HOWTO Create a Routing Service Adapter
1 Introduction
RTI Routing Service is the RTI application that allows you to route your data from one domain to another. It doesn't have to be necessarily a DDS Domain, it could be a socket, a JMS provider, or whatever you want.
This document comes along with a simple example that doesn't use DDS at all. It reads from and writes to a file system. To do that, you need to have an adapter to Routing Service that will match the representation of the destination or source domain to a representation that Routing Service can understand and forward. The adapter is the point of contact between Routing Service and each domain. With Routing Service, you actually have an adapter on each side (one for every domain) of the service. For further information, see the Routing Service User's Manual, here for the current release or here for release 5.1.0.
By default, Routing Service has its own built-in adapter for basic requirements. If you want something more specific, you need to build your own adapter. If you want to use the built-in adapter, just use an XML configuration file and don't specify your own adapter.
This guide is more oriented towards how to write an adapter in C language. If you are using a different language, you can refer to the User's Manual to see the small differences in the approach, but the sequence of operations and the functionality of the API are quite similar. This example is developed for a Linux environment; there are just a few things you need to change if you want to make it run in a Windows environment.
Note: The source code of this HOWTO is available in the examples section.
2 XML File Configuration
First, let's step into the XML configuration file. If you decide to build your own adapter instead of using the built-in one, you should declare it in the XML configuration file. So first thing you have to do, inside the <dds> section/tag, is say where the adapter library is located.
<dds>
....
<adapter_library name="adapters">
<adapter_plugin name="file">
<dll>fileadapters</dll>
<create_function>RoutingServiceFileAdapterPlugin_create</create_function>
</adapter_plugin>
</adapter_library>
....
</dds>In the <adapter_library> tag, you will assign a name to the adapter library (in this case, adapters) and the plugin (in this case, file). This is where you name your component for future use inside the XML configuration file.
The <dll> tag indicates the path of the generated library you created. In this case, the path is not indicated because we put it in the bin directory of the RTI_Routing_Service directory installation. If you want to install the library somewhere else, you should specify the path. For example:
<dll>/home/username/projects/adapter_project/lib/libsimplefileadapter.so</dll> <!-- (referring to a Linux environment) -->
Or specify the desired path in the environment variable, LD_LIBRARY_PATH.
There is also a <create_function> tag, where you should specify your own function that will create the plugin. It is the actual name of the function written in your adapter's C file; this function is Routing Service's access point to the plugin.
Inside this function, you will allocate memory for the data structure that will contain the pointer to all the functions that will be called by Routing Service according to the situation and its state.
The type of the mentioned data structure that will be returned by the create_function is struct RTI_RoutingServiceAdapterPlugin.
Its fields are pointers to functions that you will define. These functions must have specific signatures with predetermined parameters. Make sure you respect these signatures when writing the functions. Otherwise when Routing Service wants to call the function, it won't match.
An example of a function is:
adapter->adapter_plugin_create_connection =
RTI_RoutingServiceFileAdapterPlugin_create_connection;This is the function that creates one connection between the domain and the adapter (we will explain it in more detail later) where you have already defined the function:
RTI_RoutingServiceConnection RTI_RoutingServiceFileAdapterPlugin_create_connection(
struct RTI_RoutingServiceAdapterPlugin * adapter,
const char * routing_service_name,
const char * routing_service_group_name,
const struct RTI_RoutingServiceStreamReaderListener * input_disc_listener,
const struct RTI_RoutingServiceStreamReaderListener * output_disc_listener,
const struct RTI_RoutingServiceTypeInfo ** registeredTypes,
int registeredTypeCount,
const struct RTI_RoutingServiceProperties * properties,
RTI_RoutingServiceEnvironment * env);
All the signatures and all the functions that are contained in the structure to build your own adapter can be found in the online documentation, but we'll also describe them in detail later in this document.
The online documentation for an adapter plugin is here for the current release or here for release 5.1.0.
Documentation for the entire API is here for the current release or here for release 5.1.0.
Now let's examine the adapter's XML configuration, its code, and relationship between them. The plugin adapter and the XML file configuration are widely correlated: for every entity created in the plugin (code) there is the corresponding part in the XML configuration file. So the entity we have to configure inside the adapter has the following:
- Routing Service
- connection
- session
- domain_route
- route
- input
- output
Inside the XML file configuration the order and hierarchy of the tags is the following:
<dds>
<adapter_library>
<!-- Here is where you put your own adapter library definition, as explained before -->
</adapter_library>
<routing_service name="RoutingService_name">
<!-- The <routing_service> tag describes the configuration for a running instance of
Routing Service. You can have define more than one <routing_service> tag, but a
running instance of Routing Service will only use one. When you start Routing
Service, you will indicate the name of one routing_service configuration, as
well as the name of the configuration file. -->
<domain_route name="domain_route_name">
<!-- The <domain_route> defines a mapping between TWO data domains. Inside here you
can actually specify the domain mapping. If you are using the built-in adapter,
use the following tags: -->
<participant_1></participant_1>
<participant_2></participant_2>
<!-- Or if you are using your own defined adapter, use these tags: -->
<connection_1 plugin_name="adapter_library::adapter_plugin"> </connection_1>
<connection_2 plugin_name="adapter_library::adapter_plugin"> </connection_2>
<!-- Notice that the connection tags require an attribute that defines the plugin
that implements the adapter. adapter_library_name and adapter_plugin_name
are the names you defined in the main part when you registered the plugin
at the beginning of the XML file (within the <dds> tag before
defining the instance of Routing Service).
Important: You can combine participant and connection as you prefer, you can
use one participant and one connection, both participants or both connections
Next, define the session. Defining the <session> tag is mandatory to reflect
the concept of session, which is a single-threaded context for data routing.
The related function when you are writing the adapter is optional.-->
<session name="session_name">
<!-- Inside the session, you can specify routes. The data inside the session
are routed according to the route specification. There are different ways
to define a route; the most common and general are route and autoroute,
defined by the tags seen below. Inside the route, you can eventually define
the actual route: the input and the output. The differences between route
and auto_route are mainly that with route you can just specify the specific
route from input to output; with an auto_route, you can create rules in a
way that, for instance, Routing Service could accept more topics, and create
a new stream for every single topic or type that matches the pattern specified
inside the topic. The way to specify input and output inside the tag for a
<route> is also valid for an <auto_route>. -->
<route name="route_name">
<!-- Inside the <route>, specify the input and the output domain. In the tag
<input>, define which participant/connection is the input; by elimination
the other participant is the output (hence you don't have to specify anything
in the <output> tag). So in the <input> tag, you add an attribute "participant"
that can have the value 1 or 2. The number reflects the suffix that you have
written on your participant/connection declaration (participant_1,
participant_2, or connection_1, connection_2).
Before talking about input and output, let's look at another important tag:
<creation_mode> specifies when a new stream must be created. Notice that we
are talking about the stream between Routing Service and the
participant/connection.-->
<creation_mode></creation_mode>
<!-- For a complete list of possible creation mode values, see the Routing Service
User's Manual. Here are there just a few:
- IMMEDIATE: (default) The StreamWriter/Reader is created as soon as possible.
- ON_DOMAIN_MATCH: The StreamWriter/Reader is created once Routing Service
discovers new discovery information related to the connection (which means
when it finds a publisher/subscriber).
- ON_ROUTE_MATCH: the StreamWriter/Reader is created if, on the other side of
the Routing Service, its counterpart StreamReader/Writer is created.
The same rules that are applied to create the StreamWriter/Reader also apply
to their destruction. When the condition that triggered the creation of that
entity becomes false, the entity is destroyed. For instance, if a stream is
created with ON_ROUTE_MATCH, it is deleted when there is no longer match; if a
stream is created with ON_DOMAIN_MATCH, it is deleted after receiving
discovery information about the deletion of the stream. Obviously, if a
stream is created with the IMMEDIATE policy, it is never going to be destroyed
(or better, it is going to be destroyed at the end of the execution of Routing
Service).-->
<dds_input participant="1 or 2"></dds_input>
<dds_output></dds_output>
<!-- If you created the connection via your plugin adapter instead, you should
specify the input, or the output, or both in the following way: -->
<input participant="1 or 2"></input>
<output></output>
</route>
<!-- If you decided, according to your needs, to use auto_route, you would have used the
following tags. -->
<auto_route name="..."></auto_route>
<!-- After closing the route/auto_route tag, close the session and all the other tags
you have opened.-->
</session>
</domain_route>
</routing_service>
</dds> Inside every tag you can insert properties which you will retrieve from the adapter when you define it. This results in a more flexible configuration. For instance, you can set properties for the name of the file where to write results, the methodology to open the file or to write in it, etc. These properties can be inserted at any level; for instance: connection, session, route or even in the plugin definition, and they can be retrieved in the related function defined in the adapter. The prototype of the function will have a parameter called properties, where you can obtain the desired property.
The properties are defined in the following way:
<property>
<value>
<element>
<name>name_of_the_property</name>
<value>value_of_the_property</value>
</element>
<element>
...
</element>
</value>
...
</property>
Here’s an example of setting a property inside a entity, if I want to give the adapter properties, if you want to give to the plugin some connection configuration properties:
<connection_1 plugin_name="adapters::simple_file">
<property>
<value>
<element>
<name>name_of_the_property</name>
<value>value_of_the_property</value>
</element>
</value>
</property>
</connection_1>
In this way, the function you have defined here, you will retrieve it inside the create_connection function in your adapter.
Summarizing, you have the tag <dds> that includes all the configuration information. Inside <dds> you can define more configuration settings for Routing Service. Then you can start Routing Service with one of them. Inside the Routing Service, you define the domain route, which includes the definition of the two endpoints for the Routing Service. These endpoints can be a built-in adapter or your own customized adapter. Then you define the session; inside the session you define the route, which could be a route, an auto_route, topic_route, etc. Inside the route you specify the creation mode for the route, as well as the input and output participant/connection. Inside every defined entity you can define related properties, if you have some.
3 Writing your own adapter
3.1 Creation function
3.2 Creating data structures
3.3 Creation of entities
To make things easier to understand, together with this document you can find a working example of a simple adapter that you can configure and run. What this example does, is not actually working with a DDS domain, but on both sides of the Routing Service, the relative domains are connected with the file system.
In this example, the adapter scans the file system in one specific folder that you may define in the XML configuration file, the path property inside the connection tag. For every file present in that folder, it creates a stream to communicate with the output. The data that will flow in this stream are the lines inside the files. In summary, we have a stream for every file in the specified folder, and every stream transport on the other side the text lines contained inside the specific file. In the output, the adapter will take care of creating a file for every stream received. The files will be created on a specific path, which you can configure in the XML configuration file.
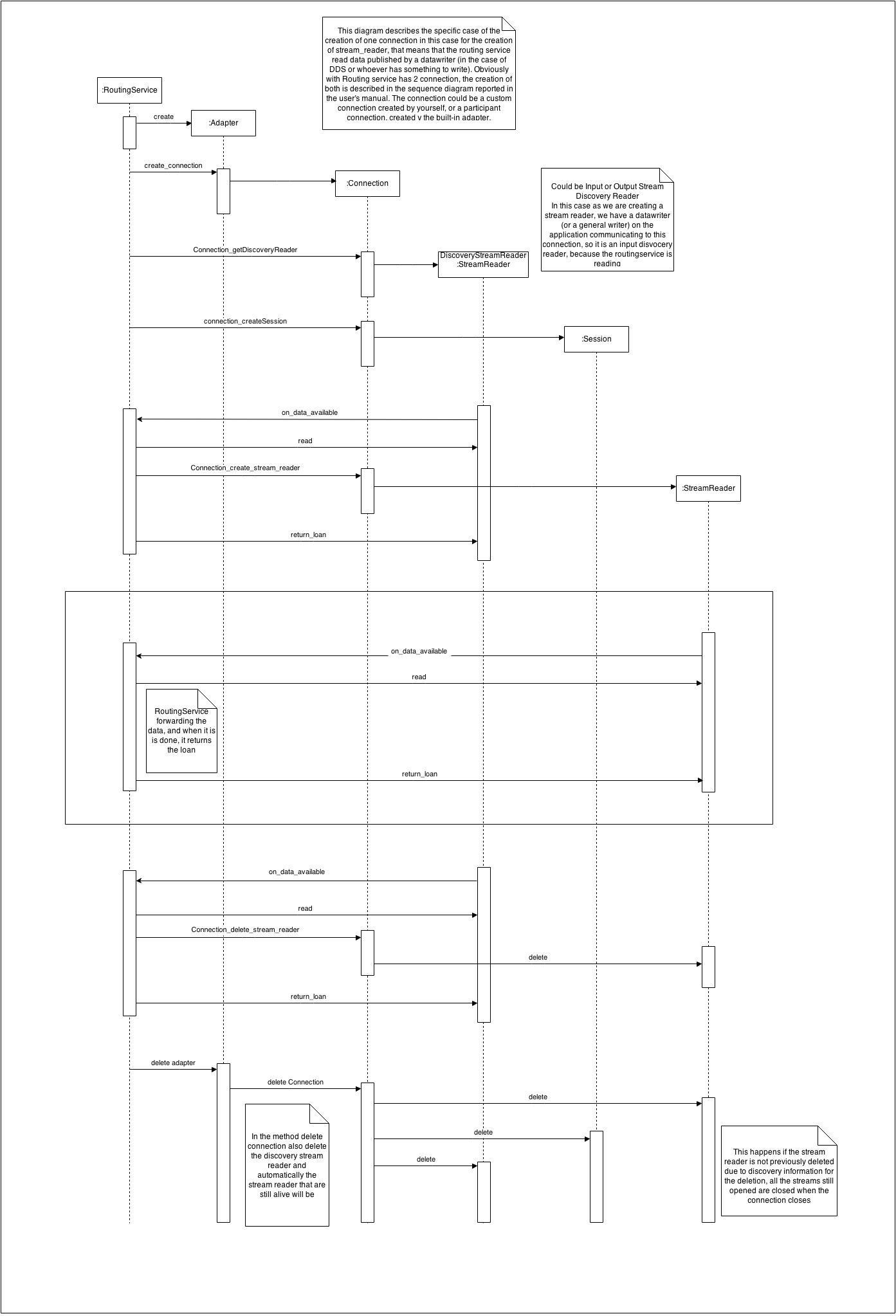
The adapter, after starting, continues scanning the directory; each time a new file appears in the reading folder, a new stream is created to send the contents of the file. Along with this document and the code, you can also find a sequence diagram that specifies in detail which functions are called and when, and after which events various entities are created or a function is called.
3.1 Creation function

Routing Service's access point into your adapter is the creation function, which is declared in the XML file when you define the link with the adapter.
In the creation function, you need to allocate the memory for the data structure and assign all the functions defined by yourself to the relative pointer defined by the structure. These are the most important functions (supported in C):
plugin_version: Not a function, just indicates the version of the pluginadapter_plugin_delete: Handles the deletion of the adapter pluginadapter_plugin_create_connection: Handles the creation of connectionsadapter_plugin_delete_connection: Handles the deletion of connectionsconnection_create_session: Handles the creation of sessionsconnection_delete_session: Handles the deletion of sessionsconnection_create_stream_reader: Handles the creation of StreamReadersconnection_delete_stream_reader: Handles the deletion of StreamReadersconnection_create_stream_writer: Handles the creation of StreamWritersconnection_delete_stream_writer: Handles the deletion of StreamWritersconnection_get_input_stream_discovery_reader: Gets the input stream discovery readerconnection_get_output_stream_discovery_reader: Gets the output stream discovery readerstream_reader_read: Reads from an input streamstream_reader_read: Reads from an input streamstream_writer_write: Writes to an output stream
In the 'create' functions: in addition to allocating memory for the data structure, you also need to initialize the data structure:
RTI_RoutingServiceAdapterPlugin_initialize(&adapter);
You should also define the version of the plugin, which is a field of the data structure. The type of this field is RTI_RoutingServiceVersion. For example:
version = {1,0,0,0};and assign it to the specific field (adapter.plugin_version).
Then proceed by assigning every function you have already defined and developed (or you will do) to the relative pointer, like this:
adapter.adapter_plugin_delete = RTI_RoutingServiceFileAdapterPlugin_delete;
All the defined functions must be specified according to the signature defined in the API documentation, here for the current release or here for release 5.1.0.
All functions must be implemented to return a specific type, that you will define (for instance createConnection returns a type of RTI_RoutingServiceConnection, create_session returns a type of RTI_RoutingServiceSession). These types are defined as void * so you can create your own data structure and use it as the return type in the RTI Routing Service Adapter API. For instance, our connection is created inside the create_connection function and the connection we define is actually RTI_RoutingServiceFileConnection defined by us. In this way, we can carry everything we need and, for instance, use it in the future. As you will see, the connection is provided as a parameter to many functions and we can use it just by making a cast to our defined type (as it is provided by the type that Routing Service knows, which is RTI_RoutingServiceConnection, defined as void *).
When you are in your code, if you want to retrieve properties that you have declared in your XML configuration file, you can use the method:
RTI_RoutingServiceProperties_lookup_property(properties, "propname");
where propname is the name of the property that you declared in the XML configuration file; properties is an input parameter to the function (in this case, the create function, but you will also have the properties object as input parameter in your create StreamWriter function, create connection, etc. The properties you will find in it will be the properties you have declared in the related section in the XML file: the properties for connection in the connection tag, for the session in the session, for the plugin_create function in the plugin declaration tag, etc.).
3.2 Creating data structures
For every entity we have in Routing Service, we need to define a data structure able to contain all the data to manage it, and that actually represents the entity. For instance, we need to define structures for the connection, for the session, for the StreamWriter and StreamReader.
The memory for these structures will be allocated, and the data structures will be created and initialized in the relative 'create' function (for instance, for the connection structure, we will create the structure and we will allocate memory for it inside the create_connection function). As we have already seen, the creation function for the adapter creates the plugin adapter and returns it; the same will happen with the connection, session, StreamReader, StreamWriter, etc. So we can put inside the structure whatever we want, since the return type of the 'create' function is defined as void * and we "cast" it to the type that we defined whenever we need it. In this way, you can have more flexibility.
Regarding the example attached with this document, we defined data structures for a Connection (struct RTI_RoutingServiceFileConnection), StreamWriter (struct RTI_RoutingServiceFileStreamWriter), and StreamReader (struct RTI_RoutingServiceFileStreamReader). We also defined one more structure that is the Adapter_plugin (struct RTI_RoutingServiceFileAdapterPlugin) defined in this way just for convenience for likely future development as it contains just the already defined by the RoutingService plugin_adapter.
The connection data structure is defined as:
struct RTI_RoutingServiceFileConnection {
char path[256];
int sleep_period
pthread_t tid;
int is_running_enabled;
struct RTI_RoutingServiceFileStreamReader * input_discovery_reader;
struct RTI_RoutingServiceStreamReaderListener input_discovery_listener;
int isInput;
};pathis the path of the directory to scan.tidis the thread identifier. The search of filenames is launched in a separate thread and we will launch just once, so we need this data just once for the connection (actually only in one connection, but we'll see how to ignore in the other connection).input_discovery_readeris a pointer to the reader for discovery information. We have just one input discovery reader for the connection. Since it is unique for every connection, we can save the reference in this structure. StreamReader for input and output discovery data, as we will see, they are normal streamreader as the ones we use to read stream data.input_discovery_listeneris the listener for the StreamReader for discovery information. It is implemented by Routing Service and passed as a parameter to the create_connection function. Note: We save the data structure listener here, NOT THE POINTER TO IT, as the created data structure is stored in the stack and will not be available after thecreate_connectionfunction is terminated, but the pointer contained into it will still be valid after.isInputtells us if we use the connection as input or output
The StreamWriter data structure is defined as:
struct RTI_RoutingServiceFileStreamWriter {
const struct RTI_RoutingServiceStreamInfo * info;
FILE * file;
int flush_enabled;
}; It contains:
infois a pointer to the structure that contains the stream info that created the stream, like name of the stream, representation, etc. We receive this structure as a parameter in the creation function.fileis a pointer to an opened file where we will write the data received in the specific stream data.flush_enabledis a property for flushing data to the file after every write; if enabled, the file won't buffer data.
The StreamReader data structure is defined as:
struct RTI_RoutingServiceFileStreamReader {
struct RTI_RoutingServiceStreamReaderListener listener;
const struct RTI_RoutingServiceStreamInfo * info;
struct DDS_TypeCode * type_code;
pthread_t tid;
int is_running_enabled;
struct DDS_Duration_t read_period;
int samples_per_read;
FILE * file;
struct RTI_RoutingServiceFileConnection * connection;
char** discovery_data;
int discovery_data_counter;
};
listeneris the listener for the StreamReader; it will be assigned here the listener passed as a parameter for the creation functioninfocontains information about the stream like the name of the stream, the type and the representation. We receive this structure as a parameter in the creation function, and we can use it to configure the stream.type_codeis the TypeCode for the dynamic data that we are forwarding (because Routing Service works with dynamic data).tidis the thread identifier. We start a new thread that periodically will notify of data available so that Routing Service will read from the file related to the StreamReader.is_running_enabledis used to enable or stop the thread.read_periodandsamples_per_readare parameters that we take from the configuration file; they are referred on how to treat the file for the reading.fileis a pointer to the file we read every time the read function gets called by Routing Service.connectionis a pointer to the connection which this StreamReader belongs to. We need it mainly to access to discovery information.discovery_data,discovery_data_counteranddiscovery_counter_readare data that we we'll use to manage discovery informations, we'll enter in the detail later.
3.3 Creation of entities
3.3.1 Creating a connection
As soon as you start Routing Service, after creating the plugin adapter, the first function inside the adapter that gets called is the create_connection.
Depending on how many connections you have declared in the XML configuration file (1 or 2), this function gets called once or twice on your adapter (because if you specify just one connection, which means to connect to a domain via a participant instead of a connection, the other gets called in the built-in adapter if you chose, it is not the case of the example). They get called sequentially, not concurrently: first the connection declared as connection_1 in the XML file, then connection_2.

The create_connection function must respect this specific signature:
RTI_RoutingServiceConnection RTI_RoutingServiceFileAdapterPlugin_create_connection(
struct RTI_RoutingServiceAdapterPlugin * adapter,
const char * routing_service_name,
const char * routing_service_group_name,
const struct RTI_RoutingServiceStreamReaderListener * output_disc_listener,
const struct RTI_RoutingServiceStreamReaderListener * input_disc_listener,
const struct RTI_RoutingServiceTypeInfo ** registeredTypes,
int registeredTypeCount,
const struct RTI_RoutingServiceProperties * properties,
RTI_RoutingServiceEnvironment * env);It returns the structure Connection, which you have already defined as RTI_RoutingServiceConnection, defined as void *.
The parameters that we receive in this function are:
- the
adapterthat creates your connection. For instance, we could store the pointer to the adapter in our connection (we don't use it). routing_service_namea string that represents the name of the name of the current instance of Routing Service (we don't use it).routing_service_group_name, a string that represents the name of the group in which Routing Service is in execution (we don't use it)output_disc_listenerand input_disc_listener are pointers to the listeners to the output discovery StreamReader and input discovery StreamReader.registeredTypesis a list of the registered types in the XML configuration file, and registeredTypeCount is a relative number in case you have defined it (In our case we didn't)- a list of the
propertiesyou have defined in the XML configuration file at the connection level (explained below) envis a pointer to the environment for the error indications.
In this function, we create the structure representing the connection. First, we allocate memory for the structure, then we proceed with the operations. We use the connection only for input or only for output, but don't be misled by that: connections are bidirectional. For instance, that's why for every connection we have both input and output discovery StreamReaders (but we use just use one connection as input, the other connection as output). Because the same function is called to create the connection on both domains, we wanted to identify the one that we were going to use as the "input" one, so in this one we defined a property in the XML configuration file that says if we use it as input or output. We retrieve that property using the utility:
RTI_RoutingServiceProperties_lookup_property(properties,"direction");
properties is the parameter received, and direction tells us if it is the input or output connection. If the direction property is not specified in the connection, we use output as the default. So we are going fill the right field in the connection structure, and in case of input we are going to start scanning the specified directory.In the XML configuration file, the expected parameters properties, are:
direction(could be input or output, could be not set; the default is output, but you should set at least one of them to input);path(the path where to read/write, could be null, but in this case it will read from the local execution folder and will write to a directory, ./filewrite. The directory must exist already.)sleepPeriod(specifies how often the thread checks the specified directory. If null, the default value is set to 5).
The directory to scan and check the files inside belongs also to the connection (more specifically to the input connection). It may also be retrieved the same way as the property direction, but in this case with the property, path. The path will be different for the input and output connections, so when the input connection gets created, it will get the path you set for the input connection (in our case, connection_1), and when the output connection gets created, it will be created with the output path (in our case, connection_2). It is better to set the value inside the XML configuration file, but in case you don't, we use a default value, which is the current execution directory "." for the input connection, and "./fwrite" for the output connection. In that case, make sure the folder exists. When you store in your structure the input or output discovery listener, be careful not to copy directly the pointer received as a parameter. It won't be valid after the scope of the function, even if it is a pointer. If you want to keep the reference to the listener, you have to save the content of this listener, not the pointer, like this:
connection->input_disc_listener = *input_disc_listener; connection->output_disc_listener = *output_disc_listener;
Another issue that requires attention when using the create_connection function is that the name of the input and output discovery listeners are inverted in the API, with respect to how they are reported in the documentation. So the correct signature is the one reported in the example and in the code snippet above, not how it appears in the documentation. (This will be fixed soon.)
3.3.2 Getting input/output discovery reader
Just after the creation of the connection, Routing Service calls the methods for getting the input and output stream discovery readers (if the functions are defined). You may notice that you are not always interested in the discovery reader, or you may not be interested in both (as in our case, we just defined the input discovery reader). For instance, in the connection that we use as output, we don't use discovery information, as we used the policy ON_ROUTE_MATCH, so we create our routes based on the discovery information of the input connection. These methods are called GET instead of CREATE, as we have just ONE discovery reader for connection.
In both functions, we create a normal StreamReader, which we use to read discovery information instead of normal data. We'll see that, for us, the discovery information is the name of the discovered file inside the directory that we are scanning. The discovery StreamReader is a normal StreamReader. Inside the function, we allocate memory for the StreamReader data structure. It could be useful to store the pointer to this StreamReader inside the connection structure. The pointer to the connection structure is passed to this function as a parameter, so we just say that this one is the discovery reader for the connection. We also need to save the pointer to the connection inside the StreamReader (so we have kind of circular pointing when the StreamReader is a discovery reader). In this way, in the StreamReader we are storing which connection it belongs to, and also which is the discovery reader for a connection. This is useful when we are going to read discovery data; we'll see how in the read function.
Here we also initialize the discovery data counter (discovery_data_counter_read) to zero; this is a counter that points to a position in an array of strings. This array is used to store discovery data, populated inside the checking thread that scans for new files. We'll see later how to use it. We created just the input discovery reader in the function get_input_discovery_reader() because we need only this in this adapter, as we don't use discovery informations in the writer side, if we did need, we had to implement also the output discovery reader in the relative function.
You'll see that since the discovery StreamReader and the data StreamReader are treated at the same way by Routing Service, they share the same read function. So when we will talk about the read function, you will see how we manage the stream data reading and the discovery data reading.
Inside the function get_input_discovery_reader() we also create the typecode. The typecode belongs to the discovery reader because we are going to use it to create the stream_info object when reading the discovery data. We create the typecode with the function defined by us:
DDS_TypeCode * RTI_RoutingServiceFileAdapter_create_type_code();
type_code field inside the data structure representing the discovery reader. 3.3.3 Creating a session and analyzing the input directory
After calling the method for getting discovery functions, Routing Service calls the method to create the session. In this example, we don't need to create a session, in fact definition of this method is optional. Sessions are very useful when we are creating an adapter to a JMS System. We also have the concept of a Session in DDS, we just don't use it now.
We are using the creation function for sessions, but we are going to make it return just the thread identifier of a new 'checking' thread that is created. Having this creation function is very useful to us (even though we don't use sessions) because we know that this function gets called after the get discovery function, and when the thread starts we need the discovery reader to be created. So we create and start the thread that is going to periodically check the input directory and notify the discovery reader when a new file appears in the folder. To do that, we start the new thread (RTI_RoutingServiceFileAdpater_checking_thread), and we pass to it as a parameter the connection data structure that already contains everything we need: the path of the directory to monitor, the pointer to the input discovery StreamReader, and the input discovery StreamReader listener.
In this way, looking at the function RTI_RoutingServiceFileAdapter_send_event() in the directory_reading.c file, you can see how the listener and listener data are used (this send_event function gets called each time the thread discovers a new file inside the directory). Inside this function we call on_data_available(). A pointer to on_data_available() is contained in the data structure input_discovery_listener. on_data_available() accepts two parameters. The first parameter is the StreamReader that it is going to be notified; it must be the input stream discovery reader in our case. The other parameter is for the listener data. Be careful: you cannot use the latter parameter for your own data, you must pass in this parameter the listener_data field contained in the input_discovery_reader structure, as you can see in this code below:
void RTI_RoutingServiceFileAdapter_send_event(char* fname, RTI_RoutingServiceFileConnection connection)
{
connection->input_disc_listener->on_data_available(
connection->discovery_reader,
connection->input_disc_listener->listener_data);
}As we cannot pass our parameter to the read function via listener data, we have to find another way to pass data. So when the thread starts we create a dynamic allocated array and copy the pointer to this parameter in the dedicated array in the discovery StreamReader (field discovery_data of the discovery_reader in the connection structure we received as a parameter).
connection->discovery_reader->discovery_data = array_files;
struct RTI_RoutingServiceFielAdapterConnection), and array_files is the dynamically allocated array. The array_files gets filled with the names of the files inside the observed folder: each time a new file appears inside the directory, the file's name will go on top of this vector. In this way, inside the discovery StreamReader we have the vector of the discovery data, which gets filled by the checking thread, and we can access it from our discovery reader. We need to do this assignment just as the new thread starts. In the discovery reader, we have a very useful index called discovery_data_counter; it says how many filename strings are contained in the array. So we have two counters in the discovery reader, one that says how many strings are contained inside the array (discovery_data_counter), another that says how many of these have already been read (discovery_data_counter_read).3.3.4 Reading discovery data
The read function that you are going to define must work for both discovery data and stream data.

This presents a problem: when on_data_available() gets called, you need a way to know if it has been called for stream data or for discovery data. We solve this in the implementation of the read function. This is why we stored the pointer to the discovery reader inside the connection data structure. Another problem is that in the read function we don't receive the pointer to the connection that the stream or discovery StreamReader belongs to. That's why we stored the pointer to the connection in the StreamReader data structure. The definition of the read function is:
void RTI_RoutingServiceFileStreamReader_read(
RTI_RoutingServiceStreamReader stream_reader,
RTI_RoutingServiceSample ** sample_list,
RTI_RoutingServiceSampleInfo ** info_list,
int * count,
RTI_RoutingServiceEnvironment * env);Where:
stream_readeris the input parameter to the data structure representing it, where the read function gets called (that could be a normal StreamReader or a discovery reader)sample_listis the output parameter that we are going to fill with read datainfo_listis an output parameter too, it is a list of information relative to the sample readcountis the number of samples we have readenvis the pointer to the Routing Service Environment, used to report error to Routing Service
When we created the discovery StreamReader, we saved in the StreamReader the pointer to the connection that created it. We also stored in the connection the pointer to the discovery reader for the connection. This is useful because we are going to compare the pointer to the StreamReader, that we received as a parameter (that is the pointer to the StreamReader where the on_data_available() function has been called) with the pointer in the connection (that is the discovery reader) and we can see if the data are available in the discovery reader.
if ((self->connection->input_discovery_reader==self)){
...
}
Where self is the pointer to the StreamReader we received as a parameter (after the cast to our defined type) that represents the StreamReader where the read function gets called. So if it recognizes itself as the discovery reader, it will read the data that we need to create StreamReader.
In this example, the discovery data are contained in the array discovery_data. We have also a disc_data_counter_read counter that tells us how many entries of this array have been read. More generally, disc_data_counter_read tells us which is the last string of the array that has been read. If there are more strings after the last entry read, it means that we have a newly discovered file that hasn't been read yet, so we have to create StreamReader for it.
A StreamReader for discovery data reads samples (which type must be of type RTI_RoutingServiceStreamInfo), so we must return them in the sample_list. To create this simple structure, we use an API called RTI_RoutingServiceStreamInfo_new_discovered(). This API creates this structure of type RTI_RoutingServiceStreamInfo, receiving as parameters: the name of the stream (in our case the name of the stream); the name of the data type that our stream will forward (in our case TextLine, which is a dynamic type created by the function createType()); the type representation kind (in our case, RTI_ROUTING_SERVICE_TYPE_REPRESENTATION_DYNAMIC_TYPE); and the typecode (in our case, the return value from the function RTI_RoutingServiceFileAdapter_create_type_code()).
In this function we need to provide the stream_info generated, and we provide them as output parameter in the sample_list dynamic array. First of all, sample_list is just a pointer to an array, so we need to allocate memory for the array. We have counted how many NEW entries we have in our discovery_data array (discovered_samples), so we allocate memory for an array of the size of the newly discovered samples. Then we fill every position in the array with the created stream info. Once Routing Service receives the stream_info samples, it automatically creates StreamReaders using the information received. So it will call create_stream_reader (because in our case, we are using the input discovery reader; if we were using the output discovery reader, we'd call create_stream_writer) for every stream info structure received.
3.3.5 Creating a stream reader
The create_stream_reader function is called to create a new StreamReader. A new StreamReader is created depending on the creation mode specified in the XML configuration file. If we specified the mode as ON_DOMAIN_MATCH, the StreamReader is created as soon as Routing Service receives discovery informations from the discovery reader we defined. Otherwise, the create_stream_reader() gets called according to the creation mode that you chose.
In our case, the discovery reader read from a file, so during the creation of the StreamReader, we get all the properties for opening the file, open the file, then prepare the structure representing the StreamReader with all the fields.
First, we have to obtain all the properties. Most of them are taken from the XML configuration file as we have already shown, properties like how often we read data from file, how to open the file, etc. But during the creation of the StreamReader, we have another source of information: the stream info.
When we read discovery data, what we deliver to Routing Service is a data structure of type struct RTI_RoutingServiceInfo which contains discovery data, in our case, information regarding typecode, and more importantly, the name of the stream. In our case, the name of the stream is the name of the file, so we will get the filename from the stream_info data structure. We will retrieve all the properties we have set in the XML configuration file and open the file with that name and with those properties. Then we save: all the properties that we have set; the filename; and more importantly, the pointer to the file in the StreamReader data structure.
The signature of the function to create a StreamReader is:
RTI_RoutingServiceStreamReader RTI_RoutingServiceFileConnection_create_stream_reader(
RTI_RoutingServiceConnection connection,
RTI_RoutingServiceSession session,
const struct RTI_RoutingServiceStreamInfo * stream_info,
const struct RTI_RoutingServiceProperties * properties,
const struct RTI_RoutingServiceStreamReaderListener * listener,
RTI_RoutingServiceEnvironment * env);Where:
connectionandsessionare, respectively, the connection and the session that the StreamReader belongs tostream_infocontains information to create the streampropertiesare the properties that we got from the configuration filelisteneris the listener for the StreamReader that we are going to createenvis the pointer to the Routing Service Environment, used to report error to Routing Service
As you can see, the listener is not created by us, but it is passed as a parameter to this function, so we store the listener to our structure. Also in this case, as in the discovery listener that we received inside the create_connection function, we cannot save the pointer to that listener, but we must copy the actual listener inside our structure.
After that, always in the creation of the StreamReader, we are going to start a new thread that is going to run, passing to it as a parameter the pointer to the StreamReader itself. Periodically, this thread will notify Routing Service that there is new data available, calling the on_data_available function of the listener that is in the StreamReader's data structure. So whenever the on_data_available function gets called, Routing Service will call the function read() on that StreamReader.
3.3.6 Reading stream data
The function read() is the same for the discovery data and stream data. So in part we have already described the function, but in this case, if it doesn't recognize the StreamReader as a discovery reader, it will read data from the normal stream.

The function's signature is the same and the purpose of the parameters are mostly the same, but the first difference is that in the sample_list parameter, we don't have to fill it with the stream_info type, we we fill it with whatever we need to. In our case, we use dynamic data since that is the best accepted representation for data in C language for Routing Service (we also declared it when creating the stream info, but we also have the XML type representation).
First of all, we have to allocate memory for the sample_list dynamic array. The size of the array is the number of the sample we want to read every read cycle, we specified that number inside the XML configuration file with the tag SamplesPerRead. So we iterate for that number of sample, we read N times from the file an amount of byte specified by MAX_PAYLOAD_SIZE in the file data_structures.h, and put the data read inside the dynamic data sample, this dynamic data sample is created according to the type code that we had previously stored inside the stream_reader data structure. Next we assign the dynamic field (in this case it is a general sequence) to the dynamic data structure and successively assign the value to the position in the array:
(*sample_list)[j++] = sample;
3.3.7 Returning the loan
The return_loan function is where you should free all the memory you have allocated (or the resources you received) in the read function. This works like it does in a DDS DataReader, which reads data, uses the data, and then returns the loan. This is true both for the discovery data and the stream data. Here we have similar behavior, so referring to our example, Routing Service calls the read function; so it reads the data, uses the data (in case of discovery, it creates the stream; in case of stream data, it forwards the samples) and then it returns the loan.
Returning of the loan is more a general concept. Here you have to implement the return loan function yourself. For instance, if your StreamReader was a DDS DataReader, inside the RTI_RoutingServiceStreamReader_return_loan you will call the return loan function for that DDS DataReader. But if we think about our example, we are reading from a file, and with the data that we have read, we create the Dynamic Data that Routing Service can understand and forward. So in the return_loan function, we free the memory that we allocated inside the read function. Basically, in the read function we allocated the memory for the sample_list and for any dynamic sample. So in this function we first delete any dynamic sample, then we free the memory for the memory allocated for the sample_list array. Instead, if it is a discovery reader, we don't have to delete the dynamic data, but we have to delete the stream info; for that, we have the utility RTI_RoutingServiceStreamInfo_delete().
The signature of the return loan function is:
void RTI_RoutingServiceFileStreamReader_return_loan(
RTI_RoutingServiceStreamReader stream_reader,
RTI_RoutingServiceSample * sample_list,
RTI_RoutingServiceSampleInfo * info_list,
int count,
RTI_RoutingServiceEnvironment * env);Where the parameters are the StreamReader where Routing Service called the read, the sample_list that we are going to free, the info_list, that are info related to the sample (we didn't use it), the number of samples (important as with it we know how many sample we have to free) and the usual parameter which is the pointer to the Routing Service environment for reporting errors.
3.3.8 Creating stream writers
What we need to say about the StreamWriter is symmetric to what happens in the create StreamReader function, regarding to when the function is created. So in our case, we want to create the StreamWriter when we have a StreamReader on the other side that can send us data, hence the policy that best suit our case is the ON_ROUTE_MATCH, but even the IMMEDIATE could be good for us.
What we are doing when we create the StreamWriter is to retrieve the properties from the XML file configuration on how to write the file (append, overwrite etc.) and the we are going to create the file for writing, the name of the file is going to be the same that we received from the stream info. Here too, we are receive a parameter which is the stream_info that tells us information about the stream, so we take the name of the stream and we use it to create the file. We also have to chose a specific path, which belongs to the output connection, and we have chosen it. Once done that, we allocate the memory for the data structure representing the data writer, we store in it the file pointer, and we return the function.
The signature of the function is:
RTI_RoutingServiceStreamWriter RTI_RoutingServiceFileConnection_create_stream_writer(
RTI_RoutingServiceConnection connection,
RTI_RoutingServiceSession session,
const struct RTI_RoutingServiceStreamInfo * stream_info,
const struct RTI_RoutingServiceProperties * properties,
RTI_RoutingServiceEnvironment * env);
Where connection and session are respectively the connection and session that the created stream_writer will belong to, stream_info are info about the stream that we have already seen, properties are the properties we have set inside the XML configuration file and env the pointer to the Routing Service environment for reporting errors.
3.3.9 Writing stream data
The function write it is called by the Routing Service when it reads data from the other connection. In this case too, the operation and the signature of the function is dual to the read ones.
The signature of the function is:
int RTI_RoutingServiceFileStreamWriter_write(
RTI_RoutingServiceStreamWriter stream_writer,
const RTI_RoutingServiceSample * sample_list,
const RTI_RoutingServiceSampleInfo * info_list,
int count,
RTI_RoutingServiceEnvironment * env);Where stream_writer is the StreamWriter where we are going to write (contains the file's pointer), sample_list is the list of sample we receive from the Routing Service, and info are the pertaining info (that we didn't use), count is the number of the sample in the list and env is the pointer to the Routing Service environment for reporting errors. So what we do here is taking sample from the sample_list, we know that they are dynamic data and we get the string contained in it, and we write them into the file. We know that it is implemented as dynamic data, but if we want to be more general when creating the StreamWriter, we get the type representation inside the stream info data structure, so we could store the type representation inside the StreamWriter data structure and act consequently.
We don't have to free memory and do anything after writing, because that samples belongs to the Routing Service, and it will take care of it. The write function has as a return type an int value, you are supposed to return the number of sample you have written. In our example we wrote everything to file, but in case, for some reasons you want write just the first N samples received to the sample list, you should notify it to Routing Service returning the number of written samples.
3.4 Deleting functions
3.4.1 Deleting stream reader and writer
3.4.2 Deleting connection and session
3.4.3 Deleting adapter
As there are creating functions for the entities that we define, we also have the respective deleting functions. The deleting functions are called in different time depending on the type of the entity. We'll see on following sections what that functions do and when they are called.

3.4.1 Deleting stream reader and writer
The delete function for StreamReader and writer, are called depending on the policy for creation mode we have chosen in the XML configuration file. We can consider this function as the opposite of the creation mode. So for instance if we have chosen ON_DOMAIN_MATCH the deletion function will be called as we receive the discovery notification of the participant (or whatever) leaving the domain, it means making the same of we did for discovery information for creating the stream, but this time, instead of creating a new discovered stream info, we will create a new disposed stream info. If the policy was ON_ROUTE_MATCH the delete function gets called as the other connection of the Routing Service disappears, and if we had IMMEDIATE that never gets called until the end of the Routing Service application. If when the whole Routing Service application terminate, there are still StreamReader or writer they gets terminated before the end of the connection and the application.
The main thing we have to do here in the deletion function is to free the memory allocated for the StreamReader, and whatever we have created for it, in our case we just clear the memory.
3.4.2 Deleting connection and session
The deletion of session, gets called before the deletion of the connection. Also in these two functions we have to clear the memory allocated for the data structures.
It is a good practice to be symmetric: if you create something in the creation function of one entity, you delete it in the respective deletion function. So as we started the thread in the create_session_function, we stop the thread here.
As the thread runs with a is_running_enabled field set as true, now we set it to false, and we call the join to the end of the thread.
If you notice, we don't have deletion function for the discovery reader (at least not known to the Routing Service adapter), so as the discovery reader belongs to the connection, when deleting the connection we also have to delete what we created for the discovery reader, in the same function, that is freeing the memory for the discovery reader.
Obviously, inside the delete_connection function, we also have to delete the memory and the resource that belongs to the connection, so in our case, we also delete the type code that we created for forwarding the data
RTI_RoutingServiceFileAdapter_delete_type_code(DDS_TypeCode * typecode);
3.4.3 Deleting the adapter
The last function that gets called is the deletion of the adapter, that is that is the main data structure, the one with the pointer to the all the functions known to the Routing Service. So when also the memory for this function has been freed, we can say that when our Routing Service is shutting down, it has done a clean shutdown.
4 Summary
Every entity (session, connection, etc.) is described by a data structure, which you define. You can put whatever you need in the structure to make it work. Our adapter, which can be only in one part of Routing Service, or in both parts, depending on if you declared the connection or the participant in the XML configuration file.
In the adapter, the first function that gets called by Routing Service is create_adapter. After that, you have the adapter that points to all the functions that you have defined. Now the adapter can create the connection(s). After creating the connections, for every connection we have to get the input discovery reader and the output discovery reader (optional). You have just one input and one output discovery reader per connection. After that, Routing Service calls the connection's function create_session (if defined, it is optional).
Once you have the infrastructure created, you need to wait for a StreamReader/Writer to be created for streaming the data. How the StreamReader/Writer gets created depends on the creation mode you chose in the route definition in the XML configuration file. The policy how the StreamReader/StreamWriter gets destroyed, is the opposite of the creation policy.
In our example, we chose to use ON_DOMAIN_MATCH on the reader side and ON_ROUTE_MATCH on the writer side. This is because, as we discover a new file, we create discovery data, and we want Routing Service to create a StreamReader. As soon as we have a StreamReader, we want Routing Service to create a StreamWriter and forward the data to it.
In a generic StreamReader, the function read() gets called by Routing Service when there's data available. Routing Service knows when data is available because you are supposed to call the function on_data_available() on the stream_reader's listener. This is true for discovery data and stream data; the listener for discovery data is provided to the create_connection() function and the listener for the stream data is provided to the create_stream_reader function(). When you call on_data_available(), Routing Service will call read() on the related stream/discovery reader where on_data_available() gets called. By checking the StreamReader's pointers, we know if Routing Service is going to read discovery data or stream data.
The type that Routing Service reads for discovery data is a special type that describes the stream to be created. Depending on how we create this object, if for a new discovered stream or for a disposed stream, Routing Service create or destroy streams.
When you stop Routing Service, the order in which it calls the deletion functions is: StreamReader/Writer, then Sessions, Connections (along with it everything related to discovery reader), and finally the adapter. Then Routing Service can smoothly shut down.

{kind=link}