4. Data Integration: Combining Different Data Domains¶
In chapters Routing Data: Connecting and Scaling Systems and Controlling Data: Processing Data Streams we showed how Routing Service is a powerful solution to scale and aggregate DDS systems. You can define data flows between publication and subscription Topics, and also perform stream processing using a custom Processor.
Up to this point we have shown these capabilities only in the presence of DDS data sources and destinations. However, Routing Service can provide the same capabilities for any other data technology and protocol through the concept of an Adapter, which makes Routing Service a suitable framework for data integration.
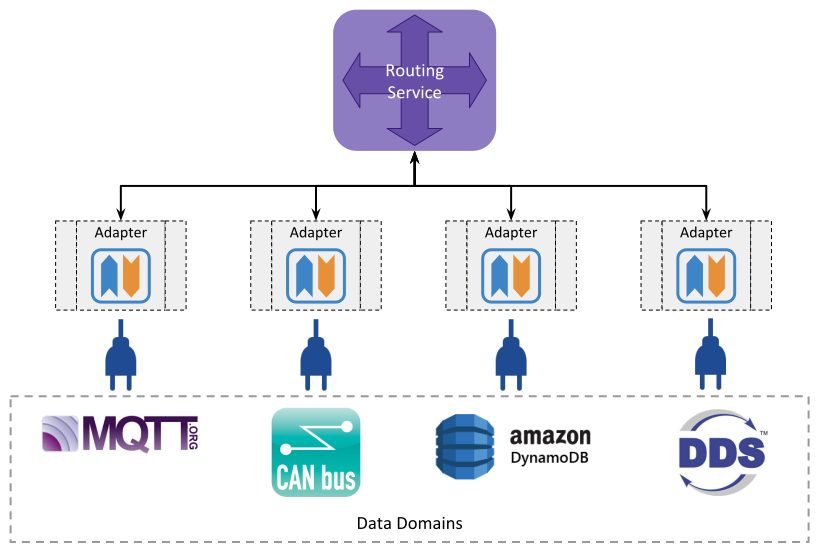
Figure 4.1 Data Integration in Routing Service¶
An Adapter is a pluggable component that allows you to access any data domain pertaining to any technology. Adapters provide a connection point to data domains so the information can flow back and forth to Routing Service. The main Adapter interfaces are:
Plugin: Entry point to the custom implementation. It consists of a creation method that Routing Service can call to instantiate the Adapter implementation. (see Plugin Management).
Connection: Entity responsible for accessing a concrete data domain. (see Connection). For example, a socket connection, database connection, or DomainParticipant. The Connection is the factory of StreamReader and StreamWriter.
StreamReader: Entity responsible for reading data streams from a concrete data domain and with a single Input.
StreamWriter: Entity responsible for writing data streams to a concrete data domain and associated with a single Output.
Figure 4.2 illustrates the concept of the Adapter and how it fits within the Routing Service entity model.
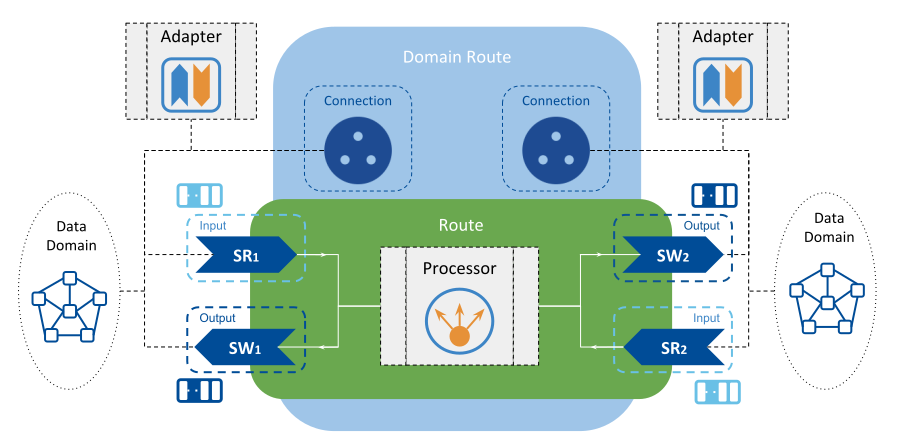
Figure 4.2 Adapter concept¶
Routing Service relies on concrete Adapter implementations to read and write data streams as part of the configured data flows. Similar to the TopicRoute object presented in Routing a Topic between two different domains, a Route represents a generalization of a TopicRoute whose Inputs and Outputs can interact with any data domain.
Each Input and Output are attached to a Connection, which through the underlying Adapter connection entity creates appropriate StreamReaders and StreamWriters, respectively. These StreamReaders and StreamWriters provide read and write access to data streams, respectively.
Note
All the following sections require you to be familiar with the routing concepts explained in Routing Data: Connecting and Scaling Systems. We also recommended becoming familiar with Controlling Data: Processing Data Streams. This section requires software programming knowledge in C/C++, understanding of CMake, and shared library management.
4.1. Unified Data Representation¶
Routing Service architecture allows all the data-related components such as Adapter, Processor, and Transformation to interoperate and coexist without knowing details of each other. Routing Service achieves this by defining a unified data representation that all components are required to use.
The unified data representation model is provided by DynamicData, a concept presented in DynamicData as a Data Representation Model. Routing Service imposes DynamicData as the data interface for all the components that have to deal with data streams. This contract for the unified data representation is the key element that enables data integration in Routing Service. Therefore, the main responsibility of an Adapter implementation is to provide a translation between the domain-specific data representation to DynamicData and vice versa.
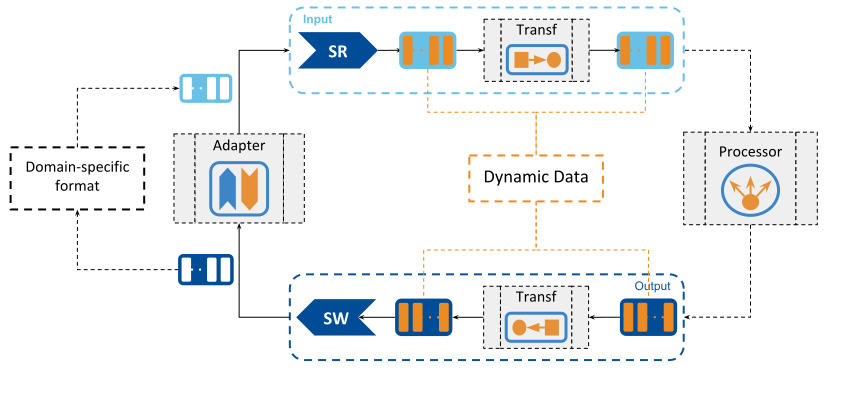
Figure 4.3 Unified Data Representation Model¶
In Figure 4.3, you can see all the data-related components interacting with each other independently of the domain-specific format of the data. All the data streams that flow across different components are presented as streams of DynamicData objects.
The following sections will guide you through an example that implements an Adapter that manipulates data from a file system. We will cover each step necessary to implement a custom Adapter and explain the purpose of each entity.
4.2. Integrating a File-Based Domain¶
This section will guide you through an example of how to implement a custom
Adapter to integrate with a non-DDS technology. The example shows how
to feed data stored in a set of CSV files back and forth between a
DDS domain. The file integration example is shown in
Figure 4.4.
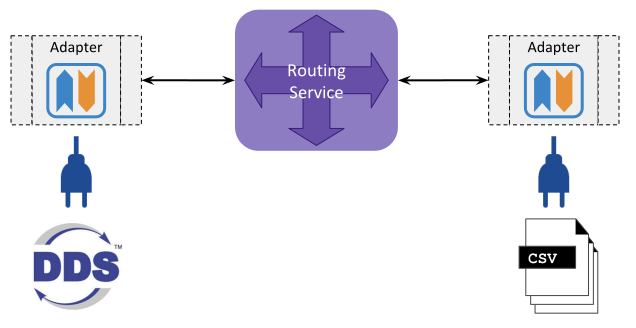
Figure 4.4 Example of data integration with a simple CSV file adapter¶
The example requires the implementation of a custom File Adapter, which provides the ability to read and write from a set files and convert their content into a stream of DynamicData samples.
Let’s review all the tasks you need to do to create a custom Adapter using the Example: Using a File Adapter. You can run it first to see it in action, but you can also run one step at a time. We explain each method.
4.2.1. Develop a Custom Adapter¶
As mentioned earlier, there are three main Adapter interfaces that must be implemented in order to provide access to, read, and write in a data domain. The most important step in designing a custom Adapter is to properly define the mapping between the adapter interfaces and specific entities or agents involved in the adapted data domain.
For this example, the mapping is very simple and consists of the following:
FileConnectionA simple factory class for FileStreamReader and FileStreamWriter.FileStreamReaderReads data from a single file and converts it to DynamicData.FileStreamWriterWrites data to a single file after being converted.
Both the FileStreamReader and FileStreamWriter process files in a custom
and consistent CSV format. For simplicity, they also expect and understand
the ShapeType only.
To better understand how these implementations work, we will split the focus into two separate concepts: reading and writing.
4.2.1.1. Implement a StreamReader for Reading Data¶
Reading from a data domain is the responsibility of the StreamReader. If you need to provide read access from your integrated data domain, you will need to implement this part of the Adapter, although it’s optional.
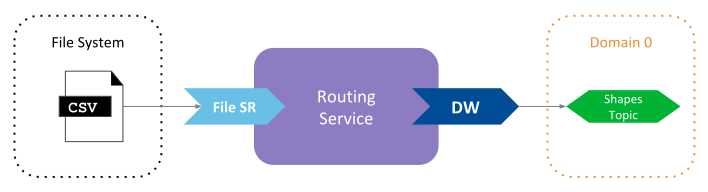
Figure 4.5 Routing from the file adapter to DDS¶
4.2.1.1.1. StreamReader Creation¶
Creating StreamReaders is the responsibility of the Connection. Hence the Adapter connection interface has an abstract method to implement the creation of a StreamReader. In this method you will find, among others, two important parameters:
Information about the Stream for which the StreamReader is created. This parameter has type
rti::routing::StreamInfoand contains:Stream name: This is the name provided as part of the Input configuration in the
<stream_name>tag.Type information: The registered name and
TypeCodeof the type of the input data stream. This information is encapsulated in aTypeInfostructure that contains:type_name`is the registered type name, as specified in the Input configuration in the<registered_type_name>tag.type_representationis the type definition asTypeCode, obtained either from XML or from Stream discovery. You can learn more details about type registration in Specifying Types.
A
StreamReaderListenerobject to provide asynchronous notifications about data available to read. This is an object provided by the Routing Service engine and the implementation can use it to signal the availability of input stream data and generate an event that’s notified to the owner Route.
4.2.1.1.2. Read Operation¶
FileStreamReader inherits from the rti::routing::adapter::DynamicDataStreamReader
interface, which has different abstract method overload to read data. Which
read operation version is called depends on the behavior of the Processor
set in the parent Route. The default forwarding Processor only calls the
basic take() and is the one our example implements.
When implementing a StreamReader, there are two main tasks that require special attention:
Providing an input stream of loaned DynamicData samples: All of the abstract read operations have two output parameters that shall hold the returned samples: list of user-data objects, and a list for info-data objects.
The
FileStreamReader::take()implementation reads oneCSVtext line at a time, parses each member, and converts it to aDynamicDataobject. In this case, the take operation can only read one sample at a time, and a heap-allocatedDynamicDatais provided as part of the output sample list. Note thatFileStreamReader::return_loan()frees this heap-allocated object. Thereturn_loan()operation is called automatically by the processor implementation when the sample loan from the take operation is no longer needed.Note that the take operation may also return a list of info-objects. These objects are meant to provide metadata associated with the user-data objects, such as reception timestamps or sequence numbers (which metadata is available depends on the data domain being adapted). Our example does not provide any metadata and hence the list is returned empty.
Notifying Routing Service about available data: This is an important yet subtle step involved in the data processing pipeline. If you look at the
Connection::create_stream_readeroperation you will notice that one of the input parameters is an object ofrti::routing::adapter::StreamReaderListener. This object is provided by the Routing Service engine and you can use it to indicate to Routing Service about the existence of data available from the StreamReader. WhenStreamReaderListener::on_data_availableis called, it will trigger the generation of aDATA_ON_INPUTSevent that will be dispatched to the Processor installed in the parent Route.In our example implementation, the
FileStreamReaderspawns a thread that reads a text line from the file and notifies theStreamReaderListenerright after, repeating this sequence in a loop until the whole file is read. Note that if we didn’t notify theStreamReaderListener, then the only way for Routing Service to read data would be through a periodic event (see Periodic and Delayed Action).
4.2.1.1.3. Read vs. Take¶
In the StreamReader you will find that there are always two parallel operations with
the same signature but different names: one called read() and one called
take(). Their behavior should be the same except for one main difference:
take() will return samples from a StreamReader only once, while read()
allows the same samples to be returned more than once.
In the DDS world, this is similar to the read and take operations of a DataReader.
While the behavior is the same in both of them, the take operation will remove
the samples from the DataReader’s cache (freeing space and preventing them from
being read again), while the read will leave the cache intact, simply marking
the samples with READ status.
4.2.1.2. Implement a StreamWriter for Writing Data¶
4.2.1.2.1. StreamWriter Creation¶
Creating StreamWriters is responsibility of of the Connection. Hence the Adapter
connection interface has an abstract method to implement the creation of a
StreamWriter. In this method you will find, among others, an important parameter
that identifies the Stream for which the StreamReader is created. This parameter
has type rti::routing::StreamInfo and its content and purpose are the same
as explained in the reading section above.
4.2.1.2.2. Write Implementation¶
Writing to a data domain is the responsibility of the StreamWriter. In our example,
FileStreamWriter inherits from the rti::routing::adapter::DynamicDataStreamWriter
interface, which has abstract methods to write data. Similar to the
reading part, the write operation is called by the installed Processor of the
parent Route. The default Processor calls the write operation, passing the
same samples read from the Inputs belonging to the same parent Route.
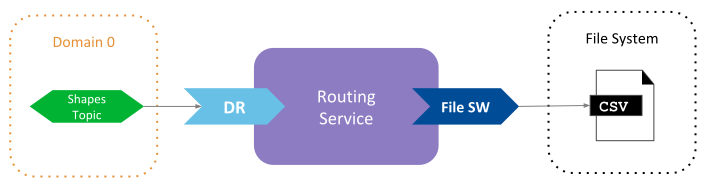
Figure 4.6 Routing from DDS to the file adapter¶
The abstract write operation receives two input parameters: a list of user-data DynamicData
objects, and a list of info-data objects of type SampleInfo. The info-data
list may be empty if no such information is available, though if it’s not,
then it has the same size as the user-data objects (a 1:1 mapping between
user-data and info-data objects).
Our FileStreamWrite::write() implementation is as simple as iterating over
the list of user-data objects and storing each of them in a file as a separate
CSV text line. However, our example does not use the info-data
list, though it could have used it to store, for example, the timestamps of the
samples.
Note
Implementing either the StreamReader and StreamWriter is optional. You can implement only the side that you need, that is, reading or writing.
See also
- Processor Events
Overview for the Processor API.
- Forwarding Processor
Details on the default forwarding Processor of the TopicRoutes.
4.2.3. Define a Configuration that Integrates DDS with the File Adapter¶
This is similar to the process explained in Routing a Topic between two different domains, except that we will use a Connection from the file adapter and only one DomainParticipant.
The example configuration file contains three different configurations that perform the integration in multiple combinations: file to DDS, DDS to file, and file to file. Note that all combinations could fit in a single Routing Service configuration, but we chose this model to better explain the adapter capabilities.
Below are the steps you need to follow.
4.2.3.1. Configure a Plugin Library¶
Within the root element of the XML configuration, you can define a plugin library element that contains the description of all the plugins that can be loaded by Routing Service. In our case, we define a plugin library with a single entry for our File Adapter plugin:
<plugin_library name="AdapterLib">
<processor_plugin name="FileAdapter">
<dll>fileadapter</dll>
<create_function>
FileAdapter_create_adapter_plugin
</create_function>
</processor_plugin>
</plugin_library>
The values specified for the name attributes can be set at your convenience
and they shall uniquely identify a plugin instance. We will use these names
later within the Connection to refer to this plugin. For the definition of our
ADAPTER plugin, we have specified two elements:
dllis the name of the shared library we specified in the build step. We just provide the library name so Routing Service will try to load it from the working directory, or assume that the library path is set accordingly.<create_function>is the name of the entry point (external function) that creates the plugin object, exactly as we defined in code with theRTI_ADAPTER_PLUGIN_CREATE_FUNCTION_DECLmacro.
Once we have the plugin defined in the library, we can move to the next step and define a Connection to the data domain of this plugin and the Route for the data flows for reading and writing.
Warning
When a name is specified in the <dll> element, Routing Service will automatically append a d suffix when running the debug version of Routing Service.
See also
- Plugins
Documentation about the
<plugin_library>element.- Plugin Management
For in-depth understanding of plugins.
4.2.3.2. Define a Connection Linked to the Adapter¶
As mentioned before, the Connection is the entity that enables access to a specific domain. To do so, the connection configuration shall refer to the Adapter plugin from which the underlying domain connection shall be created.
In this example, the connection configuration is defined as follows:
<connection name="FileConnection" plugin_name="AdapterLib::FileAdapter">
<registered_type name="ShapeType" type_name="ShapeType"/>
</connection>
There are three key elements that shall be set in a Connection configuration:
nameis the attribute that represents the name of the Connection entity. You can choose any name you like that helps you identify the data domain. This name will be used later by the Input and Output configurations to indicate from which Connection their underlying StreamReader and StreamWriter, respectively, are created. In our case, we named itFileConnection.plugin_nameis the attribute that must refer to the Adapter plugin from which the adapter connection is created. The value of this attribute must be the fully qualified name of the adapter plugin within the plugin library. The fully qualified name of the plugin is built using the values from thenameattributes of the plugin library and plugin element. In our case, the fully qualified name of the file adapter plugin is given byAdapterLib::FileAdapter.register_typeis an element tag that refers to a type definition (TypeCode) described in XML. This element has two attributes:nameto uniquely identify and register a type, andtype_refto point to an existing type in XML providing its fully qualified name. This element can optionally appear as many times as needed. You will need to use this element if your adapter does not support discovery and Routing Service cannot provide it through means of others adapters.Our file adapter example is quite basic. It only works with the
ShapeTypeand it requires the definition to be available in XML (you can find it under the<types>section).
4.2.3.3. Define the Data Flows that Read and Write from Your Adapter¶
Once a Connection to the adapted data domain is available, we need to define the Routes (or AutoRoutes) that will indicate how data streams flow from inputs to outputs. Inputs and Outputs are ultimately the entities that hold StreamReaders and StreamWriters that perform the reading and writing.
The file adapter example maps a separate CSV file for each stream. This
allows us to nicely perform a 1:1 mapping between a DDS Topic and a file stream.
In general, the expectation is that data that is read from an input’s StreamReader shall
originate from a single input stream. Likewise, the data written to an output’s
StreamWriter shall be sent to a single stream.
As mentioned at the beginning, this example provides three different Routing Service configurations, each with a single Route that defines the data flow for a specific combination. We will review each separately.
4.2.3.3.1. Routing from a File Stream to a DDS Topic¶
For this case we define a Route with:
An input attached to the file adapter (
<input>). This requires setting the following elements:connectionis the attribute that specifies from which Connection the underlying StreamReader is created. This attribute shall refer to the name of the Connection configuration exactly as it was set in itsnameattribute.<stream_name>is the stream name associated with this input. The impact of this value is specific to each Adapter implementation.<registered_type_name>indicates the associated type to the input stream. This ultimately translates into finding aTypeCodethat matches this name and providing it on the StreamReader creation as part of theStreamInfo. In our case, this name matches the value in thenameattribute of the<register_type>element in the connection configuration, so the type is the one defined in XML.<property>is the adapter-specific configuration in the form of name-value pairs. This content is passed directly as a set of name-value string pairs on the creation of the StreamReader. Our file StreamReader receives the name of theCSVfile from where data is read and a period at which the file is read.
An output attached to the built-in DDS adapter (
<dds_output>). This requires setting the following elements:participantis the attribute that specifies from which DomainParticipant the underlying StreamWriter is created. This attribute shall refer to the name of the DomainParticipant configuration exactly as it was set in itsnameattribute.<topic_name>is the name of the Topic the underlying DataWriter writes to.<registered_type_name>indicates the type associated with the Topic. This has the same behavior as for the input.
The XML is shown below.
<route>
<input connection="FileConnection">
<creation_mode>ON_DOMAIN_MATCH</creation_mode>
<stream_name>$(SHAPE_TOPIC)</stream_name>
<registered_type_name>ShapeType</registered_type_name>
<property>
<value>
<element>
<name>example.adapter.input_file</name>
<value>Input_$(SHAPE_TOPIC).csv</value>
</element>
<element>
<name>example.adapter.sample_period_sec</name>
<value>1</value>
</element>
</value>
</property>
</input>
<dds_output participant="DDSConnection">
<creation_mode>ON_ROUTE_MATCH</creation_mode>
<registered_type_name>ShapeType</registered_type_name>
<topic_name>$(SHAPE_TOPIC)</topic_name>
</dds_output>
</route>
4.2.3.3.2. Routing from a DDS Topic to a File Stream¶
For this case we define a Route with:
An input attached to the built-in DDS adapter (
<dds_input>). This requires setting the following elements:participantis the attribute that specifies from which DomainParticipant the underlying StreamReader is created. This attribute shall refer to the name of the DomainParticipant configuration exactly as it was set in itsnameattribute.<topic_name>is the name of the Topic the underlying DataReader reads data from.<registered_type_name>indicates the type associated with the Topic. This has the same behavior as for the input.
An output attached to the file adapter (
<output>). This requires setting the following elements:connectionis the attribute that specifies from which Connection the underlying StreamWriter is created. This attribute shall refer to the name of the Connection configuration exactly as it was set in itsnameattribute.<stream_name>is the stream name associated with this output. The impact of this value is specific to each Adapter implementation.<registered_type_name>: indicates the associated type to the output stream. This ultimately translates into finding aTypeCodethat matches this name and providing it on the StreamWriter creation as part of theStreamInfo. In our case, this name matches the value in thenameattribute of the<register_type>element in the connection configuration, so the type is the one defined in XML.<property>is the adapter-specific configuration in the form of name-value pairs. This content is passed directly as a set of name-value string pairs on the creation of the StreamWriter. Our file StreamWriter receives the name of theCSVfile where data is written.
The XML is shown below.
<route>
<dds_input participant="DDSConnection">
<creation_mode>ON_ROUTE_MATCH</creation_mode>
<registered_type_name>ShapeType</registered_type_name>
<topic_name>$(SHAPE_TOPIC)</topic_name>
</dds_input>
<output connection="FileConnection">
<creation_mode>ON_ROUTE_MATCH</creation_mode>
<registered_type_name>ShapeType</registered_type_name>
<stream_name>$(SHAPE_TOPIC)</stream_name>
<property>
<value>
<element>
<name>example.adapter.output_file</name>
<value>Output_$(SHAPE_TOPIC).csv</value>
</element>
</value>
</property>
</output>
</route>
4.2.3.3.3. Routing from a File Stream to Another File Stream¶
This scenario represents a case where both the input and output are attached to the file Adapter. Hence, the routing path of this configuration generates a flow from file to file. This scenario demonstrates the flexibility and abstraction of Routing Service working agnostically with data domains.
For this case, the Route configuration is defined with the same input configuration from Routing from a File Stream to a DDS Topic and the same output configuration from Routing from a DDS Topic to a File Stream.
The XML is shown below.
<route>
<input connection="FileConnection">
<creation_mode>ON_DOMAIN_MATCH</creation_mode>
<stream_name>$(SHAPE_TOPIC)</stream_name>
<registered_type_name>ShapeType</registered_type_name>
<property>
<value>
<element>
<name>example.adapter.input_file</name>
<value>Input_$(SHAPE_TOPIC).csv</value>
</element>
<element>
<name>example.adapter.sample_period_sec</name>
<value>1</value>
</element>
</value>
</property>
</input>
<output connection="FileConnection">
<creation_mode>ON_ROUTE_MATCH</creation_mode>
<registered_type_name>ShapeType</registered_type_name>
<stream_name>$(SHAPE_TOPIC)</stream_name>
<property>
<value>
<element>
<name>example.adapter.output_file</name>
<value>Output_$(SHAPE_TOPIC).csv</value>
</element>
</value>
</property>
</output>
</route>
Note
In all configurations, the Stream and Topic names are set using the XML
variable SHAPES_TOPIC. Its purpose is to allow reusing the same
configuration providing the actual desired name at run time. Another
alternative is to use an AutoRoute instead (see Routing a group of Topics).
4.3. Discovery Capabilities¶
Besides allowing integration with application or user data, the Adapter interface also provides data stream discovery capabilities.
Data communication frameworks may offer the ability to detect at run time which streams of user-data information are available and which endpoints (producers and consumers) are involved in the communication. Such is the case with DDS for example, which has a builtin discovery protocol to detect and notify applications of the presence of Topics.
Discovery is very useful because it eliminates deployment configuration complexity and allows dynamic systems where endpoints come and go to function autonomously. Routing Service can interoperate with discovery streams from any data domain through the Adapter by defining the concept of Stream discovery.
Stream discovery refers to the ability to detect the presence of streams of information that carry user data. User-data streams are categorized as:
publication or input streams: These are data streams that originate from producer endpoints and from which Routing Service receives data using StreamReaders. An input stream is read-only.
subscription or output streams: These are data streams that originate from the consumer endpoints and to which Routing Service sends data using StreamWriters. An output stream is write-only.
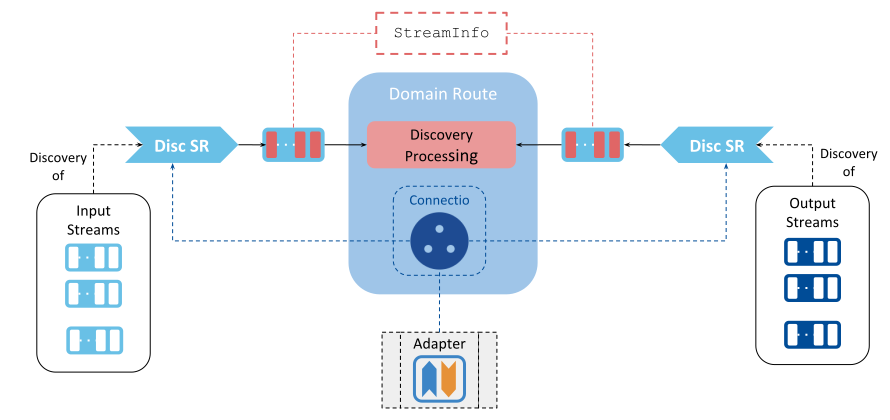
Figure 4.7 Integration with discovery capabilities of data domains¶
Routing Service uses stream discovery for two main activities:
Detecting the generation or disposal of streams that trigger the filter matching with AutoRoutes (see Routing a group of Topics) and the creation of StreamReaders and StreamWriters based on the input and output creation modes (see Creation Modes).
Receiving information about the type of the samples carried on the user-data streams. Routing Service needs to obtain the Stream type information (
TypeCode) beforehand in order to create the StreamReaders and StreamWriters. Stream discovery provides a channel for the reception of types.
The discovery information in Routing Service is represented in a unified way by defining a common type to describe Stream information: StreamInfo. Key information that a StreamInfo object provides:
Stream name: A unique identifier of a stream within a particular data domain connection (e.g., a Topic name in a DDS domain).
Alive or dispose: Whether or not the stream has any alive endpoints associated with it.
TypeInfo: Contains the unique identifier for the registration name of the type, as well as the type description as a
TypeCode.
Routing Service receives StreamInfo objects through the Discovery StreamReader interfaces from the Adapter. Namely, there are two discovery StreamReaders to read StreamInfo samples, one for each input and output stream.
Implementation of discovery in the Adapter is optional. The Connection is responsible for the provision of the Discovery StreamReaders and its interface has two abstract methods to retrieve them.
Routing Service calls these operations upon enabling the parent DataReader (typically at startup) and will use the returned StreamReaders (if any) to obtain the StreamInfo objects from them. Routing Service has a dedicated discovery thread to call the read and return loan operations from all discovery StreamReaders.
The next section shows an example of how to provide discovery information using the file Adapter.
4.3.1. Discovery in a File-Based Domain¶
When working with files on a file system, there are many ways in which discovery information can be useful. One of them is to provide notification about the creation and removal of files. Our file adapter example shows a basic way to recreate this.
The file adapter example implements only the input stream Discovery StreamReader. It provides information about which files are available to read and when the user StreamReaders are done reading them.
The class FileInputDiscoveryStreamReader inherits from the abstract class
rti::routing::adapter::DiscoveryStreamReader and represents the
implementation of the StreamReader that provides discovery information about
input streams.
The implementation of this class is similar to the user-data StreamReader. You will find
that the abstract take operation is implemented by returning a list of
rti::routing::StreamInfo objects. The implementation also uses an
rti::routing::adapter::StreamReaderListener object to notify Routing Service about
discovery information that is available to read.
The file FileInputDiscoveryStreamReader has two ways to generate StreamInfo
objects:
On class instantiation, which in this case occurs when Routing Service calls the
FileConnection::get_input_stream_discovery_reader. The constructors checks for the existence ofCSVfiles containing the user data in hard-coded locations.When user StreamReaders obtain an end-of-file token, they call
FileInputDiscoveryStreamReader::dispose, which will generate aStreamInfoobject marked as disposed for each finished file.
The file adapter has basic code to illustrate how to implement the discovery functionality. More useful behavior could include providing continuous notifications about new files (hence new streams) to be read. It could also implement the output Discovery StreamReader by also detecting when a file is placed in a directory as a signal to write data obtained from a peer input stream.
4.4. Key Terms¶
- Data Integration
The process of combining data from multiple and different sources for analysis, processing, or system integration purposes.
- Adapter
Pluggable component that allows access to a custom data domain.
- Info Object
A structure that contains metadata associated with the user-data object. In DDS, this is defined as
SampleInfo.- Sample
A structure composed of a data object and its associated info object.
- Loaned samples
A list of samples returned by a StreamReader for which a return loan operation is perform.
- Stream Discovery
A mechanism through which Routing Service detects the presence of user-data streams.
- StreamInfo
A common data structure to represent discovery information across all data domains.