand how these threads may interact with your application.
A DomainParticipant uses three types of threads. The actual number of threads depends on the configuration of various QosPolicies as well as the implementation of the transports used by the DomainParticipant to send and receive data.
❏Database Thread (Section 19.1)
❏Receive Threads (Section 19.3)
❏Exclusive Areas, Connext Threads and User Listeners (Section 19.4)
❏Controlling CPU Core Affinity for RTI Threads (Section 19.5)
Through various QosPolicies, the user application can configure the priorities and other properties of the threads created by Connext. In
19.1Database Thread
Connext uses internal data structures to store information about
DomainParticipant.
As Entities and objects are created and deleted during the normal operation of the user application, different entries in the database may be created and deleted as well. Because multiple threads may access objects stored in the database simultaneously, the deletion and removal of an object from the database happens in two phases to support thread safety.
When an entry/object in the database is deleted either through the actions of user code or as a result of a change in system state, it is only marked for deletion. It cannot be actually deleted and removed from the database until Connext can be sure that no threads are still accessing the object. Instead, the actual removal of the object is delegated to an internal thread that Connext spawns to periodically wake up and purge the database of deleted objects.

This thread is known as the Database thread (also referred to as the database cleanup thread).
❏ Only one Database thread is created for each DomainParticipant.
The DATABASE QosPolicy (DDS Extension) (Section 8.5.1) of the DomainParticipant configures both the resources used by the database as well as the properties of the cleanup thread. Specifically, the user may want to use this QosPolicy to set the priority, stack size and thread options of the cleanup thread. You must set these options before the DomainParticipant is created, because once the cleanup thread is started as a part of participant creation, these properties cannot be changed.
The period at which the
However, when a DomainParticipant is destroyed, all of the objects created by the DomainParticipant will be destroyed as well. Many of these objects are stored in the database, and thus must be destroyed by the cleanup thread. The DomainParticipant cannot be destroyed until the database is empty and is destroyed itself. Thus, there is a different parameter in the DATABASE QosPolicy, shutdown_cleanup_period, that is used by the database cleanup thread when the DomainParticipant is being destroyed. Typically set to be on the order of a second, this parameter reduces the additional time needed to destroy a DomainParticipant simply due to waiting for the cleanup thread to wake up and purge the database.
19.2Event Thread
During operation, Connext must wake up at different intervals to check the condition of many different
Entities.
For example, the DEADLINE QosPolicy (Section 6.5.5) is used to ensure that DataWriters have published data or DataReaders have received data within a specified time period. Similarly, the LIVELINESS QosPolicy (Section 6.5.13) configures Connext both to check periodically to see if a DataWriter has sent a liveliness message and to send liveliness messages periodically on the behalf of a DataWriter. As a last example, for reliable connections, heartbeats must be sent periodically from the DataWriter to the DataReader so that the DataReader can acknowledge the data that it has received, see Chapter 10: Reliable Communications.
The checking of whether or not deadlines have been missed, the invoking of
❏ Only one Event thread is created per DomainParticipant.
The EVENT QosPolicy (DDS Extension) (Section 8.5.5) of the DomainParticipant configures both the properties and resources of the Event thread. Specifically, the user may want to use this QosPolicy to set the priority, stack size and thread options of the Event thread. You must set these options before the DomainParticipant is created, because once the Event thread is started as a part of participant creation, these properties cannot be changed.
The EVENT QosPolicy also configures the maximum number of events that can be handled by the Event thread. While the Event thread can only service a single event at a time, it must maintain a queue to hold events that are pending. The initial_count and max_count parameters of the QosPolicy set the initial and maximum size of the queue.

The priority of the Event thread should be carefully set with respect to the priorities of the other threads in a system. While many events can tolerate some amount of latency between the time that the event expires and the time that the Event thread services the event, there may be
For example, if an application uses the liveliness of a remote DataWriter to infer the correct operation of a remote application, it may be critical for the user code in the DataReader Listener callback, on_liveliness_changed(), to be called by the Event thread as soon as it can be determined that the remote application has died. The operating system uses the priority of the Event thread to schedule this action.
19.3Receive Threads
Connext uses internal threads, known as Receive threads, to process the data packets received via underlying network transports. These data packets may contain
As a result of processing packets received by a transport, a Receive thread may respond by sending packets on the network. Discovery packets may be sent to other DomainParticipants in response to ones received. ACK/NACK packets are sent in response to heartbeats to support a reliable connection.
When a
The number of Receive threads that Connext will create for a DomainParticipant depends on how you have configured the QosPolicies of DomainParticipants, DataWriters and DataReaders as well as on the implementation of a particular transport. The behavior of the builtin transports is well specified. However, if a custom transport is installed for a DomainParticipant, you will have to understand how the custom transport works to predict how many Receive threads will be created.
The following discussion applies on a
Connext will try to create receive resources1 for every port of every transport on which it is configured to receive messages. The TRANSPORT_UNICAST QosPolicy (DDS Extension) (Section 6.5.23) for DomainParticipant, DataWriters, and DataReaders, the TRANSPORT_MULTICAST QosPolicy (DDS Extension) (Section 7.6.5) for DataReaders and the DISCOVERY QosPolicy (DDS Extension) (Section 8.5.2) for DomainParticipants all configure the number of ports and the number of transports that Connext will try to use for receiving messages.
Generally, transports will require Connext to create a new receive resource for every unique port number. However, this is both dependent on how the underlying physical transport works and the implementation of the transport
When Connext finds that it is configured to receive data on a port for a transport for which it has not already created a receive resource, it will ask the transport if any of the existing receive resources created for the transport can be shared. If so, then Connext will not have to create a new receive resource. If not, then Connext will.
1. If UDPv4 was the only transport that Connext supports, then we would have called these receive resources, sockets.
The TRANSPORT_UNICAST, TRANSPORT_MULTICAST, and DISCOVERY QosPolicies allow you customize ports for receiving user data (on a
How do receive resources relate to Receive threads? Connext will create a Receive thread to service every receive resource that is created. If you use a socket analogy, then for every socket created, Connext will use a separate thread to process the data received on that socket.
So how many thread will Connext create by
Three Receive threads are created for
❏2 for unicast (one for UDPv4, one for shared memory)
❏1 for multicast (for UDPv4)2
Two Receive threads created for user data:
❏2 for unicast (UDPv4, shared memory)
❏0 for multicast (because user data is not sent via multicast by default)
Therefore, by default, you will have a total of five Receive threads per DomainParticipant. By using only a single transport and disabling multicast, a DomainParticipant can have as few as 2 Receive threads.
Similar to the Database and Event threads, a Receive thread is configured by the RECEIVER_POOL QosPolicy (DDS Extension) (Section 8.5.6). However, note that the thread properties in the RECEIVER_POOL QosPolicy apply to all Receive threads created for the
DomainParticipant.
19.4Exclusive Areas, Connext Threads and User Listeners
Connext Event and Receive threads may invoke user code through the Listener callbacks installed on different Entities while executing internal Connext code. In turn, user code inside the callbacks may invoke Connext APIs that reenter the internal code space of Connext. For thread safety, Connext allocates and uses mutual exclusion semaphores (mutexes).
As discussed in Section 4.5, when multiple threads and multiple mutexes are mixed together, deadlock may result. To prevent deadlock from occurring, Connext is designed using careful analysis and following rules that force mutexes to be taken in a certain order when a thread must take multiple mutexes simultaneously.
However, because the Event and Receive threads already hold mutexes when invoking user callbacks, and because the Connext APIs that the user code can invoke may try to take other mutexes, deadlock may still result. Thus, to prevent user code to cause internal Connext threads to deadlock, we have created a concept called Exclusive Areas (EA) that follow rules that prevent deadlock. The more EAs that exist in a system, the more concurrency is allowed through Connext code. However, the more EAs that exist, the more restrictions on the Connext APIs that are allowed to be invoked in Entity Listener callbacks.
The EXCLUSIVE_AREA QosPolicy (DDS Extension) (Section 6.4.3) control how many EAs will be created by Connext. For a more detailed discussion on EAs and the restrictions on the use of Connext APIs within Entity Listener methods, please see Exclusive Areas (EAs) (Section 4.5).
1.
2.Multicast is not supported by shared memory transports.
19.5Controlling CPU Core Affinity for RTI Threads
Two fields in the DDS_ThreadSettings_t structure are related to CPU core affinity: cpu_list and cpu_rotation.
Note: Although DDS_ThreadSettings_t is used in the Event, Database, ReceiverPool, and AsynchronousPublisher QoS policies, cpu_list and cpu_rotation are only relevant in the RECEIVER_POOL QosPolicy (DDS Extension) (Section 8.5.6).
While most
The cpu_rotation determines how cpu_list affects processor affinity for
CPU affinities are commonly denoted with a bitmask, where set bits represent allowed processors to run on. This mask is printed in hex, so a CPU affinity of
If cpu_rotation is CPU_RR_ROTATION, each thread will be assigned in
The Platform Notes describe which architectures support this feature.
Table 19.1 describes the XML tags that you can use to configure thread settings. For more information, see Thread Settings (Section 17.8.7)
Table 19.1 XML Tags for ThreadSettings_t
Tags within |
|
Number |
|
Description |
of Tags |
||
<thread> |
|||
|
Allowed |
||
|
|
||
|
|
|
|
|
|
|
|
|
Each <element> specifies a processor on which the thread may run. |
|
|
|
<cpu_list> |
|
|
<cpu_list> |
<element>value</element> |
0 or 1 |
|
</cpu_list> |
|||
|
|
||
|
Only applies to platforms that support controlling CPU core affinity (see |
|
|
|
Section 19.5 and the Platform Notes). |
|
|
|
|
|
|
|
Determines how the CPUs in <cpu_list> will be used by the thread. The |
|
|
|
value can be either: |
|
|
|
• THREAD_SETTINGS_CPU_NO_ROTATION |
|
|
|
The thread can run on any listed processor, as determined by OS |
|
|
<cpu_rotation> |
scheduling. |
0 or 1 |
|
|
• THREAD_SETTINGS_CPU_RR_ROTATION |
|
|
|
The thread will be assigned a CPU from the list in |
|
|
|
Only applies to platforms that support controlling CPU core affinity (see the |
|
|
|
|
||
|
|
|
Table 19.1 XML Tags for ThreadSettings_t
Tags within |
|
|
Number |
|
Description |
of Tags |
|
<thread> |
|
||
|
|
Allowed |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A collection of flags used to configure threads of execution. Not all of these |
|
|
|
options may be relevant for all operating systems. May include these bits: |
|
|
|
• |
STDIO |
|
|
• |
FLOATING_POINT |
|
<mask> |
• |
REALTIME_PRIORITY |
0 or 1 |
|
• |
PRIORITY_ENFORCE |
|
|
It can also be set to a combination of the above bits by using the “or” symbol |
|
|
|
(|), such as STDIO|FLOATING_POINT. |
|
|
|
Default: MASK_DEFAULT |
|
|
|
|
|
|
|
Thread priority. The value can be specified as an unsigned integer or one of |
|
|
|
the following strings. |
|
|
|
• THREAD_PRIORITY_DEFAULT |
|
|
|
• THREAD_PRIORITY_HIGH |
|
|
|
• THREAD_PRIORITY_ABOVE_NORMAL |
|
|
|
• THREAD_PRIORITY_NORMAL |
|
|
|
• THREAD_PRIORITY_BELOW_NORMAL |
|
|
|
• THREAD_PRIORITY_LOW |
|
|
|
When using an unsigned integer, the allowed range is |
|
|
<priority> |
When thread priorities are configured using XML, the values are considered |
0 or 1 |
|
|
native priorities. |
|
|
|
Example: |
|
|
|
<thread> |
|
|
|
|
<mask>STDIO|FLOATING_POINT</mask> |
|
|
|
<priority>10</priority> |
|
|
|
<stack_size>THREAD_STACK_SIZE_DEFAULT</stack_size> |
|
|
</thread> |
|
|
|
When the XML file is loaded using the Java API, the priority is a native |
|
|
|
priority, not a Java thread priority. |
|
|
|
|
|
|
|
Thread stack size, specified as an unsigned integer or set to the string |
|
|
<stack_size> |
THREAD_STACK_SIZE_DEFAULT. The allowed range is platform- |
0 or 1 |
|
|
dependent. |
|
|
|
|
|
|

Chapter 20
This chapter describes how Connext manages the memory for the data samples that are sent by
DataWriters and received by DataReaders.
20.1
To configure
Table 20.1
Property |
Description |
|
|
|
|
|
If the serialized size of the sample is <= pool_buffer_max_size: |
|
The buffer is obtained from a |
|
DataWriter is deleted. |
|
If the serialized size of the sample is > pool_buffer_max_size: |
dds.data_writer. |
The buffer is dynamically allocated from the heap and returned to the |
history.memory_manager. |
heap when the sample is removed from the DataWriter’s queue. |
fast_pool.pool_buffer_max_size |
Default: |
|
allocated pool; the buffer size is the maximum serialized size of the sam- |
|
ples, as returned by the type plugin get_serialized_sample_max_size() |
|
operation. |
|
|
|
|
|
Only supported when using the Java API. |
|
Defines the minimum size of the buffer that will be used to serialize |
|
samples. |
dds.data_writer. |
When a DataWriter is created, the Java layer will allocate a buffer of this |
history.memory_manager. |
size and associate it with the DataWriter. |
java_stream.min_size |
Default: |
|
serialized size of a sample, as returned by the type plugin |
|
get_serialized_sample_max_size() operation |
|
See |
|
|
Table 20.1
Property |
Description |
|
|
|
|
|
|
|
|
Only supported when using the Java API. |
|
|
A boolean value that controls the growth of the serialization buffer. |
|
dds.data_writer. |
If set to 0 (default): The buffer will not be reallocated unless the serialized |
|
size of a new sample is greater than the current buffer size. |
||
history.memory_manager. |
||
If set to 1: The buffer will be reallocated with each new sample to a |
||
java_stream.trim_to_size |
||
smaller size in order to just fit the sample serialized size. The new size |
||
|
||
|
cannot be smaller than min_size. |
|
|
See |
|
|
|
20.1.1Memory Management without Batching
When the write() operation is called on a DataWriter that does not have batching enabled, the DataWriter serializes (marshals) the input sample and stores it in the DataWriter’s queue (see Figure 20.1). The size of this queue is limited by initial_samples/max_samples in the RESOURCE_LIMITS QosPolicy (Section 6.5.20).
Each sample in the queue has an associated serialization buffer in which the DataWriter will serialize the sample. This buffer is either obtained from a
The default value of pool_buffer_max_size is
20.1.2Memory Management with Batching
When the write() operation is called on a DataWriter for which batching is enabled (see BATCH QosPolicy (DDS Extension) (Section 6.5.2)), the DataWriter serializes (marshals) the input sample into the current batch buffer (see Figure 20.2). When the batch is flushed, it is stored in the DataWriter’s queue along with its samples. The DataWriter queue can be sized based on:
❏The number of samples, using initial_samples/max_samples (both set in the RESOURCE_LIMITS QosPolicy (Section 6.5.20))
❏The number of batches, using initial_batches/max_batches (both set in the DATA_WRITER_RESOURCE_LIMITS QosPolicy (DDS Extension) (Section 6.5.4))
❏Or a combination of max_samples and max_batches
When batching is enabled, the memory associated with the batch buffers always comes from a
❏If max_data_bytes is a finite value, the size of the buffer is the minimum of this value and the maximum serialized size of a sample (max_sample_serialized_size) as returned by the
❏Otherwise, the size of the buffer is calculated by (batch.max_samples * max_sample_serialized_size).
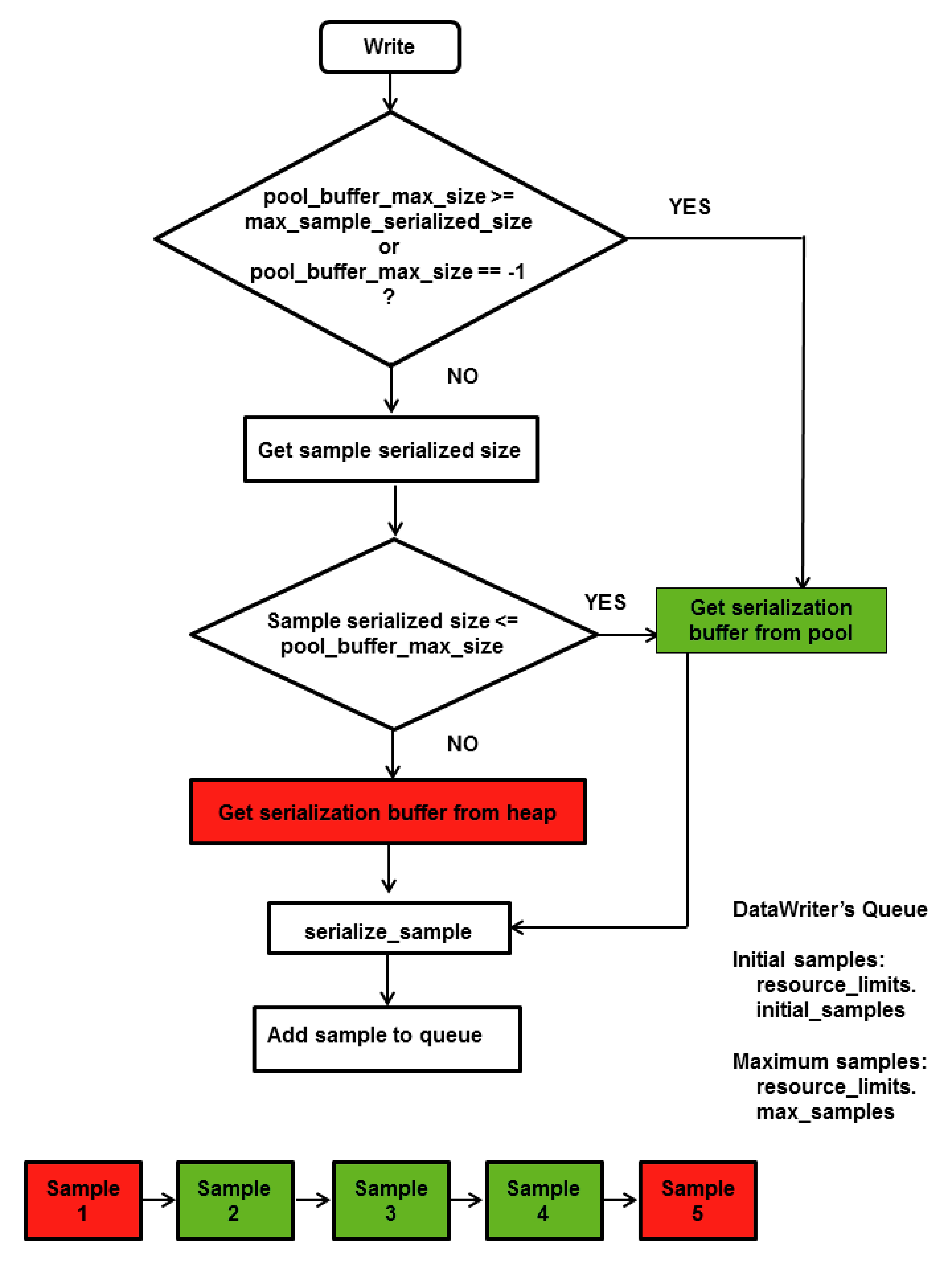
Figure 20.1 DataWriter Actions when Batching is Disabled
Notice that for
Note: The value of the property dds.data_writer.history.memory_manager.fast_pool.pool_buffer_max_size is ignored by
DataWriters with batching enabled.
20.1.3
When the Java API is used, Connext allocates a Java buffer per DataWriter; this buffer is used to serialize the Java samples published by the DataWriters. After a sample is serialized into a Java buffer, the result is copied into the underlying native buffer described in Memory Management without Batching (Section 20.1.1) and Memory Management with Batching (Section 20.1.2).
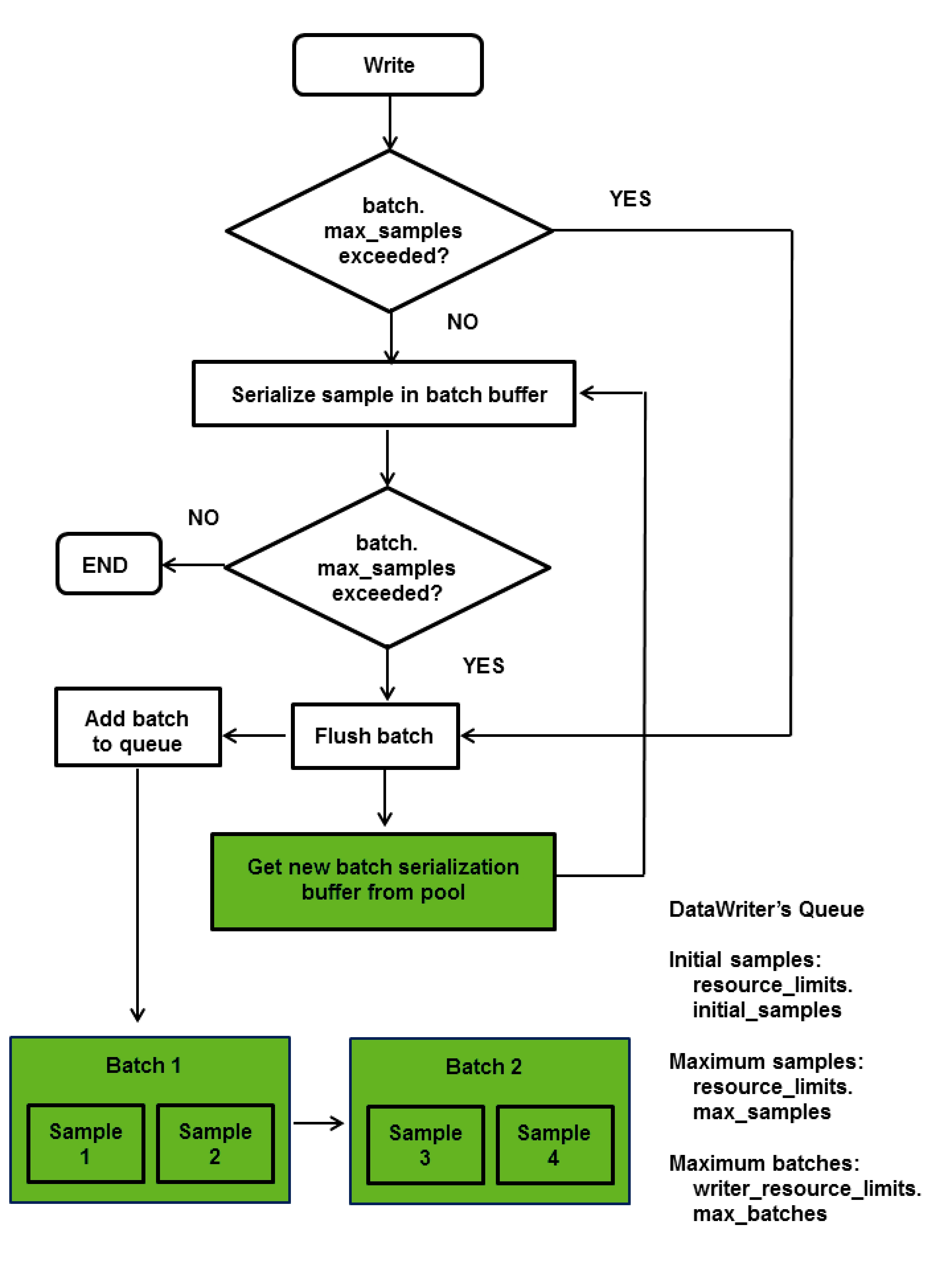
Figure 20.2 DataWriter Actions when Batching is Enabled
You can use the following two DataWriter properties to control memory allocation for the Java buffers that are used for serialization (see Table 20.1):
❏dds.data_writer.history.memory_manager.java_stream.min_size
❏dds.data_writer.history.memory_manager.java_stream.trim_to_size
20.1.4
Large samples are samples with a large maximum size relative to the memory available to the application. Notice the use of the word maximum, as opposed to actual size.
As described in Memory Management without Batching (Section 20.1.1), by default, the middleware preallocates the samples in the DataWriter queue to their maximum serialized size. This may lead to high
For example, let’s consider a video conferencing application:
struct VideoFrame { boolean keyFrame;
sequence<octet,1024000> data;
};
The above IDL definition can be used to work with video streams.
Each frame is transmitted as a sequence of octets with a maximum size of 1 MB. In this example, the video stream has two types of frames:
A video stream consists of a sequence of frames in which
For our use case, let’s assume that
Although the actual size of the frames sent by the Connext application is usually significantly smaller than 1 MB since they are
Using some
The following XML file shows how to optimize the memory usage for the previous example (rather than focusing on efficient usage of the available network bandwidth).
<?xml version="1.0"?>
<dds
<qos_profile name="ReliableLargeDataProfile" is_default_qos="true">
<datawriter_qos> <resource_limits>
<max_samples>32</max_samples>
<!— No need to
</resource_limits> <property>
<value>
<name> dds.data_writer.history.memory_manager.fast_pool.pool_buffer_max_size
</name>
<value>33792</value>
</element>

frames with a size smaller than or equal to 33 KB. When an
<name> dds.data_writer.history.memory_manager.java_stream.min_size
</name>
<value>33792</value>
</element>
<element>
<name> dds.data_writer.history.memory_manager.java_stream.trim_to_size
</name>
<value>1</value>
</element>
</value>
</property> </datawriter_qos>
</qos_profile> </qos_library>
</dds>
Working with large data samples will likely require throttling the network traffic generated by single samples. For additional information on shaping network traffic, see FlowControllers (DDS Extension) (Section 6.6).
20.2
The data samples received by a DataReader are deserialized (demarshaled) and stored in the DataReader’s queue (see Figure 20.3). The size of this queue is limited by initial_samples/ max_samples in the RESOURCE_LIMITS QosPolicy (Section 6.5.20).
20.2.1Memory Management for DataReaders Using Generated
Figure 20.3 shows how samples are processed and added to the DataReader’s queue.
The RTPS DATA samples received by a DataReader can be either batch samples or individual samples. The DataReader queue does not store batches. Therefore, each one of the samples within a batch will be deserialized and processed individually.
When the DataReader processes a new sample, it will deserialize it into a sample obtained from a
struct VideoFrame { boolean keyFrame;
sequence<octet,1024000> data;
};
Currently, there are no configuration settings to change the default memory allocation policy for DataReaders using type plugin code generated by rtiddsgen.
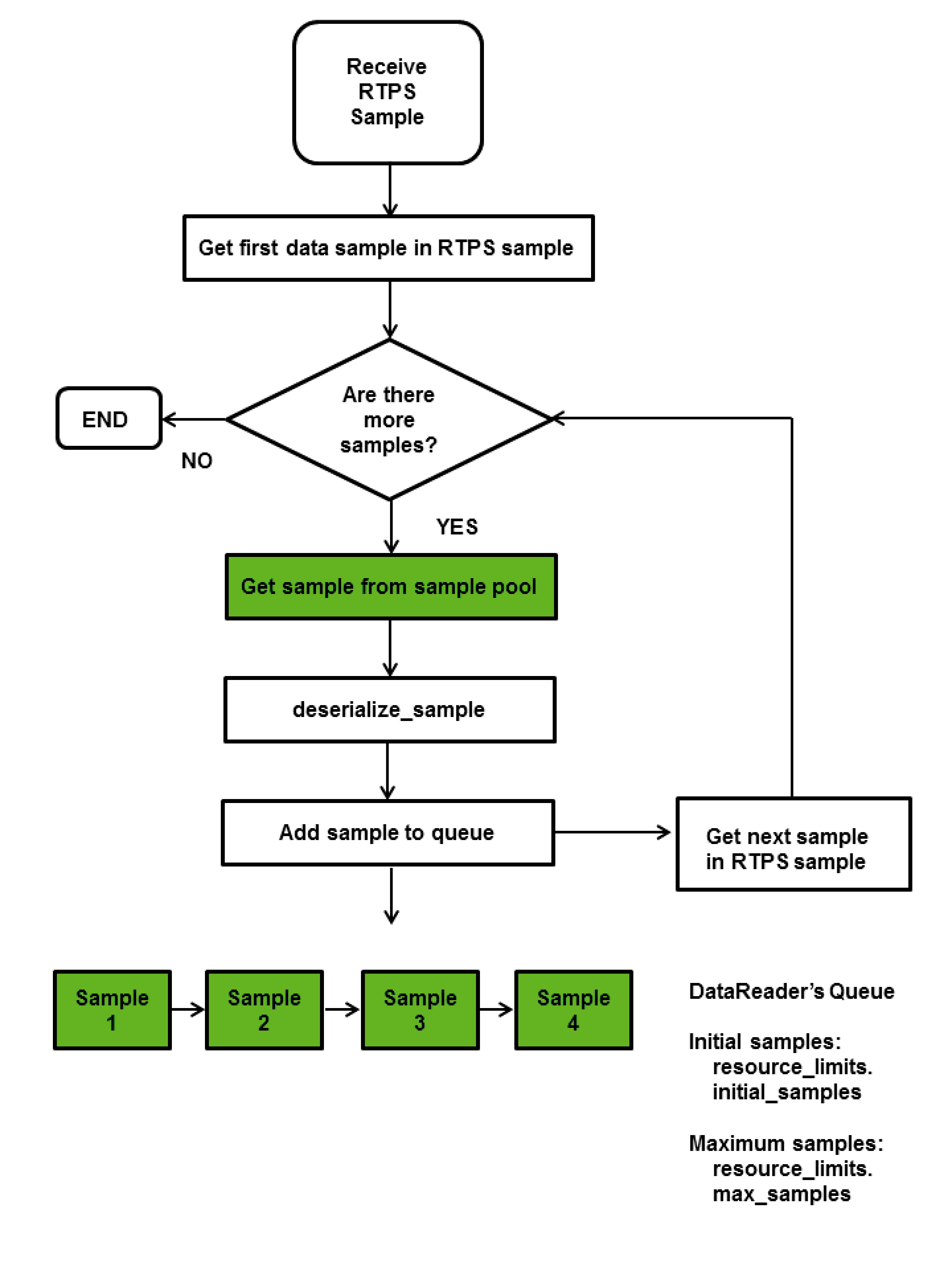
Figure 20.3 Adding Samples to DataReader’s Queue
20.2.2
When the Java API is used with DataReaders using generated
You can use the DataReader properties in Table 20.2 to control memory allocation for the Java buffer used for deserialization:
Table 20.2
Property |
Description |
|
|
|
|
|
|
|
|
Only supported when using the Java API. |
|
|
Defines the minimum size of the buffer used for the serialized data. |
|
dds.data_reader. |
When a DataReader is created, the Java layer will allocate a buffer of this size |
|
history.memory_manager. |
and associate it with the DataReader. |
|
java_stream.min_size |
Default: |
|
|
||
|
size of a sample, as returned by the type plugin method |
|
|
get_serialized_sample_max_size(). |
|
|
|
|
|
Only supported when using the Java API. |
|
dds.data_reader. |
A Boolean value that controls the growth of the deserialization buffer. |
|
If set to 0 (the default), the buffer will not be |
||
history.memory_manager. |
||
java_stream.trim_to_size |
size of a new sample is greater than the current buffer size. |
|
If set to 1, the buffer will be |
||
|
||
|
fit the sample serialized size. The new size cannot be smaller than min_size. |
|
|
|
20.2.3Memory Management for DynamicData DataReaders
Unlike DataReaders that use generated
A DynamicData sample stored in the DataReader’s queue has an associated underlying buffer that contains the serialized representation of the sample. The buffer is allocated according to the configuration provided in the serialization member of the DynamicDataProperty_t used to create the DynamicDataTypeSupport (see Interacting Dynamically with User Data Types (Section 3.8)).
struct DDS_DynamicDataProperty_t {
...
DDS_DynamicDataTypeSerializationProperty_t serialization;
}
struct DDS_DynamicDataTypeSerializationProperty_t {
...
DDS_UnsignedLong max_size_serialized; DDS_UnsignedLong min_size_serialized; DDS_Boolean trim_to_size;
}
Table 20.3 describes the members of DDS_DynamicDataTypeSerializationProperty_t.
Table 20.3 struct DDS_DynamicDataTypeSerializationProperty_t
Name |
Description |
|
|
|
|
|
Defines the maximum size of the buffer that will contain the serialized sample. |
|
max_size_serialized |
Default: 0xFFFFFFFF, indicates that Connext must use the maximum serialized size |
|
|
of a sample according to the type information. Except in very specific scenarios, the |
|
|
value max_size_serialized should always be the default. |
|
|
|
|
|
Defines the minimum size of the buffer used to hold the serialized data in a |
|
min_size_serialized |
DynamicData object. |
|
Default: 0xFFFFFFFF, a sentinel that indicates that this value must be equal to the |
||
|
||
|
value specified in max_size_serialized. |
|
|
|
Table 20.3 struct DDS_DynamicDataTypeSerializationProperty_t
Name |
Description |
Controls the growth of the serialization buffer in a DynamicData object.
If set to 0 (default): The buffer will not be reallocated unless the serialized size of the
incoming sample is greater than the current buffer size.
trim_to_size
If set to 1: The buffer of a DynamicData object obtained from the sample pool will be
Figure 20.4 shows how samples are allocated in the DataReader queue for DynamicData
DataReaders.
Figure 20.4 How samples are Allocated in DataReader Queue for DynamicData DataReaders
20.2.5Memory Management for Fragmented Samples
When a DataWriter writes samples with a serialized size greater than the minimum of the largest transport message sizes across all transports installed with the DataWriter, the samples are fragmented into multiple RTPS fragment messages.
The different fragments associated with a sample are assembled in the DataReader side into a single buffer that will contain the sample serialized data after the last fragment is received.
By default, the DataReader keeps a pool of
The main disadvantage in
20.2.6
This section describes how to configure the DataReader side of the videoconferencing application introduced in
The following XML file can be used to optimize the memory usage in the previous example:
<?xml version="1.0"?>
<dds
<qos_profile name="ReliableLargeDataProfile" is_default_qos="true">
<datareader_qos> <history>
<kind>KEEP_ALL_HISTORY_QOS</kind> </history>
<resource_limits> <max_samples>32</max_samples>
<!— No need to
</resource_limits>
<reader_resource_limits>
1
</dynamically_allocate_fragmented_samples> </reader_resource_limits>
<property>
<value>
<name> dds.data_writer.history.memory_manager.java_stream.min_size
</name>
<value>33792</value>
</element>
<element>
<name> dds.data_writer.history.memory_manager.java_stream.trim_to_size
</name>
<value>1</value>
</element>
</value>
</property> </qos_profile>
</qos_library> </dds>

Chapter 21 Troubleshooting
This chapter contains tips on troubleshooting Connext applications. For an
This chapter contains the following sections:
❏What Version am I Running? (Section 21.1)
❏Controlling Messages from Connext (Section 21.2)
21.1What Version am I Running?
There are two ways to obtain version information:
❏By looking at the revision files, as described in Section 21.1.1.
❏Programmatically at run time, as described in Section 21.1.2.
21.1.1Finding Version Information in Revision Files
In the
(where x is a
For example:
Host Build 5.0.x rev 04 (0x04050200)
The revision files for Connext target libraries are in the same directory as the libraries (${NDDSHOME}/lib/<architecture>).
21.1.2Finding Version Information Programmatically
The methods in the NDDSConfigVersion class can be used to retrieve version information for the Connext product, the core library, and the C, C++ or Java libraries.
The version information includes four fields:
❏A major version number
❏A minor version number
❏A release number
❏A build number
Table 21.4 lists the available operations (they will vary somewhat depending on the programming language you are using; consult the API Reference HTML documentation for more information).
Table 21.1 NDDSConfigVersion Operations
|
Purpose |
|
Operation |
|
Description |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
get_product_version |
|
Gets version information for the Connext product. |
To |
retrieve |
version |
|
|
|
|
get_core_version |
|
Gets version information for the Connext core library. |
||||
information |
in |
a |
|
|
|
|
get_c_api_version |
|
Gets version information for the Connext C library. |
||||
structured format |
|
|
||||
|
|
|
|
|||
|
|
|
|
get_cpp_api_version |
|
Gets version information for the Connext C++ library. |
|
|
|
|
|
|
|
To |
retrieve |
version |
|
|
Converts the version information for each library into a |
|
information |
in string |
to_string |
|
string. The strings for each library are put in a single |
||
format |
|
|
|
|
||
|
|
|
|
|||
The get_product_version() operation |
returns a reference to a structure of type |
|||||
DDS_ProductVersion_t: |
|
|
||||
struct NDDS_Config_ProductVersion_t { DDS_Char major;
DDS_Char minor; DDS_Char release; DDS_Char revision;
};
The other get_*_version() operations return a reference to a structure of type NDDS_Config_LibraryVersion_t:
struct NDDS_Config_LibraryVersion_t { DDS_Long major;
DDS_Long minor; char release; DDS_Long build;
};
The to_string() operation returns version information for the Connext core, followed by the C and C++ API libraries, separated by hyphens. For example:
Core |
C API: |
C++ API: |
major: 1 |
major: 1 |
major: 1 |
minor: 0 |
minor: 0 |
minor: 0 |
release: g |
release: g |
release:g |
build: 0 |
build: 1 |
build: 0 |
21.2Controlling Messages from Connext
Connext provides several types of messages to help you debug your system and alert you to errors during run time. You can control how much information is reported and where it is logged.
How much information is logged is known as the verbosity setting. Table 21.2 describes the increasing verbosity levels.
Table 21.2 Message Logging Verbosity Levels
Verbosity |
|
|
(NDDS_CONFIG_ |
Description |
|
LOG_VERBOSITY_*) |
|
|
|
|
|
SILENT |
No messages will be logged. (lowest verbosity) |
|
|
|
|
ERROR (default level |
Log only |
|
with how Connext is functioning. The most common cause of this type of error |
||
for all categories) |
is an incorrect configuration. |
|
|
||
|
|
|
|
Additionally log warning messages. A warning indicates that Connext is |
|
WARNING |
taking an action that may or may not be what you intended. Some |
|
|
configuration information is also logged at this verbosity to aid in debugging. |
|
|
|
|
STATUS_LOCAL |
Additionally log verbose information about the lifecycles of local Connext |
|
objects. |
||
|
||
|
|
|
STATUS_REMOTE |
Additionally log verbose information about the lifecycles of remote Connext |
|
objects. |
||
|
||
|
|
|
STATUS_ALL |
Additionally log verbose information about periodic activities and Connext |
|
threads. (highest verbosity) |
||
|
||
|
|
Note that the verbosities are cumulative: logging at a high verbosity means also logging all lower verbosity messages. If you change nothing, the default verbosity will be set to
NDDS_CONFIG_LOG_VERBOSITY_ERROR.
Caution: Logging at high verbosities can be detrimental to your application's performance. You should generally not set the verbosity above NDDS_CONFIG_LOG_VERBOSITY_WARNING, unless you are debugging a specific problem.
You will typically change the verbosity of all of Connext at once. However, in the event that such a strategy produces too much output, you can further discriminate among the messages you would like to see. The types of messages logged by Connext fall into the categories listed in Table 21.3; each category can be set to a different verbosity level.
Table 21.3 Message Logging Categories
Category |
|
(NDDS_CONFIG_ |
Description |
LOG_CATEGORY_*) |
|
|
|
PLATFORM |
Messages about the underlying platform (hardware and OS). |
|
|
COMMUNICATION |
Messages about data serialization and deserialization and network traffic. |
|
|
DATABASE |
Messages about the internal database of Connext objects. |
|
|
ENTITIES |
Messages about local and remote entities and the discovery process. |
|
|
API |
Messages about Connext’s API layer (such as method argument validation). |
|
|
The methods in the NDDSConfigLogger class can be used to change verbosity settings, as well as the destination for logged messages. Table 21.4 lists the available operations; consult the API Reference HTML documentation for more information.
Table 21.4 NDDSConfigLogger Operations
Purpose |
Operation |
Description |
|
|
|
|
|
|
|
|
Gets the current verbosity. |
Change Verbosity for all |
get_verbosity |
If |
Categories |
|
highest verbosity of any category. |
|
set_verbosity |
Sets the verbosity of all categories. |
|
|
|
Table 21.4 NDDSConfigLogger Operations
Purpose |
|
Operation |
Description |
|
|
|
|
|
|
|
|
|
|
|
Change Verbosity for |
a |
get_verbosity_by_category |
Gets/Sets the verbosity for a specific category. |
|
Specific Category |
|
set_verbosity_by_category |
||
|
|
|||
|
|
|
|
|
|
|
|
Returns the file to which messages are being |
|
|
|
get_output_file |
logged, or NULL for the default destination |
|
|
|
|
(standard output on most platforms). |
|
|
|
|
|
|
|
|
set_output_file |
Redirects future logged messages to the specified |
|
Change Destination |
of |
file (or NULL to return to the default). |
||
|
||||
Logged Messages |
|
get_output_device |
Returns the logging device installed with the |
|
|
|
logger. |
||
|
|
|
||
|
|
|
|
|
|
|
|
Registers a specified logging device with the log- |
|
|
|
set_output_device |
||
|
|
|
||
|
|
|
|
|
|
|
get_print_format |
Gets/Sets the current message format that |
|
Change Message Format |
|
Connext is using to log diagnostic information. |
||
set_print_format |
||||
|
|
|||
|
|
|
||
|
|
|
|
|
21.2.1Format of Logged Messages
You can control the amount of information in each message with the set_print_format() operation. The format options are listed in Table 21.5.
Table 21.5 Message Formats
Message Format |
|
|
(NDDS_CONFIG_LOG_ |
Description |
|
PRINT_FORMAT_*) |
|
|
|
|
|
DEFAULT |
Message, method name, and activity context. |
|
|
|
|
TIMESTAMPED |
Message, method name, activity context, and timestamp. |
|
|
|
|
VERBOSE |
Message with all available context information (includes thread |
|
identifier, activity context). |
||
|
||
|
|
|
VERBOSE_TIMESTAMPED |
Message with all available context information and timestamp. |
|
|
|
|
DEBUG |
Information for internal debugging by RTI personnel. |
|
|
|
|
MINIMAL |
Message number, method name. |
|
|
|
|
MAXIMAL |
All available fields. |
|
|
|
Of course, you are not likely to recognize all of the method names; many of the operations that perform logging are deep within the implementation of Connext. However, in case of errors, logging will typically take place at several points within the call stack; the output thus implies the stack trace at the time the error occurred. You may only recognize the name of the operation that was the last to log its message (i.e., the function that called all the others); however, the entire stack trace is extremely useful to RTI support personnel in the event that you require assistance.
You may notice that many of the logged messages begin with an exclamation point character. This convention indicates an error and is intended to be reminiscent of the negation operator in many programming languages. For example, the message “!create socket”in the second line of the above stack trace means “cannot create socket.”
21.2.1.1Timestamps
Reported times are in seconds from a
microseconds. Enabling timestamps will result in some additional overhead for clock access for every message that is logged.
Logging of timestamps is not enabled by default. To enable it, use NDDS_Config_Logger method set_print_format().
21.2.1.2Thread identification
Thread identification strings uniquely identify for active thread when a message is output to the console. A thread may be a user (application) thread or one of several types of internal threads. The possible thread types are:
❏user thread: U<threadID>
❏receive thread: rR<thread index><domain ID><app ID>, where thread index is an integer identifying this receive thread
❏event thread: revt<domain ID><app ID>
❏asynchronous publisher thread: rDsp
Logging of thread IDs are not enabled by default. To enable it, use NDDS_Config_Logger method set_print_format().
21.2.1.3Hierarchical Context
Many middleware APIs now store information in
The context field is output by default.
21.2.1.4Explanation of Context Strings
❏ Domain context
Dxxyy
In this case, xx = participant ID, yy = domain #. For example, D0149 means “domain 49, participant 01.”
❏Entity context
Operation on an entity will specify the object and a numeric ID, such as Writer(001A1). The name will be one of the following:
String |
Object type |
|
|
Participant |
DDS_DomainParticipant |
|
|
Pub |
DDS_Publisher |
|
|
Sub |
DDS_Subscriber |
|
|
Topic |
DDS_Topic |
|
|
Writer |
DDS_<*>DataWriter |
|
|
Reader |
DDS_<*>DataReader |
|
|
❏Topic Context
T=Hello refers to topic "Hello."
The operations which report context include:
String |
Operation |
|
|
|
|
Entity operations |
|
|
|
ENABLE |
Entity::enable |
|
|
GET_QOS |
Entity::get_qos |
|
|
SET_QOS |
Entity::set_qos |
|
|
GET_LISTENER |
Entity::get_listener |
|
|
SET_LISTENER |
Entity::set_listener |
|
|
Factory operations (DP Factory, Participant, Pub/Sub) |
|
|
|
CREATE <Entity> |
Factory::create_<entity> |
|
|
DELETE <Entity> |
Factory::delete_<entity> |
|
|
GET_DEFAULT_QOS <Entity> |
Factory::get_default_<entity>_qos |
|
|
SET_DEFAULT_QOS <Entity> |
Factory::set_default_<entity>_qos |
|
|
|
|
|
|
GET_PUBS |
Participant::get_publishers |
|
|
GET_SUBS |
Participant::get_subscribers |
|
|
LOOKUP Topic(<name>) |
Participant::lookup_topicdescription |
|
|
LOOKUP FlowController(<name>) |
Participant::lookup_flowcontroller |
|
|
IGNORE <Entity>(<host ID>) |
Participant::ignore_<entity> |
|
|
21.2.2Configuring Logging via XML
Logging can also be configured using the DomainParticipantFactory’s LOGGING QosPolicy (DDS Extension) (Section 8.4.1) with the tags, <participant_factory_qos><logging>. The fields in the LoggingQosPolicy are described in XML using a
struct DDS_LoggingQosPolicy { NDDS_Config_LogVerbosity verbosity; NDDS_Config_LogCategory category; NDDS_Config_LogPrintFormat print_format; char * output_file;
};
The equivalent representation in XML:
<participant_factory_qos> <logging>
<verbosity></verbosity>
<category></category> <print_format></print_format> <output_file></output_file>
</logging> </participant_factory_qos>
The attribute <is_default_participant_factory_profile> can be set to true for the <qos_profile> tag to indicate from which profile to use <participant_factory_qos>. If multiple QoS profiles have <is_default_participant_factory_profile> set to true, the last profile with <is_default_participant_factory_profile> set to true will be used.
If none of the profiles have set <is_default_participant_factory_profile> to true, the profile with <is_default_qos> set to true will be used.
In the following example, DefaultProfile2 will be used:
<dds
<qos_library name="DefaultLibrary"> <qos_profile name="DefaultProfile1"
is_default_participant_factory_profile ="true"> <participant_factory_qos>
<logging>
<verbosity>ALL</verbosity>
<category>ENTITY</category> <print_format>MAXIMAL</print_format> <output_file>LoggerOutput1.txt</output_file>
</logging> </participant_factory_qos>
</qos_profile>
<qos_profile name="DefaultProfile2" is_default_participant_factory_profile ="true"> <participant_factory_qos>
<logging>
<verbosity>WARNING</verbosity>
<category>API</category> <print_format>VERBOSE_TIMESTAMPED</print_format> <output_file>LoggerOutput2.txt</output_file>
</logging> </participant_factory_qos>
</qos_profile>
<qos_profile name="DefaultProfile3" is_default_qos="true"> <participant_factory_qos>
<logging>
<verbosity>ERROR</verbosity>
<category>DATABASE</category> <print_format>VERBOSE</print_format> <output_file>LoggerOutput3.txt</output_file>
</logging> </participant_factory_qos>
</qos_profile> </qos_library>
</dds>
Note: The LoggingQosPolicy is currently the only QoS policy that can be configured using the <participant_factory_qos> tag.
21.2.3Customizing the Handling of Generated Log Messages
By default, the log messages generated by Connext are sent to the standard output. You can redirect the log messages to a file by using the set_output_file() operation,
To further customize the management of the generated log messages, you can use the Logger’s set_output_device() operation to install a
Connext will call the write() operation to write a new log message to the input device. The log message provides the text and the verbosity corresponding to the message.
Connext will call the close() operation when the logging device is uninstalled.
Note: It is not safe to make any calls to the Connext core library including calls to
DDS_DomainParticipant_get_current_time() from any of the logging device operations.
For additional details on
Index, Part 3
A
accept_unknown_peers
ACKNACK messages
B
batching small samples
bundling messages
C
categories of messages
COMMUNICATION message category
CPU core affinity
D
database cleanup thread
debugging error messages
discovery debugging
endpoint phase
endpoint readers/writers
domain_id_gain
operations on
E
endpoint discovery
environment variables NDDS_DISCOVERY_PEERS
F
framing Heartbeat
G
get_builtin_subscriber()
GUID (Globally Unique ID)
H
HB messages. See heartbeats. heartbeat_period
controlling
how many resent
types of
diagram
depth
I
ignore_participant()
K
keep duration
L
logged error messages
M
matching writers and readers
(RtpsReliableWriterProtocol_t)
max_nack_response_delay (DataWriterProtocol QoS)
message bundling
ports for
definition
ports used
N
NACKs
operations on
P
packet loss
participant DATA messages
(DiscoveryConfig QoS)
ParticipantBuiltinTopicData
PLATFORM message category
PRSTDataReader
PRSTDataWriter
Q
QoS
DataWriterProtocol
for
queue depths
R
receive queue
size
blocking time
repair packages
controlling
basic behavior diagram
rtps_app_id
S
samples
resending
blocking time
size
send window
SILENT verbosity
T
U
unicast
ports used
ports for
V
verbosity
W
WARNING verbosity
blocked send queue