7.3. Metrics
This section details the metrics you can collect from Connext observable
resources. Each metric has a unique name and specifies a general feature of a
Connext observable resource. For example, a DataWriter is an observable resource; the
metric dds_data_writer_protocol_sent_heartbeats_total specifies the total
number of heartbeats sent by a DataWriter. There are two metric types:
Counters. A counter is a cumulative metric that represents a single monotonically increasing counter whose value can only increase or be reset to zero on restart.
Gauges. A gauge is a metric that represents a single numerical value that can arbitrarily go up and down.
Observability Framework uses a Prometheus time-series database to store
collected metrics. A time series is an instantiation of a metric and
represents a stream of timestamped values (measurements) belonging to the
same resource as the metric. For example, we could have a time series for
the metric dds_data_writer_protocol_sent_heartbeats_total corresponding to a
DataWriter DW1 identified by a resource GUID GUID1.
Labels (in Prometheus) or attributes (in Open Telemetry) identify each metric
instantiation or time series. A label is a key/value pair that is associated
with a metric. Any given combination of labels for the same metric name
identifies a specific instantiation of that metric. For example, the metric
dds_data_writer_protocol_sent_heartbeats_total for the DataWriter
DW1 will have the label {guid= GUID1}. All metrics have at least one
label called guid that uniquely identifies a resource in a Connext system.
In Observability Framework there is a special kind of metric called a
presence metric. Presence metrics are used to indicate the existence of
a resource in a Connext system. For example, the
dds_domain_participant_presence indicates the presence of a
DomainParticipant in a Connext system. There will be a time series for each
DomainParticipant ever created in the system. The labels associated
with a presence metric describe the resource, and they are dependent
on the type of resource. For example, a DomainParticipant resource has labels
such as `domain_id` and `name`.
For metrics that are not presence metrics, the only label is the guid
label identifying the resource to which the metrics apply. You can use
the guid label to query the description labels of a resource by
looking at the presence metric for the resource class.
Observability Framework provides the ability to create an initial configuration for the collection and forwarding of metrics on each observable resource, as well as the ability to dynamically change this configuration at run time. The initial configuration for the collection of metrics is set in the Monitoring Library 2.0, as explained in Monitoring Library 2.0. Dynamic metric collection configuration changes are done using the REST API as detailed in Collector Service REST API Reference. For an example of how to dynamically change the metric collection configuration using the Observability Dashboards see Change the Metric Configuration.
7.3.1. Metric Pattern Definitions
Observability Framework enables you to select the set of metrics collected and forwarded for a resource both before and during run time. To select metrics, you use metric selector strings. When specifying metric selector strings, POSIX® fnmatch pattern matching should be used as described in Table 7.2. The most common use case is an asterisk (*) to match 0 or more non-special characters. Some example metric selectors using POSIX® fnmatch are shown below.
Metric Selector |
Description |
|---|---|
dds_application_process_memory_usage_resident_memory_bytes |
refers to the metric “dds_application_process_memory_usage_resident_memory_bytes” |
dds_application_process_* |
refers to all metrics that begin with “dds_application_process_” |
dds_*_bytes |
refers to metrics that start with “dds_” and end with “_bytes” |
7.3.2. Application Metrics
The following tables describe the metrics and labels generated for Connext
applications. Only the dds_application_presence metric has all of the application labels
listed in the table below. All other application metrics have the guid label
only.
Label or Attribute Name |
Description |
|---|---|
|
The URL and port for the control server on the Collector Service that forwards data for the application. This URL is used when sending remote commands to the Collector Service to configure the telemetry data for the application. The remote commands use the Collector Service REST API. See Collector Service REST API Reference for details on the Collector Service REST API. |
|
Application resource GUID |
|
Name of the host computer for the application |
|
Process ID for the application |
|
Fully qualified resource name (/applications/<AppName>) |
Metric Name |
Description |
Type |
|---|---|---|
|
Indicates the presence of the application and provides all label values for an application instance |
Gauge |
|
The application resident memory utilization |
Gauge |
|
The application virtual memory utilization |
Gauge |
|
The middleware collection syslog logging level. See Logs for valid values. |
Gauge |
|
The middleware forwarding syslog logging level. See Logs for valid values. |
Gauge |
7.3.3. Participant Metrics
The following tables describe the metrics and labels generated for Connext
DomainParticipants. Only the dds_domain_participant_presence metric has all of the
DomainParticipant labels listed in the table below. All other DomainParticipant metrics
have the guid label only.
The DomainParticipant resource contains statistic variable metrics such as
dds_domain_participant_udpv4_usage_in_net_pkts_count,
dds_domain_participant_udpv4_usage_in_net_pkts_mean,
dds_domain_participant_udpv4_usage_in_net_pkts_min, and
dds_domain_participant_udpv4_usage_in_net_pkts_max.
These variables are interpreted as follows:
The metrics with suffix
_countrepresent the total number of packets or bytes over the last Prometheus scraping period.The metrics with suffix _min represent the minimum mean over the last Prometheus scraping period. For example,
dds_domain_participant_udpv4_usage_in_net_pkts_mincontains the minimum packets/sec over the last scraping period. The min mean is calculated by choosing the minimum of individual mean values reported by Monitoring Library 2.0 everyparticipant_factory_qos.monitoring.distribution_settings.periodic_settings.polling_period.The metrics with suffix
_maxrepresent the maximum mean over the last Prometheus scraping period. For example,dds_domain_participant_udpv4_usage_in_net_pkts_maxcontains the maximum packets/sec over the last scraping period. The max mean is calculated by choosing the maximum of individual mean values reported by Monitoring Library 2.0 everyparticipant_factory_qos.monitoring.distribution_settings.periodic_settings.polling_period.The metrics with suffix
_meanrepresent the mean over the last Prometheus scraping period. For example,dds_domain_participant_udpv4_usage_in_net_pkts_meancontains the packets/sec over the last scraping period. If the scraping period is 30 seconds, the metric contains the packets/sec generated within the last 30 seconds. Thedds_domain_participant_udpv4_usage_in_net_pkts_meanis calculated by averaging all individual mean metrics sent by Monitoring Library 2.0 to Observability Collector Service over the last scraping period.
Label or Attribute Name |
Description |
|---|---|
|
DomainParticipant resource GUID |
|
Resource GUID of the owner entity (application) |
|
DomainParticipant DDS GUID |
|
Name of the host computer for the DomainParticipant |
|
Process ID for the DomainParticipant |
|
DDS domain ID for the DomainParticipant |
|
Connext architecture as described in the RTI Architecture Abbreviation column in the Platform Notes. |
|
Connext product version |
|
Fully qualified resource name (/applications/<AppName> /domain_participants/<ParticipantName>) |
Metric Name |
Description |
Type |
|---|---|---|
|
Indicates the presence of the DomainParticipant and provides all label values for a DomainParticipant instance |
Gauge |
|
The UDPv4 transport in packets count over the last scraping period |
Gauge |
|
The UDPv4 transport in packets mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport in packets min mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport in packets max mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport in bytes count over the last scraping period |
Gauge |
|
The UDPv4 transport in bytes mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport in bytes min mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport in bytes max mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out packets count over the last scraping period |
Gauge |
|
The UDPv4 transport out packets mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out packets min mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out packets max mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out bytes count over the last scraping period |
Gauge |
|
The UDPv4 transport out bytes mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out bytes min mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv4 transport out bytes max mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in packets count over the last scraping period |
Gauge |
|
The UDPv6 transport in packets mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in packets min mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in packets max mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in bytes count over the last scraping period |
Gauge |
|
The UDPv6 transport in bytes mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in bytes min mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport in bytes max mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out packets count over the last scraping period |
Gauge |
|
The UDPv6 transport out packets mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out packets min mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out packets max mean (packets/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out bytes count over the last scraping period |
Gauge |
|
The UDPv6 transport out bytes mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out bytes min mean (bytes/sec) over the last scraping period |
Gauge |
|
The UDPv6 transport out bytes max mean (bytes/sec) over the last scraping period |
Gauge |
7.3.4. Topic Metrics
The following tables describe the metrics and labels generated for Connext
Topics. Only the dds_topic_presence metric has all of the Topic labels listed
in the table below. All other Topic metrics have the guid label only.
Label or Attribute Name |
Description |
|---|---|
|
Topic resource GUID |
|
Resource GUID of the owner entity (DomainParticipant) |
|
Topic DDS GUID |
|
Name of the host computer for the DomainParticipant this Topic is registered with |
|
DDS domain ID for the DomainParticipant this Topic is registered with |
|
The Topic name |
|
The registered type name for this Topic |
|
Fully qualified resource name (/applications/<AppName>/domain_participants /<ParticipantName>/topics/<TopicName>) |
Metric Name |
Description |
Type |
|---|---|---|
|
Indicates the presence of the Topic and provides all label values for a Topic instance |
Gauge |
|
See total_count field in the INCONSISTENT_TOPIC Status |
Counter |
7.3.5. DataWriter Metrics
The following tables describe the metrics and labels generated for Connext
DataWriters. Only the dds_data_writer_presence metric has all of the
DataWriter labels listed in the table below. All other DataWriter metrics
have the guid label only.
Label or Attribute Name |
Description |
|---|---|
|
DataWriter resource GUID |
|
Resource GUID of the owner entity (publisher) |
|
DataWriter DDS GUID |
|
Name of the host computer for the DomainParticipant this DataWriter is registered with |
|
DDS domain ID for the DomainParticipant this DataWriter is registered with |
|
The Topic name for this DataWriter |
|
The registered type name for this DataWriter |
|
Fully qualified resource name (/applications/<AppName>/domain_participants /<ParticipantName>/publishers/<PublisherName>/data_writers/<DataWriterName>) |
|
Resource GUID of the DomainParticipant this DataWriter is registered with |
Metric Name |
Description |
Type |
|---|---|---|
|
Indicates the presence of the DataWriter and provides all label values for a DataWriter instance |
Gauge |
|
See total_count field in the LIVELINESS_LOST Status |
Counter |
|
See total_count field in the OFFERED_DEADLINE_MISSED Status |
Counter |
|
See total_count field in the OFFERED_INCOMPATIBLE_QOS Status |
Counter |
|
See full_reliable_writer_cache field in the RELIABLE_WRITER_CACHE_CHANGED Status |
Counter |
|
See high_watermark_reliable_writer_cache field in the RELIABLE_WRITER_CACHE_CHANGED Status |
Counter |
|
See unacknowledged_sample_count field in the RELIABLE_WRITER_CACHE_CHANGED Status |
Gauge |
|
See unacknowledged_sample_count_peak field in the RELIABLE_WRITER_CACHE_CHANGED Status |
Gauge |
|
See replaced_unacknowledged_sample_count field in the RELIABLE_WRITER_CACHE_CHANGED Status |
Counter |
|
See inactive_count field in the RELIABLE_READER_ACTIVITY_CHANGED Status |
Gauge |
|
See sample_count_peak field in the DATA_WRITER_CACHE_STATUS |
Gauge |
|
See sample_count field in the DATA_WRITER_CACHE_STATUS |
Gauge |
|
See alive_instance_count field in the DATA_WRITER_CACHE_STATUS |
Gauge |
|
See alive_instance_count_peak field in the DATA_WRITER_CACHE_STATUS |
Gauge |
|
See pushed_sample_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pushed_sample_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See sent_heartbeat_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pulled_sample_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pulled_sample_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See received_nack_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See received_nack_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See send_window_size field in the DATA_WRITER_PROTOCOL_STATUS |
Gauge |
|
See pushed_fragment_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pushed_fragment_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pulled_fragment_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See pulled_fragment_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See received_nack_fragment_count field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
|
See received_nack_fragment_bytes field in the DATA_WRITER_PROTOCOL_STATUS |
Counter |
7.3.6. DataReader Metrics
The following tables describe the metrics and labels generated for Connext
DataReaders. Only the ddsd_datareader_presence metric has all of the
DataReader labels listed in the table below. All other DataReader metrics
have the guid label only.
Label or Attribute Name |
Description |
|---|---|
|
DataReader resource GUID |
|
Resource GUID of the owner entity (subscriber) |
|
DataReader DDS GUID |
|
Name of the host computer for the DomainParticipant this DataReader is registered with |
|
DDS domain ID for the DomainParticipant this DataReader is registered with |
|
The Topic name for this DataReader |
|
The registered type name for this DataReader |
|
Fully qualified resource name (/applications/<AppName>/domain_participants/<ParticipantName> /subscribers/<SubscriberName>/data_readers/<DataReaderName>) |
|
Resource GUID of the DomainParticipant this DataReader is registered with |
Metric Name |
Description |
Type |
|---|---|---|
|
Indicates the presence of the DataReader and provides all label values for a DataReader instance |
Gauge |
|
See total_count field in the SAMPLE_REJECTED Status |
Counter |
|
See not_alive_count field in the LIVELINESS_CHANGED Status |
Gauge |
|
See total_count field in the REQUESTED_DEADLINE_MISSED Status |
Counter |
|
See total_count field in the REQUESTED_INCOMPATIBLE_QOS Status |
Counter |
|
See total_count field in the SAMPLE_LOST Status |
Counter |
|
See sample_count_peak field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See sample_count field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See old_source_timestamp_dropped_sample_count field in the DATA_READER_CACHE_STATUS |
Counter |
|
See tolerance_source_timestamp_dropped_sample_count field in the DATA_READER_CACHE_STATUS |
Counter |
|
See content_filter_dropped_sample_count field in the DATA_READER_CACHE_STATUS |
Counter |
|
See replaced_dropped_sample_count field in the DATA_READER_CACHE_STATUS |
Counter |
|
See total_samples_dropped_by_instance_replacement field in the DATA_READER_CACHE_STATUS |
Counter |
|
See alive_instance_count field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See alive_instance_count_peak field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See no_writers_instance_count field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See no_writers_instance_count_peak field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See disposed_instance_count field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See disposed_instance_count_peak field in the DATA_READER_CACHE_STATUS |
Gauge |
|
See compressed_sample_count field in the DATA_READER_CACHE_STATUS |
Counter |
|
See received_sample_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See received_sample_bytes field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See duplicate_sample_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See duplicate_sample_bytes field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See received_heartbeat_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See sent_nack_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See sent_nack_bytes field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See rejected_sample_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See out_of_range_rejected_sample_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See received_fragment_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See dropped_fragment_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See reassembled_sample_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See sent_nack_fragment_count field in the DATA_READER_PROTOCOL_STATUS |
Counter |
|
See sent_nack_fragment_bytes field in the DATA_READER_PROTOCOL_STATUS |
Counter |
7.3.7. Derived Metrics Generated by Prometheus Recording Rules
Prometheus provides a capability called Recording Rules. The following text is an excerpt from the Prometheus documentation.
Recording rules allow you to precompute frequently needed or computationally
expensive expressions and save their result as a new set of time series.
Querying the precomputed result will then often be much faster than executing
the original expression every time it is needed. This is especially useful for
dashboards, which need to query the same expression repeatedly every time they
refresh.
A Prometheus recording rule generates a new metric time series with new values calculated at the frequency at which the rule is run. The recording rules in Observability Framework are run every 10 seconds, meaning there is an evaluation and update to the associated derived metric every 10 seconds. Observability Framework uses Prometheus recording rules to generate three types of derived metrics.
DDS entity proxy metrics
raw
errormetricsaggregated
errormetrics.
Each of these derived metric types is discussed in detail below.
The Grafana dashboards provided with Observability Framework make use of
the error metrics generated by Prometheus recording rules. The aggregated
error metrics are used on the Alert Home dashboard, while the raw error
metrics are used on other dashboards.
7.3.7.1. DDS Entity Proxy Metrics
The DDS entity proxy metrics are used in the recording rules for the raw error
metrics and are always 0. The proxy metrics are used to make sure the rules
evaluate to known good values in cases where the underlying metrics are not
available.
Metric Name |
Description |
|---|---|
|
A proxy for applications metrics that always provides a value of zero. |
|
A proxy for applications metrics that always provides a value of zero. |
|
A proxy for applications metrics that always provides a value of zero. |
|
A proxy for applications metrics that always provides a value of zero. |
|
A proxy for applications metrics that always provides a value of zero. |
7.3.7.2. Raw Error Metrics
Raw error metrics are derived for select metrics by doing a boolean
comparison to a predefined limit. The raw error metrics are created by
converting the monotonically increasing value of a counter metric into a
rate, comparing that rate to a limit, and returning a boolean value. The
returned boolean value is 1 if the limit is exceeded, otherwise
0. In the Grafana dashboards, a value of 0 indicates a healthy
condition for the error metric, while a value of 1 indicates a
fail condition.
Recording rules have been created to generate a derived raw error metric for
all of the metrics listed in Table 7.18 and
Table 7.19.
7.3.7.2.1. Enabled Raw Error Metrics
A set of recording rules have been created that are useful for detecting failures
in all systems. These rules detect conditions that are not expected to occur in
a system that is operating correctly. The rules for these “enabled” metrics test
if the underlying metric has exceeded a limit of 0. Note the >bool 0 comparison
operator in each of the recording rules. A value greater than 0 in any of these
metrics will result in an alert indication in the dashboards. This set of metrics
is “enabled” because any increase in the underlying metric indicates an unexpected
condition in DDS. Table 7.18 lists derived Raw error
metrics that are “enabled”.
Metric Name |
Recording Rule |
|---|---|
|
rate(dds_data_reader_cache_content_filter_dropped_samples_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_replaced_dropped_samples_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_samples_dropped_by_instance_replaced_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_rejected_samples_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_out_of_range_rejected_samples_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_dropped_fragments_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_topic_inconsistent_total[1m]) >bool 0 or dds_topic_empty_metric |
|
rate(dds_data_writer_incompatible_qos_total[1m]) >bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_incompatible_qos_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_writer_liveliness_lost_total[1m]) >bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_reliable_reader_activity_inactive_count[1m]) >bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_liveliness_not_alive_count[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_tolerance_source_ts_dropped_samples_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_writer_deadline_missed_total[1m]) >bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_deadline_missed_total[1m]) >bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_writer_reliable_cache_replaced_unack_samples_total[1m]) >bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_sample_lost_total[1m]) >bool 0 or dds_data_reader_empty_metric |
7.3.7.2.2. Disabled Raw Error Metrics
Additional recording rules have been created that by default are not useful for
detecting failures since the meaningful rules depend on comparisons to values
that will be dependent on actual system requirements. The rules for the “disabled”
metrics test to see if the underlying metric is less than a limit of 0, ensuring
that the derived raw error metric never indicates a failure, hence disabled.
Note the <bool 0 comparison operator in each of the recording rules. This set
of metrics is “disabled” because a meaningful limit that would indicate a fail
condition cannot be determined without additional knowledge of the system.
Users may modify a “disabled” rule to compare against a value that is meaningful to their system. For example, if users want to be notified when the number of repaired samples over the last minute exceeds 10, then they would modify the rule
rate(dds_data_writer_protocol_pulled_samples_total[1m]) <bool 0 or dds_data_writer_empty_metric
To
rate(dds_data_writer_protocol_pulled_samples_total[1m]) >bool 10 or dds_data_writer_empty_metric
For complete instructions on how to enable these metrics and display them in the dashboards, see Enable a Raw Error Metric.
The “disabled” rules have been created as a convenience for the user. However,
only a few of these rules may be useful for any specific system. Table 7.19
lists derived raw error metrics that are “disabled”.
Metric Name |
Recording Rule |
|---|---|
|
rate(dds_data_writer_protocol_sent_heartbeats_total[1m] <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_received_nacks_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_received_nack_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_received_nack_fragments_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_received_nack_fragment_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_protocol_received_heartbeats_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_sent_nacks_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_sent_nack_bytes_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_sent_nack_fragments_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_sent_nack_fragment_bytes_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_writer_protocol_pulled_samples_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pulled_sample_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pulled_fragments_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pulled_fragment_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pushed_samples_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pushed_sample_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pushed_fragments_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_pushed_fragment_bytes_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_cache_compressed_samples_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_duplicate_samples_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_duplicate_sample_bytes_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_received_samples_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_received_sample_bytes_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_received_fragments_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_protocol_reassembled_samples_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_application_process_memory_usage_resident_memory_bytes[1m]) <bool 0 or dds_application_empty_metric |
|
rate(dds_application_process_memory_usage_virtual_memory_bytes[1m]) <bool 0 or dds_application_empty_metric |
|
rate(dds_domain_participant_udpv4_usage_in_net_pkts_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv4_usage_in_net_bytes_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv4_usage_out_net_pkts_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv4_usage_out_net_bytes_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv6_usage_in_net_pkts_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv6_usage_in_net_bytes_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv6_usage_out_net_pkts_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_domain_participant_udpv6_usage_out_net_bytes_mean[1m]) <bool 0 or dds_domain_participant_empty_metric |
|
rate(dds_data_writer_reliable_cache_full_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_reliable_cache_high_watermark_total[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_reliable_cache_unack_samples[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_reliable_cache_unack_samples_peak[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_protocol_send_window_size[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_cache_samples[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_cache_samples_peak[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_cache_alive_instances[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_writer_cache_alive_instances_peak[1m]) <bool 0 or dds_data_writer_empty_metric |
|
rate(dds_data_reader_sample_rejected_total[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_samples[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_samples_peak[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_alive_instances[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_alive_instances_peak[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_no_writers_instances[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_no_writers_instances_peak[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_disposed_instances[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_disposed_instances_peak[1m]) <bool 0 or dds_data_reader_empty_metric |
|
rate(dds_data_reader_cache_old_source_ts_dropped_samples_total[1m]) <bool 0 or dds_data_reader_empty_metric |
7.3.7.3. Aggregated Error Metrics
The aggregated error metrics create a status roll-up for a group of metrics
in a particular category. These aggregated error metrics are used in the
Alert Home dashboard to provide a high-level view of alerts grouped by category.
The categories are Bandwidth, Saturation, Data Loss, System Errors,
and Delays. The aggregated error metrics are created by adding together
all of the raw error metrics assigned to a category and clamping the values
at 1, the value that indicates a failed condition.
Table 7.20 shows all of the aggregated error
metrics and the rule used to generate them. Note the use of the raw
error metrics in the rules.
Metric Name |
Recording Rule |
|---|---|
|
clamp_max ((sum (dds_custom_excessive_bandwidth_errors) + sum (dds_data_writer_protocol_sent_heartbeats_errors) + sum (dds_data_writer_protocol_received_nacks_errors) + sum (dds_data_writer_protocol_received_nack_bytes_errors) + sum (dds_data_writer_protocol_received_nack_fragments_errors) + sum (dds_data_writer_protocol_received_nack_fragment_bytes_errors) + sum (dds_data_reader_protocol_received_heartbeats_errors) + sum (dds_data_reader_protocol_sent_nacks_errors) + sum (dds_data_reader_protocol_sent_nack_bytes_errors) + sum (dds_data_reader_protocol_sent_nack_fragments_errors) + sum (dds_data_reader_protocol_sent_nack_fragment_bytes_errors) + sum (dds_data_writer_protocol_pulled_samples_errors) + sum (dds_data_writer_protocol_pulled_sample_bytes_errors) + sum (dds_data_writer_protocol_pulled_fragments_errors) + sum (dds_data_writer_protocol_pulled_fragment_bytes_errors) + sum (dds_data_writer_protocol_pushed_samples_errors) + sum (dds_data_writer_protocol_pushed_sample_bytes_errors) + sum (dds_data_writer_protocol_pushed_fragments_errors) + sum (dds_data_writer_protocol_pushed_fragment_bytes_errors) + sum (dds_data_reader_cache_content_filter_dropped_samples_errors) + sum (dds_data_reader_cache_compressed_samples_errors) + sum (dds_data_reader_protocol_duplicate_samples_errors) + sum (dds_data_reader_protocol_duplicate_sample_bytes_errors) + sum (dds_data_reader_protocol_received_samples_errors) + sum (dds_data_reader_protocol_received_sample_bytes_errors) + sum (dds_data_reader_protocol_received_fragments_errors) + sum (dds_data_reader_protocol_reassembled_samples_errors)), 1) |
|
clamp_max ((sum (dds_custom_saturation_errors) + sum (dds_application_process_memory_usage_resident_memory_bytes_errors) + sum (dds_application_process_memory_usage_virtual_memory_bytes_errors) + sum (dds_domain_participant_udpv4_usage_in_net_pkts_errors) + sum (dds_domain_participant_udpv4_usage_in_net_bytes_errors) + sum (dds_domain_participant_udpv4_usage_out_net_pkts_errors) + sum (dds_domain_participant_udpv4_usage_out_net_bytes_errors) + sum (dds_domain_participant_udpv6_usage_in_net_pkts_errors) + sum (dds_domain_participant_udpv6_usage_in_net_bytes_errors) + sum (dds_domain_participant_udpv6_usage_out_net_pkts_errors) + sum (dds_domain_participant_udpv6_usage_out_net_bytes_errors) + sum (dds_data_writer_reliable_cache_full_errors) + sum (dds_data_writer_reliable_cache_high_watermark_errors) + sum (dds_data_writer_reliable_cache_unack_samples_errors) + sum (dds_data_writer_reliable_cache_unack_samples_peak_errors) + sum (dds_data_writer_protocol_send_window_size_errors) + sum (dds_data_writer_cache_samples_errors) + sum (dds_data_writer_cache_samples_peak_errors) + sum (dds_data_writer_cache_alive_instances_errors) + sum (dds_data_writer_cache_alive_instances_peak_errors) + sum (dds_data_reader_sample_rejected_errors) + sum (dds_data_reader_cache_samples_errors) + sum (dds_data_reader_cache_samples_peak_errors) + sum (dds_data_reader_cache_replaced_dropped_samples_errors) + sum (dds_data_reader_cache_samples_dropped_by_instance_replaced_errors) + sum (dds_data_reader_cache_alive_instances_errors) + sum (dds_data_reader_cache_alive_instances_peak_errors) + sum (dds_data_reader_cache_no_writers_instances_errors) + sum (dds_data_reader_cache_no_writers_instances_peak_errors) + sum (dds_data_reader_cache_disposed_instances_errors) + sum (dds_data_reader_cache_disposed_instances_peak_errors) + sum (dds_data_reader_protocol_rejected_samples_errors) + sum (dds_data_reader_protocol_out_of_range_rejected_samples_errors) + sum (dds_data_reader_protocol_dropped_fragments_errors)), 1) |
|
clamp_max ((sum (dds_custom_errors) + sum (dds_topic_inconsistent_errors) + sum (dds_data_writer_incompatible_qos_errors) + sum (dds_data_reader_incompatible_qos_errors) + sum (dds_data_writer_liveliness_lost_errors) + sum (dds_data_writer_reliable_reader_activity_inactive_count_errors) + sum (dds_data_reader_liveliness_not_alive_count_errors) + sum (dds_data_reader_cache_old_source_ts_dropped_samples_errors) + sum (dds_data_reader_cache_tolerance_source_ts_dropped_samples_errors)), 1) |
|
clamp_max ((sum (dds_custom_delays_errors) + sum (dds_data_writer_deadline_missed_errors) + sum (dds_data_reader_deadline_missed_errors)), 1) |
|
clamp_max ((sum (dds_custom_data_loss_errors) + sum (dds_data_writer_reliable_cache_replaced_unack_samples_errors) + sum (dds_data_reader_sample_lost_errors) + sum (dds_data_reader_cache_replaced_dropped_samples_errors) + sum (dds_data_reader_cache_samples_dropped_by_instance_replaced_errors) + sum (dds_data_reader_cache_tolerance_source_ts_dropped_samples_errors)), 1) |
7.3.7.4. Enable a Raw Error Metric
Note
The Grafana user must have Admin privileges to make any changes to the Grafana dashboards.
Use the following steps to enable any of the “disabled” metrics in your system:
Update the raw
errorrule to enable the calculation and provide a limit. See Update the Recording Rule for the Derived Metric below.Update the Alert “Category” dashboard to update the background color of the OK/ERROR and State panels for the enabled metric. See Update the Alert “Category” Dashboard below.
Update the “Entity” status dashboard to update the query and background color in the State panel. See Update the “Entity” Status Dashboard below.
The example that follows uses the dds_data_reader_cache_alive_instances_errors
metric to update/enable a rule to detect any DataReader that has more
than 3 ALIVE instances in its cache.
7.3.7.4.1. Update the Recording Rule for the Derived Metric
Locate the recording rule for the dds_data_reader_cache_alive_instances_errors
metric in the monitoring_recording_rules.yml file located in the
rti_workspace/<version>/observability/prometheus directory.
# User Config Required
- record: dds_data_reader_cache_alive_instances_errors
expr: >
rate(dds_data_reader_cache_alive_instances[1m]) <bool 0 or dds_data_reader_empty_metric
The dds_data_reader_cache_alive_instances metric is a gauge metric, meaning we
want to use the absolute value for our limit check rather than the rate. In the
following example recording rule, we want to update the limit test so that the error
will be active whenever the value is greater than 3.
# User Config Required
- record: dds_data_reader_cache_alive_instances_errors
expr: >
dds_data_reader_cache_alive_instances >bool 3 or dds_data_reader_empty_metric
Important
After updating the monitoring_recording_rules.yml file, you must restart
all Docker containers for Observability Framework by running rtiobservability -t
followed by rtiobservability -s. The Prometheus server will read the updated
file after restarting the containers.
7.3.7.4.2. Update the Alert “Category” Dashboard
Note
The Grafana images in this section were generated with Grafana version 9.2.1. If you are using a different version of Grafana, the interface may be slightly different.
Locate the Alert “Category” dashboard for the metric rule you are enabling.
The metric in our example, dds_data_reader_cache_alive_instances_errors,
is in the Saturation group (see Table 7.20),
so the Alert Saturation dashboard is used in the following steps.
Go to Dashboards > Browse to open the list of dashboards.
Select the Alert Saturation dashboard from the list.
Once on the Alert Saturation dashboard, scroll down to the Alive Instances row under the Reader Cache section.

Select Alive Instances > Edit from the status indicator panel menu.
In the right panel, scroll down until you find the Value mappings section.
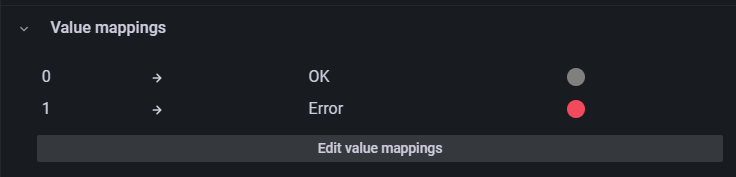
Click the gray color circle next to the OK mapping to select a new color for the panel “OK” indication.
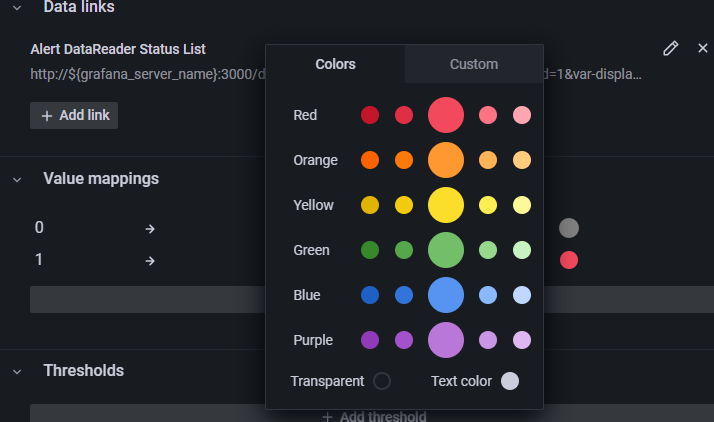
Select the large green circle in the panel. The updated OK value should change from gray to green.
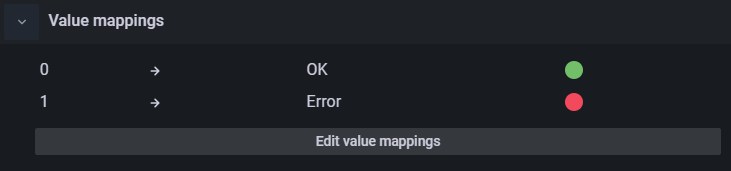
Select Apply at the top right to apply the change and return to the Alert Saturation dashboard.

Select Alive Instances > Edit from the status indicator panel menu.
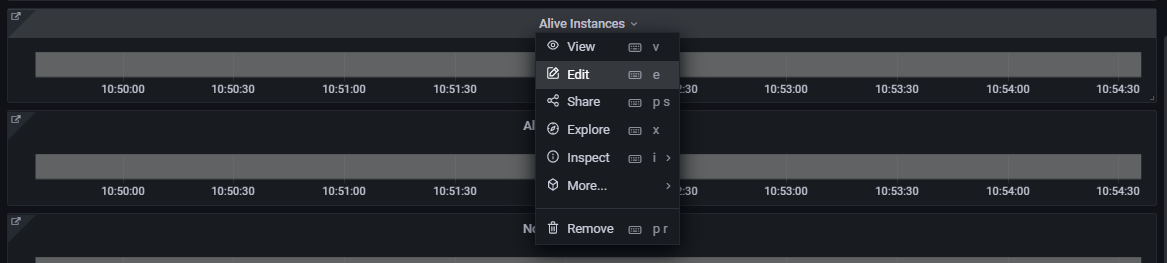
In the right panel, scroll down to the Thresholds section.
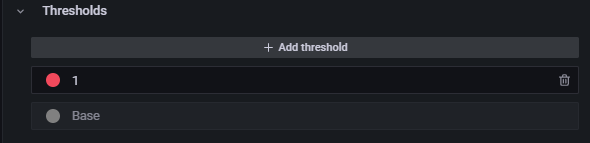
Click the gray circle next to Base to select a new base color for the Thresholds panel.
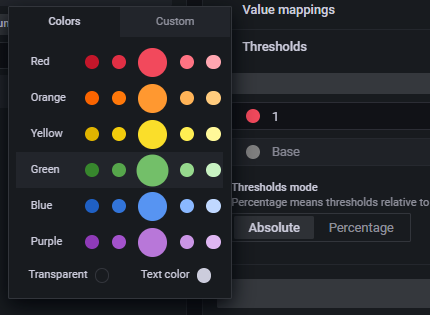
Select the large green circle in the panel. The updated Threshold base value should change to green.
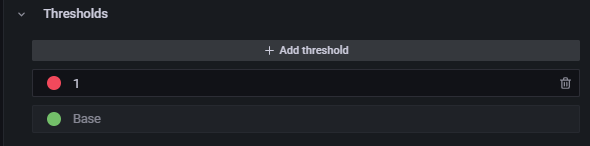
Select Apply at the top right to apply the changes and return to the Alert Saturation dashboard.
Select the Save Dashboard icon at the top right.
When prompted to confirm, select Save.
The Alive Instances row under the Reader Cache section should now be green, indicating it is enabled.

7.3.7.4.3. Update the “Entity” Status Dashboard
Locate the “Entity” status dashboard for the metric rule you are enabling. For
the metric in our example, dds_data_reader_cache_alive_instances_errors,
we need to update the Alert DataReader Status dashboard.
Go to Dashboards > Browse to open the list of dashboards.
Select the Alert DataReader Status dashboard from the list.
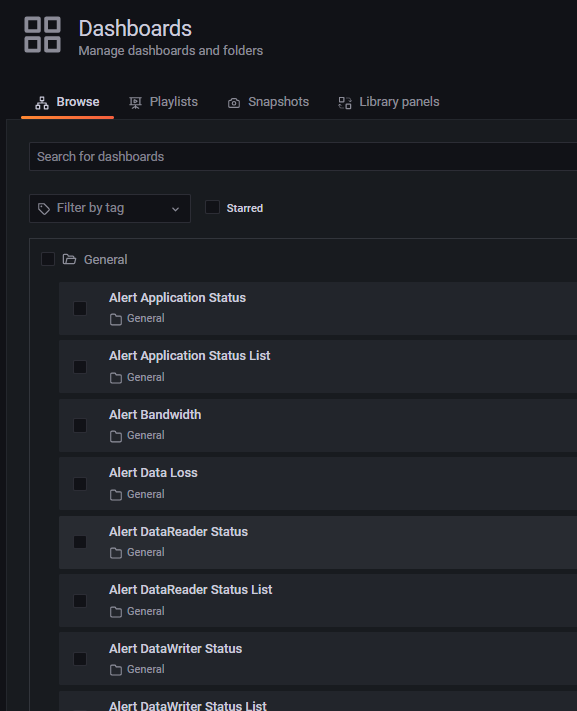
Once on the Alert DataReader Status dashboard, scroll down to the Alive Instances row under the Saturation/Reader Cache section.

Select Alive Instances > Edit from the status indicator panel menu.
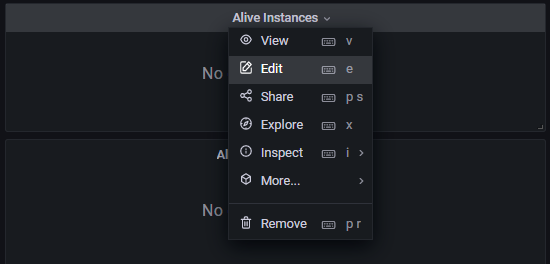
The query for the panel is shown below.
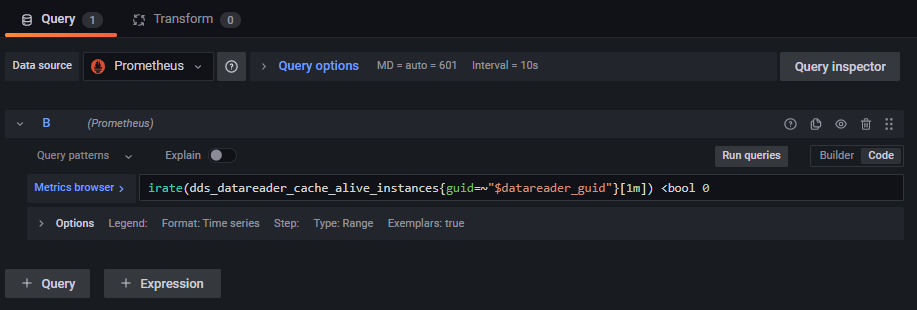
Edit the query to match the rule that was created for the
dds_data_reader_cache_alive_instances_errorsmetric. In the Metrics browser field, remove the irate calculation and set the limit check to>bool 3, as shown below.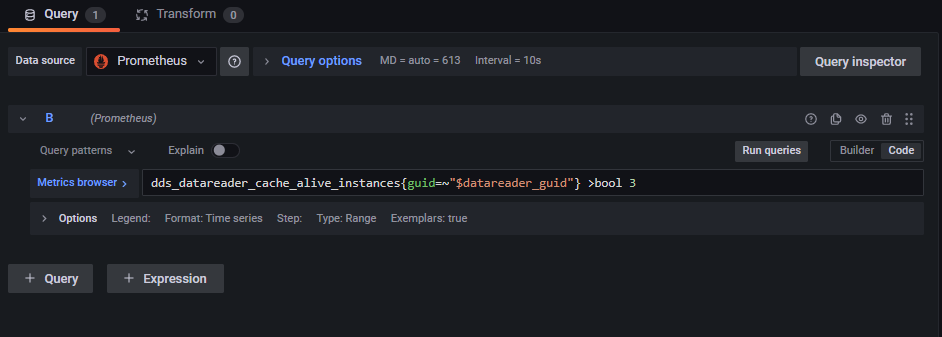
In the right panel, scroll down to the Thresholds section.
Click the gray circle next to Base to select a new base color for the Thresholds panel.
Select the large green circle in the panel. The updated Threshold base value should change from gray to green.
Select Apply at the top right to apply the change and return to the Alert DataReader Status dashboard.
Select the Save Dashboard icon at the top right.
When prompted to confirm, select Save.
You have now enabled a rule for dds_data_reader_cache_alive_instances that
detects any DataReader that has more than 3 sample instances in its queue with
an instance state of ALIVE. The indication of this condition will display on
all relevant dashboards.
You can test this rule by running the applications as
described in section Start the Applications. Start any
combination of publishing applications with the -s, --sensor-count
command-line arguments totaling more than 3. Anytime this condition occurs,
you will see this error indicated.
7.3.7.5. Custom Error Metrics
Table 7.21 shows metrics that are not fully implemented.
Metric Name |
Description |
|---|---|
|
Not fully implemented. Not to be modified or used. |
|
Not fully implemented. Not to be modified or used. |
|
Not fully implemented. Not to be modified or used. |
|
Not fully implemented. Not to be modified or used. |
|
Not fully implemented. Not to be modified or used. |